Pytorch GPT-X
My Own Pytorch GPT-X
1. Abstract
Train GPT-3 model on V100(16GB Mem) Using improved Transformer.
2. Model
Transformer
Additional Module
① Rezero
Rezero Is All You Need link

② Explicit Sparse Transformer
Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection link

③ Macaron Architecture
Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View link

④ RealFormer, Residual Attention
RealFormer link

Train
DeepSpeed
TODO
-
ReZero - RealFormer, Residual Attention
-
Macaron architectures -
Macaron architectures – layer Scale 0.5 -
Explicit Sparse Transformer - torch lightning
- Deepspeed train on single GPU
- Deepspeed parallel trainig on 2 V100 GPU with 16GB Memory
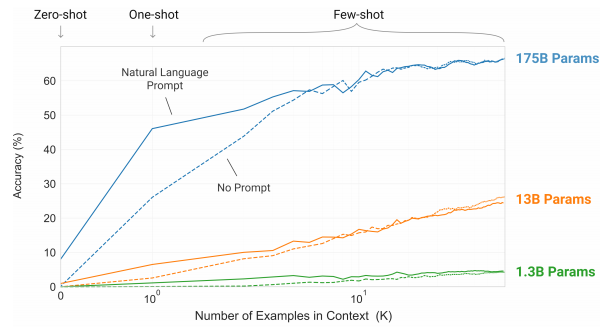
Parameter For Few-shot
The 175B parameter model is very large, but a large model is needed for Few-Shot Learning. So this repository try to use DeepSpeed for training extremely big model.
GPT-3 Config
| model_name | n_params | n_layer | d_model | n_heads | d_head | batch_size | learning_rate |
|---|---|---|---|---|---|---|---|
| GPT-3 175B | 175B | 96 | 12288 | 96 | 128 | 3.2M | 0.6 x 10^-4 |
| GPT-3 13B | 13B | 40 | 5140 | 40 | 128 | 2M | 1.0 x 10^-4 |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 | 128 | 2M | 1.2 x 10^-4 |
| GPT-3 2.7B | 2.7B | 32 | 25560 | 32 | 80 | 1M | 1.6 x 10^-4 |
References
Transformer
DeepSpeed
ReZero
Explicit Sparse Transformer
Macaron Architecrue






