TPGSR
Code for Text Prior Guided Scene Text Image Super-Resolution
Jianqi Ma, Shi Guo, Lei Zhang
Department of Computing, The Hong Kong Polytechnic University, Hong Kong, China
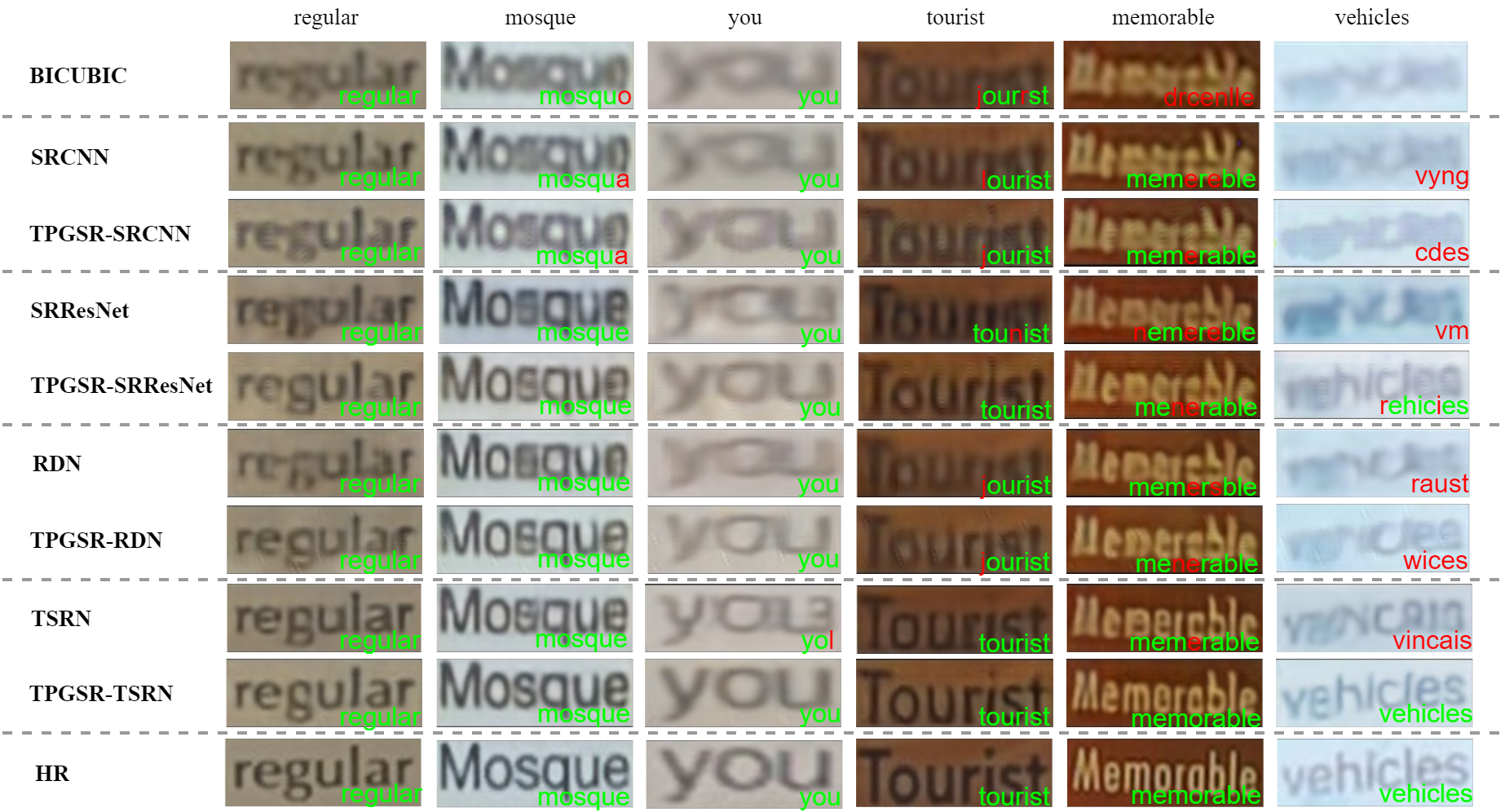
Recovering TextZoom samples
Environment:
![]()
![]()
![]()
![]()
Other possible python packages like pyyaml, cv2, Pillow and imgaug
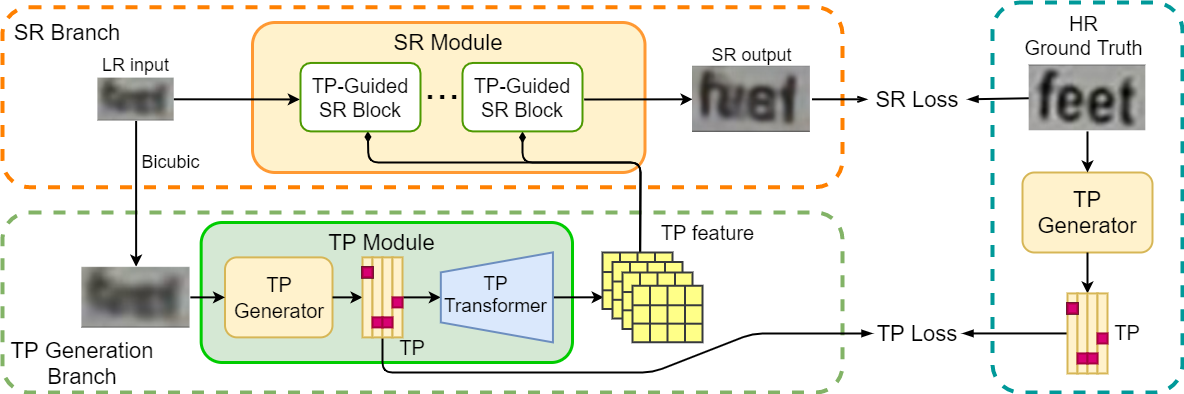
Main idea
Single stage with loss
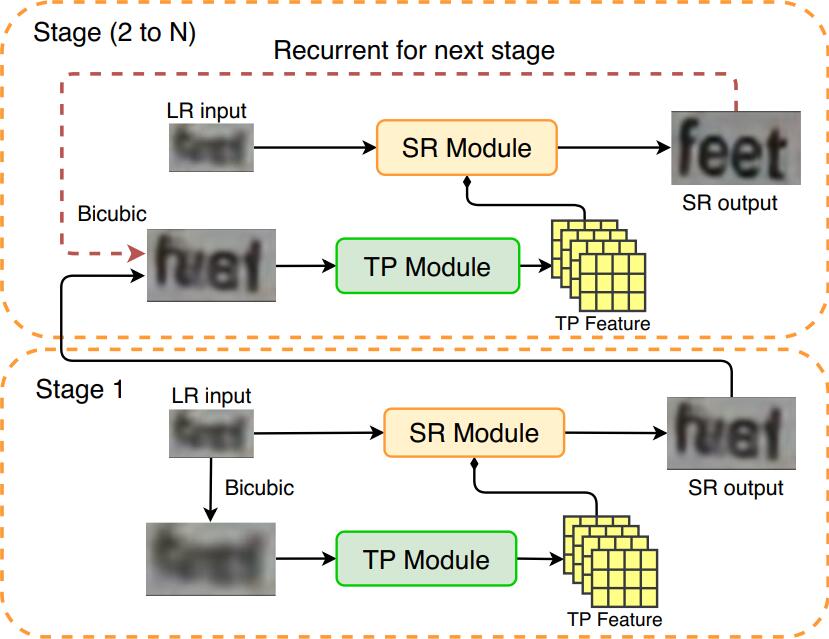
Multi-stage version
Configure your training
Download the pretrained recognizer from:
Aster: https://github.com/ayumiymk/aster.pytorch
MORAN: https://github.com/Canjie-Luo/MORAN_v2
CRNN: https://github.com/meijieru/crnn.pytorch
Unzip the codes and walk into the '$TPGSR_ROOT$/', place the pretrained weights from recognizer in '$TPGSR_ROOT$/'.
Download the TextZoom dataset:
https://github.com/JasonBoy1/TextZoom
Train the corresponding model (e.g. TPGSR-TSRN):
chmod a+x train_TPGSR-TSRN.sh
./train_TPGSR-TSRN.sh
or
python3 main.py --arch="tsrn_tl_cascade" \ # The architecture
--batch_size=48 \ # The batch size
--STN \ # Using STN net for alignment
--mask \ # Using the contour mask
--use_distill \ # Using the TP loss
--gradient \ # Using the Gradient Prior Loss
--sr_share \ # Sharing weights for SR Module
--stu_iter=1 \ # The number of interations in multi-stage version
--vis_dir='vis_TPGSR-TSRN' \ # The checkpoint directory
Run the test-prefixed shell to test the corresponding model.
Adding '--go_test' in the shell file
Cite this paper:
@article{ma2021text,
title={Text Prior Guided Scene Text Image Super-resolution},
author={Ma, Jianqi and Guo, Shi and Zhang, Lei},
journal={arXiv preprint arXiv:2106.15368},
year={2021}
}





