FasterTransformer
This repository provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
Model overview
In NLP, encoder and decoder are two important components, with the transformer layer becoming a popular architecture for both components. FasterTransformer implements a highly optimized transformer layer for both the encoder and decoder for inference. On Volta, Turing and Ampere GPUs, the computing power of Tensor Cores are used automatically when the precision of the data and weights are FP16.
FasterTransformer v1.0 provides a highly optimized BERT equivalent Transformer layer for inference, including C++ API, TensorFlow op and TensorRT plugin. The experiments show that FasterTransformer v1 can provide 1.3 ~ 2 times speedup on NVIDIA Tesla T4 and NVIDIA Tesla V100 for inference.
In FasterTransformer v2.0, we have added a highly optimized decoder and decoding models based on OpenNMT-TF, an open-source library. Here, the decoder is the model that contains some transformer layers. On the other hand, decoding refers to the whole translating process, including the lookup embedding table, position encoding, a decoder and beam search.
In FasterTransformer v2.1, we add some important features. First one is the supporting on PyTorch. Recently, there are more and more PyTorch users. We hope the users of PyTorch can also use the FasterTransformer in their application and research. The second feature is the supporting of Effective Transformer. This idea is proposed by ByteDance. We call this feature as Effective FasterTransformer It removes the useless padding of encoder input to reduce the computing cost. Third, in addition to decoding with beam search, we also provide the decoding with sampling module. Finally, we optimize many kernels of encoder, decoder and beam search to improve the speed of FasterTransformer.
In FasterTransformer v3.0, we implemented the INT8 quantization for encoder (also supporting Effective FasterTransformer). With INT8 quantization, we can take advantage of the powerful INT8 tensor core in Turing GPU to achieve better inference performance (INT8 quantization in FT 3.0 is only supported on device with SM >= 7.5). We also provide quantization tools of tensorflow.
In FasterTransformer v3.1, we provide following new features and enhancements. First, we optimize the INT8 kernel of encoder to achieve better performance. Compare to FasterTransformer v3.0, the performance of INT8 quantization brings at most 1.75x speedup. Second, we provide a PyTorch tool to let user be able to train a INT8 quantized model on PyTorch. Besides, FasterTransformer also starts to support the INT8 inference with PyTorch op. So, the users of PyTorch can leverage the INT8 inference. Third, we integrate the fused multi-head attention kernel of TensorRT plugin into FasterTransformer to improve the speed of encoder on Turing and new GPUs. This optimization can bring about 10% ~ 20% speedup compare to original implementation. Finally, we add the supporting of GPT-2 model, which is an important and popular model for decoder.
In FasterTransformer v4.0, we provide the multi-nodes multi-gpu inference for GPT model. Compare to usual framework to train giant model like Megatron, FasterTransformer provides 1.2x ~ 3x speedup. Besides, integrating the INT8 fused multi-head attention kernel of TensorRT plugin to further improve the performance of FasterTransformer encoder on INT8. We also add supporting of FP16 fused multi-head attention kernel for V100. Finally, we optimize the decoding module. Compare to v3.1, v4.0 provides at most 2x speedup.
The following graph demonstrates the model architecture.
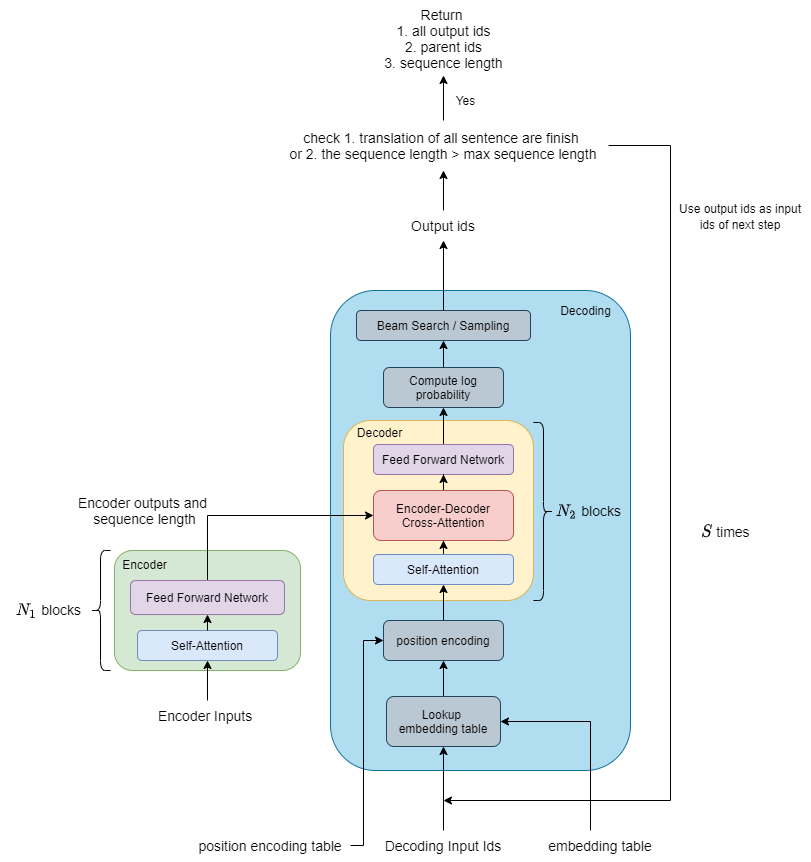
FasterTransformer is built on top of CUDA, cuBLAS and cuBLASLt, providing the C++ API and TensorFlow/PyTorch OPs. Users can integrate them into TensorFlow, PyTorch, or other inference service codes that are built in native C++. We also provide some simple sample code to demonstrate how to use the encoder, decoder and to carry out decoding in C++, TensorFlow and PyTorch.
More details are in docs/encoder_guide.md, docs/decoder_guide.md and docs/gpt_guide.md. Some common questions and the respective answers are put in docs/QAList.md
Support matrix
The following matrix shows the architecture differences between the model.
| Architecure | Encoder | Encoder INT8 quantization |
Decoder | Decoding with beam search |
Decoding with sampling |
GPT-2 | GPT-3 |
|---|---|---|---|---|---|---|---|
| v1 | Yes | No | No | No | No | No | No |
| v2 | Yes | No | Yes | Yes | No | No | No |
| v2.1 | Yes | No | Yes | Yes | Yes | No | No |
| v3.0 | Yes | Yes | Yes | Yes | Yes | No | No |
| v3.1 | Yes | Yes | Yes | Yes | Yes | Yes | No |
| v4.0 | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
Setup
The following section lists the requirements to use FasterTransformer.
Requirements
- CMake >= 3.8 for Tensorflow, CMake >= 3.13 for PyTorch
- CUDA 10.1 or newer version
- Python 3 is recommended because some features are not supported in python 2
- Tensorflow 1.13 or 1.14 or 1.15
- PyTorch >= 1.5.0
These components are readily available within the NGC TensorFlow/PyTorch Docker image below.
Ensure you have the following components:
- NVIDIA Docker and NGC container are recommended
- NVIDIA Pascal or Volta or Turing or Ampere based GPU
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running TensorFlow
- Running PyTorch
For those unable to use the NGC container, to set up the required environment or create your own container, see the versioned NVIDIA Container Support Matrix.
Quick Start Guide
The following section shows how to use FasterTransformer on the NGC container.
Build the FasterTransformer
-
Run the container.
You can choose the tensorflow version and python version you want. Here, we list some possible images:
nvcr.io/nvidia/tensorflow:19.07-py2contains the TensorFlow 1.14 and python 2.7.nvcr.io/nvidia/tensorflow:20.12-tf1-py3contains the TensorFlow 1.15 and python 3.8.nvcr.io/nvidia/pytorch:20.03-py3contains the PyTorch 1.5.0 and python 3.6nvcr.io/nvidia/pytorch:20.07-py3contains the PyTorch 1.6.0 and python 3.6nvcr.io/nvidia/pytorch:20.12-py3contains the PyTorch 1.8.0 and python 3.8
To achieve best performance, we recommand to use the latest image. For example, running image
nvcr.io/nvidia/tensorflow:20.12-tf1-py3bynvidia-docker run -ti --rm nvcr.io/nvidia/tensorflow:20.12-tf1-py3 bash -
Clone the repository.
git clone https://github.com/NVIDIA/FasterTransformer.git cd FasterTransformer mkdir -p build cd build -
Build the project.
3.1 build with C++
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release .. makeNote:
xxis the compute capability of your GPU. For example, 60 (P40) or 61 (P4) or 70 (V100) or 75(T4) or 80 (A100).3.2 build with TensorFlow
Uses need to set the path of TensorFlow. For example, if we use
nvcr.io/nvidia/tensorflow:20.12-tf1-py3, thencmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_TF=ON -DTF_PATH=/usr/local/lib/python3.8/dist-packages/tensorflow_core/ .. makeNote:
xxis the compute capability of your GPU. For example, 60 (P40) or 61 (P4) or 70 (V100) or 75(T4) or 80 (A100).3.3 build with PyTorch
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON .. makeNote:
xxis the compute capability of your GPU. For example, 60 (P40) or 61 (P4) or 70 (V100) or 75(T4) or 80 (A100).This will build the TorchScript custom class. Please make sure that the
PyTorch >= 1.5.0.Note: From
FasterTransformer 3.1, TorchScript custom op (function type) is deprecated. FromFasterTransformer 4.0, Eager mode PyTorch extension is deprecated.
Execute the encoder demos
-
Run FasterTransformer encoder on C++
./bin/encoder_gemm <batch_size> <sequence_length> <head_number> <size_per_head> <is_use_fp16> <int8_mode> ./bin/encoder_sample <batch_size> <num_layers> <sequence_length> <head_number> <size_per_head> <is_use_fp16> <is_remove_padding> <int8_mode> <allow_gemm_test>1.1 Run FasterTransformer encoder under FP32 on C++
./bin/encoder_gemm 32 32 12 64 0 0 ./bin/encoder_sample 32 12 32 12 64 0 0 0 01.2 Run FasterTransformer encoder under FP16 on C++
./bin/encoder_gemm 32 32 12 64 1 0 ./bin/encoder_sample 32 12 32 12 64 1 0 0 01.3 Run FasterTransformer encoder under INT8 on C++
We implement two INT8 pipelines. For int8_mode == 1 (int8v1), we don't quantize residual connection, use int32 as the output of int8 gemms and use per-channel quantization for weights; for int8_mode == 2 (int8v2), we quantize residual connection, use int8 as the output of int8 gemms and use per-tensor quantization for weights. Generally speaking, int8_mode == 1 will have higher accuracy while int8_mode == 2 will have better performance.
feature int8_mode == 1 int8_mode == 2 quantize residual No Yes int8 output gemm No Yes per-channel quantiztion for weights Yes No #For int8_mode == 1 ./bin/encoder_gemm 32 32 12 64 1 1 ./bin/encoder_sample 32 12 32 12 64 1 0 1 0 #For int8_mode == 2 ./bin/encoder_gemm 32 32 12 64 1 2 ./bin/encoder_sample 32 12 32 12 64 1 0 2 01.4 Run Effective FasterTransformer under FP32 on C++
./bin/encoder_gemm 32 32 12 64 0 0 ./bin/encoder_sample 32 12 32 12 64 0 1 0 01.5 Run Effective FasterTransformer under INT8 on C++
#For int8_mode == 1 ./bin/encoder_gemm 32 32 12 64 1 1 ./bin/encoder_sample 32 12 32 12 64 1 1 1 0 #For int8_mode == 2 ./bin/encoder_gemm 32 32 12 64 1 2 ./bin/encoder_sample 32 12 32 12 64 1 1 2 0 -
Run FasterTransformer encoder on TensorFlow
2.1 Run FasterTransformer encoder under FP32 on TensorFlow
./bin/encoder_gemm 32 32 12 64 0 0 python tensorflow/encoder_sample.py \ --batch_size 32 \ --max_seq_len 32 \ --head_number 12 \ --size_per_head 64 \ --num_layer 12 \ --data_type fp32 \ --test_time 1 \ --allow_gemm_test FalseIf use sets
--test_time 1, the program will show the performance of TensorFlow, FasterTransformer and FasterTransformer with removing padding.2.2 Run FasterTransformer encoder under FP16 on TensorFlow
./bin/encoder_gemm 32 32 12 64 1 0 python tensorflow/encoder_sample.py \ --batch_size 32 \ --max_seq_len 32 \ --head_number 12 \ --size_per_head 64 \ --num_layer 12 \ --data_type fp16 \ --test_time 1 \ --allow_gemm_test False2.3 Run FasterTransformer encoder under INT8 on TensorFlow
#For int8_mode == 1 ./bin/encoder_gemm 32 32 12 64 1 1 python tensorflow/encoder_sample.py \ --batch_size 32 \ --max_seq_len 32 \ --head_number 12 \ --size_per_head 64 \ --num_layer 12 \ --data_type fp16 \ --test_time 1 \ --int8_mode 1 \ --allow_gemm_test False #For int8_mode == 2 ./bin/encoder_gemm 32 32 12 64 1 2 python tensorflow/encoder_sample.py \ --batch_size 32 \ --max_seq_len 32 \ --head_number 12 \ --size_per_head 64 \ --num_layer 12 \ --data_type fp16 \ --test_time 1 \ --int8_mode 2 \ --allow_gemm_test False -
Run FasterTransformer on PyTorch
Please install HuggingFace's
transformersfirst before run the demos bypip install transformers==2.5.13.1 Run FasterTransformer encoder under FP32 on PyTorch
./bin/encoder_gemm 32 32 12 64 0 0 python pytorch/encoder_sample.py 32 12 32 12 64 --time3.2 Run FasterTransformer encoder under FP16 on PyTorch
./bin/encoder_gemm 32 32 12 64 1 0 python pytorch/encoder_sample.py 32 12 32 12 64 --fp16 --time3.3 Run FasterTransformer encoder under INT8 on PyTorch
#For int8_mode == 1 ./bin/encoder_gemm 32 32 12 64 1 1 python pytorch/encoder_sample.py 32 12 32 12 64 --int8_mode 1 --time #For int8_mode == 2 ./bin/encoder_gemm 32 32 12 64 1 2 python pytorch/encoder_sample.py 32 12 32 12 64 --int8_mode 2 --time
Execute the decoder/decoding demos
-
Run FasterTransformer decoding on C++
./bin/decoding_gemm <batch_size> <beam_width> <head_number> <size_per_head> <vocab_size> <sequence_length> <encoder_hidden_dim> <is_use_fp16> ./bin/decoding_beamsearch_sample <batch_size> <beam_width> <head_number> <size_per_head> <vocab_size> <sequence_length> <num_layers> <encoder_hidden_dim> <is_use_fp16> ./bin/decoding_sampling_sample <batch_size> <candidate_num> <probability_threshold> <head_number> <size_per_head> <vocab_size> <sequence_length> <num_layers> <encoder_hidden_dim> <is_use_fp16>1.1 Run decoding under FP32 on C++
./bin/decoding_gemm 32 4 8 64 30000 32 512 0 ./bin/decoding_beamsearch_sample 32 4 8 64 30000 32 6 512 0 # beam search ./bin/decoding_gemm 32 1 8 64 30000 32 512 0 ./bin/decoding_sampling_sample 32 4 0.0 8 64 30000 32 6 512 0 # top k sampling ./bin/decoding_sampling_sample 32 0 0.01 8 64 30000 32 6 512 0 # top p sampling1.2 Run decoding under FP16 on C++
./bin/decoding_gemm 32 4 8 64 30000 32 512 1 ./bin/decoding_beamsearch_sample 32 4 8 64 30000 32 6 512 1 # beam search ./bin/decoding_gemm 32 1 8 64 30000 32 512 1 ./bin/decoding_sampling_sample 32 4 0.0 8 64 30000 32 6 512 1 # top k sampling ./bin/decoding_sampling_sample 32 0 0.01 8 64 30000 32 6 512 1 # top p sampling -
Run FasterTransformer decoder/decoding on TensorFlow
2.1 Run FasterTransformer decoder under FP32 on TensorFlow
2.1.1 Verify the correctness
./bin/decoding_gemm 32 4 8 64 30000 32 512 0 python tensorflow/decoder_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp32 \ --decoder_type 22.1.2 Test time of TensorFlow decoder
python tensorflow/decoder_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp32 \ --decoder_type 0 \ --test_time 12.1.3 Test time of FasterTransformer decoder
./bin/decoding_gemm 32 4 8 64 30000 32 512 0 python tensorflow/decoder_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp32 \ --decoder_type 1 \ --test_time 12.2 Run FasterTransformer decoder under FP16 on TensorFlow
./bin/decoding_gemm 32 4 8 64 30000 32 512 1 python tensorflow/decoder_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp16 \ --decoder_type 22.3 Run FasterTransformer decoding under FP32 on TensorFlow
./bin/decoding_gemm 32 4 8 64 30000 32 512 0 python tensorflow/decoding_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp32 \ --beam_search_diversity_rate -1.3 \ --sampling_topk 0 \ --sampling_topp 0.01 \ --test_time 01232.4 Run FasterTransformer decoding under FP16 on TensorFlow
./bin/decoding_gemm 32 4 8 64 30000 32 512 1 python tensorflow/decoding_sample.py \ --batch_size 32 \ --beam_width 4 \ --head_number 8 \ --size_per_head 64 \ --vocab_size 30000 \ --max_seq_len 32 \ --num_layer 6 \ --memory_hidden_dim 512 \ --data_type fp16 \ --beam_search_diversity_rate -1.3 \ --sampling_topk 0 \ --sampling_topp 0.01 \ --test_time 0123 -
Run FasterTransformer decoder/decoding on PyTorch
Please install OpenNMT-py first before running the demos by
pip install opennmt-py==1.1.13.1 Run FasterTransformer decoder under FP32 on PyTorch
./bin/decoding_gemm 8 4 8 64 31538 32 512 0 python pytorch/decoder_sample.py 8 6 32 8 64 --time3.2 Run FasterTransformer decoder under FP16 on PyTorch
./bin/decoding_gemm 8 4 8 64 31538 32 512 1 python pytorch/decoder_sample.py 8 6 32 8 64 --fp16 --time3.3 Run FasterTransformer decoding under FP32 on PyTorch
./bin/decoding_gemm 8 4 8 64 31538 32 512 0 python pytorch/decoding_sample.py 8 6 32 8 64 4 31538 --time3.4 Run FasterTransformer decoding under FP16 on PyTorch
./bin/decoding_gemm 8 4 8 64 31538 32 512 1 python pytorch/decoding_sample.py 8 6 32 8 64 4 31538 --fp16 --time
Translation demos
-
Translation with FasterTransformer on TensorFlow
1.1 Prepare data and model
bash tensorflow/utils/translation/download_model_data.sh1.2 Run under FP32
./bin/decoding_gemm 128 4 8 64 32001 100 512 0 python tensorflow/translate_sample.py \ --batch_size 128 \ --beam_width 4 \ --encoder_head_number 8 \ --encoder_size_per_head 64 \ --decoder_head_number 8 \ --decoder_size_per_head 64 \ --max_seq_len 32 \ --encoder_num_layer 6 \ --decoder_num_layer 6 \ --data_type fp32 \ --beam_search_diversity_rate 0.0 \ --sampling_topk 1 \ --sampling_topp 0.00 \ --test_time 0123451.3 Run under FP16
python tensorflow/tensorflow_bert/ckpt_type_convert.py --init_checkpoint=translation/ckpt/model.ckpt-500000 --fp16_checkpoint=translation/ckpt/fp16_model.ckpt-500000 ./bin/decoding_gemm 128 4 8 64 32001 100 512 1 python tensorflow/translate_sample.py \ --batch_size 128 \ --beam_width 4 \ --encoder_head_number 8 \ --encoder_size_per_head 64 \ --decoder_head_number 8 \ --decoder_size_per_head 64 \ --max_seq_len 32 \ --encoder_num_layer 6 \ --decoder_num_layer 6 \ --data_type fp16 \ --beam_search_diversity_rate 0.0 \ --sampling_topk 1 \ --sampling_topp 0.00 \ --test_time 012345 -
Translation with FasterTransformer on PyTorch
2.1 Prepare model and data
bash pytorch/scripts/download_translation_model.sh2.2 Run under FP32
./bin/decoding_gemm 128 4 8 64 31538 100 512 0 python pytorch/run_translation.py --batch_size 128 --beam_size 4 --model_type decoding_ext --data_type fp322.3 Run under FP16
./bin/decoding_gemm 128 4 8 64 31538 100 512 1 python pytorch/run_translation.py --batch_size 128 --beam_size 4 --model_type decoding_ext --data_type fp16
GPT demo
Here, we demonstrate how to run Fastertransformer on Megatron model with C++ and PyTorch api. More details are in docs/gpt_guide.md.
- Prepare
pip install -r ../requirement.txt
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json -P models
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt -P models
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
mkdir -p models/megatron-models/345m
unzip megatron_lm_345m_v0.0.zip -d models/megatron-models/345m
git clone https://github.com/NVIDIA/Megatron-LM.git
python ../sample/pytorch/utils/megatron_ckpt_convert.py -i ./models/megatron-models/345m/release/ -o ./models/megatron-models/c-model/345m/ -t_g 1 -i_g 1
Note that there are different checkpoint version of Megatron. The version of the checkpoint above is 0. If users have trained a model by themselves, the default version of latest Megatron is 3. To convert the checkpoint with version 3, please add -checkpoint_version 3.
-
Run GPT
2.1 Run on C++
Users can see the details of arguments in
sample/cpp/gpt_config.ini. It controls the model path, model size, tensor parallelism size, and some hyper-parameters. And then run gpt by following script:./bin/gpt_sample python ../sample/pytorch/utils/convert_gpt_token.py --vocab_file=./models/gpt2-vocab.json --bpe_file=./models/gpt2-merges.txtThe following script run multi-gpus (Note that users need to modify the
gpt_config.ini. For example, settensor_para_sizeto 8.)mpirun -n 8 ./bin/gpt_sample python ../sample/pytorch/utils/convert_gpt_token.py --vocab_file=./models/gpt2-vocab.json --bpe_file=./models/gpt2-merges.txt2.2 Run on Pytorch
# No parallelism (tensor_para_size=1, layer_para_size=1) mpirun -n 1 --allow-run-as-root python ./pytorch/gpt_sample.py # TP (tensor_para_size=8, layer_para_size=1) mpirun -n 8 --allow-run-as-root python ./pytorch/gpt_sample.py --tensor_para_size=8 --layer_para_size=1 --ckpt_path="/workspace/fastertransformer/models/megatron-models/c-model/345m/8-gpu"
Advanced
The following sections provide greater details.
Scripts and sample codes
The following code lists the directory structure of FasterTransformer:
/fastertransformer: source code of transformer
|--/cuda: some CUDA kernels and multi-head attention implementation, both are compiled with cuda/cuBLAS/cuBLASLt.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/trt_fused_multihead_attention: fused multihead attention kernels of TensorRT
/sample: C++ and tensorflow transformer interface samples
|--/cpp: C++ interface samples
|--/pytorch: PyTorch OP samples
|--/tensorflow: TensorFlow OP samples
|--/tensorflow_bert: samples that show of how to integrate our Tensorflow OP into the open source BERT model for sentence (and sentence-pair) classification tasks (GLUE), the samples support both FP16 and FP32, see readme file within this folder more details
/tools/gemm_test: loop over all GEMM algorithms to pick the best one
/bert-quantization/
|--bert-tf-quantization: TensorFlow quantization tool and sample codes
|--bert-pyt-quantization/: PyTorch quantization sample codes
/docs/
In the root directory of FasterTransformer, the most important directories are:
fastertransformer/sample/tools/bert-quantization/docs/
The fastertransformer/ folder encapsulates all the source codes of FasterTransformer:
tf_op/- Contains the TensorFlow Op source files of encoder, decoder and decodingth_op/- Contains the PyTorch Op source files of encoder, decoder and decodingcuda/- Contains all CUDA kernels of FasterTransformerbert_encoder_transformer.h- Contains the encoder transformer layeropen_decoder.h- Contains the decoder transformer layerdecoding_beamsearch.h- Contains the progress of decoding with beam searchdecoding_sampling.h- Contains the progress of decoding with beam searchgpt.h- Contains the progress of GPT
The tools/ folder contains the tools to generate the GEMM configuration of FasterTransformer for different settings:
tools/gemm_test/encoder_gemm.cc- Encoder GEMM configtools/gemm_test/decoding_gemm.cc- Decoder and decoding GEMM config
The sample/ folder contains useful sample codes for FasterTransformer:
sample/cpp/encoder_sample.cc- C encoder sample codessample/cpp/decoding_beamsearch_sample.cc- C decoding with beam search sample codessample/cpp/decoding_sampling_sample.cc- C decoding with sampling sample codessample/cpp/gpt_sample.cc- C GPT codessample/tensorflow/encoder_sample.py- TensorFlow encoder sample codessample/tensorflow/decoder_sample.py- TensorFlow decoder sample codessample/tensorflow/decoding_sample.py- TensorFlow decoding sample codessample/tensorflow/tensorflow_bert/- TensorFlow using FasterTransformer in BERT sample codessample/tensorflow/translate_sample.py- TensorFlow translation sample codessample/tensorflow/gpt_sample.py- TensorFlow GPT sample codessample/pytorch/encoder_sample.py- PyTorch encoder sample codessample/pytorch/decoder_sample.py- PyTorch decoder sample codessample/pytorch/decoding_sample.py- PyTorch decoding sample codessample/pytorch/run_glue.py- PyTorch BERT on GLUE dataset sample codessample/pytorch/run_squad.py- PyTorch BERT on SQuAD dataset sample codessample/pytorch/run_translation.py- PyTorch decoding for translation sample codes
Command-line options
To see the full list of available options and their descriptions, use the -h or --help command-line option with the Python file, for example:
python tensorflow/encoder_sample.py --help
python tensorflow/decoder_sample.py --help
python tensorflow/decoding_sample.py --help
python tensorflow/translate_sample.py --help
Inference process
This subsection provides the details about how to use the encoder, the decoder and the decoding.
Performance
Hardware settings:
- 8xA100-80GBs (with mclk 1593MHz, pclk 1410MHz) with AMD EPYC 7742 64-Core Processor
- T4 (with mclk 5000MHz, pclk 1590MHz) with Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
In order to run the following benchmark, we need to install the unix computing tool "bc" by
apt-get install bc
Encoder performance
The FP16 results of TensorFlow were obtained by running the sample/tensorflow/scripts/profile_encoder_performance.sh.
The INT8 results of TensorFlow were obtained by running the sample/tensorflow/scripts/profile_encoder_performance_int8.sh.
The FP16 results of PyTorch were obtained by running the sample/pytorch/scripts/profile_encoder.sh.
The INT8 results of PyTorch were obtained by running the sample/pytorch/scripts/profile_encoder_int8.sh.
In the experiments of encoder, we updated the following parameters:
- head_num = 12
- size_per_head = 64
- num_layers = 12
More benchmarks are put in docs/encoder_guide.md.
Encoder performances of FasterTransformer new features
The following figure compares the performances of different features of FasterTransformer and FasterTransformer under FP16 on T4.
For large batch size and sequence length, both EFF-FT and FT-INT8-v2 bring about 2x speedup. Using Effective FasterTransformer and int8v2 at the same time can bring about 3.5x speedup compared to FasterTransformer FP16 for large case.
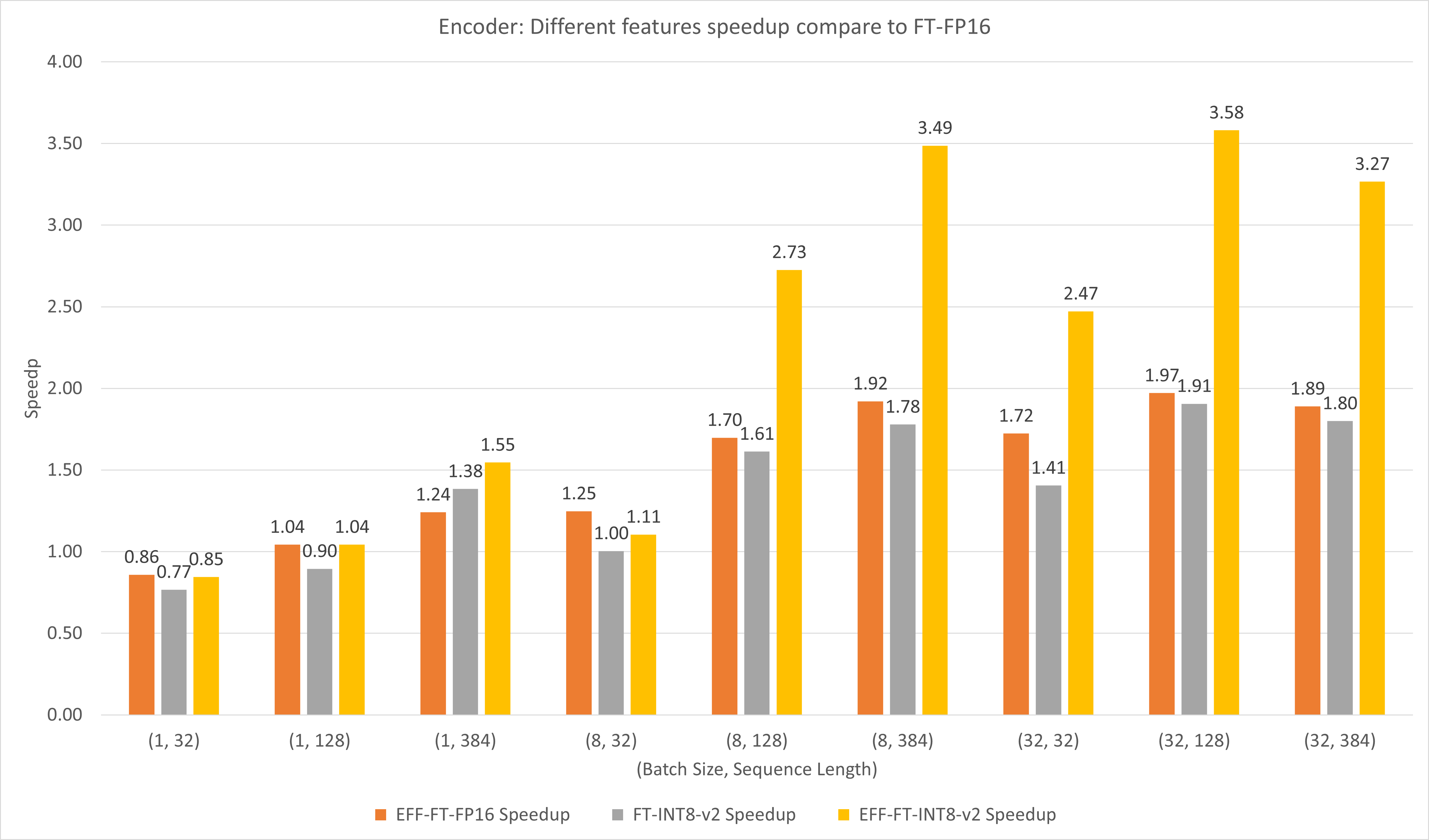
Encoder performance on TensorFlow
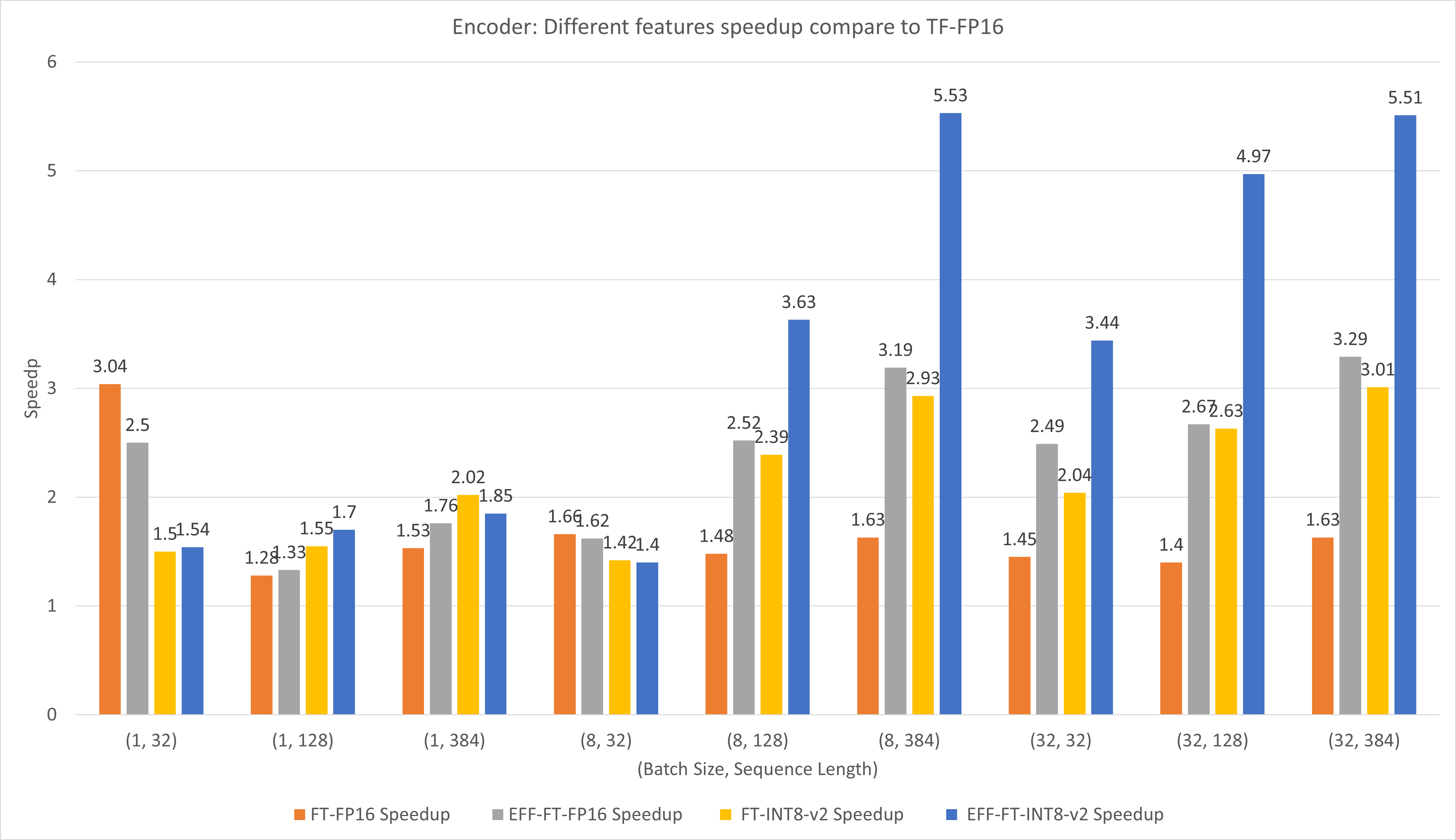
The following figure compares the performances of different features of FasterTransformer and TensorFlow XLA under FP16 on T4.
For small batch size and sequence length, using FasterTransformer can bring about 3x speedup.
For large batch size and sequence length, using Effective FasterTransformer with INT8-v2 quantization can bring about 5x speedup.
Encoder performance on PyTorch
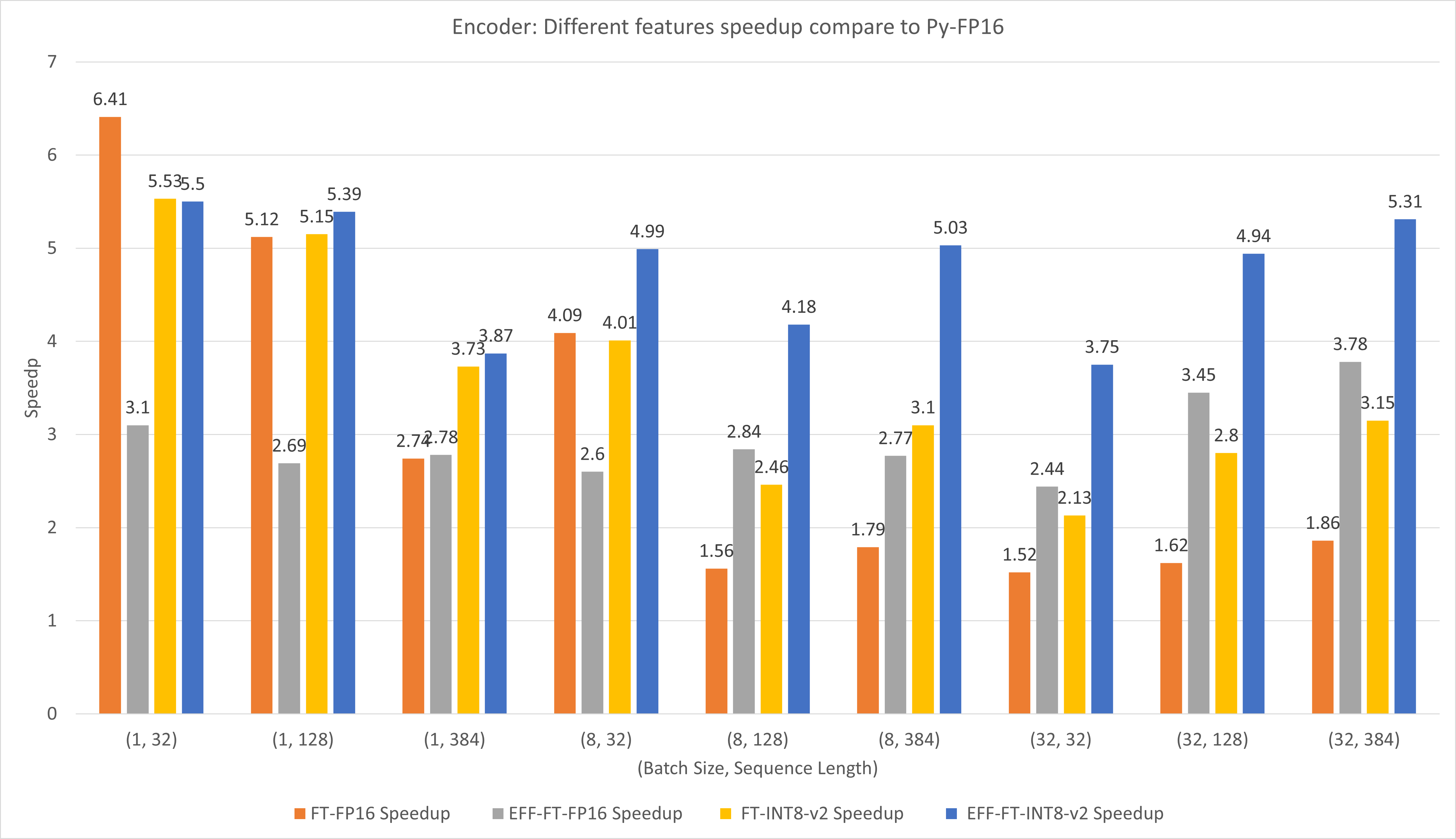
The following figure compares the performances of different features of FasterTransformer and PyTorch TorchScript under FP16 on T4.
For small batch size and sequence length, using FasterTransformer CustomExt can bring about 4x ~ 6x speedup.
For large batch size and sequence length, using Effective FasterTransformer with INT8-v2 quantization can bring about 5x speedup.
Decoding and Decoder performance
The results of TensorFlow were obtained by running the profile_decoding_beamsearch_performance.sh and profile_decoding_sampling_performance.sh
The results of PyTorch were obtained by running the profile_decoder_decoding.sh.
In the experiments of decoding, we updated the following parameters:
- head_num = 8
- size_per_head = 64
- num_layers = 6 for both encoder and decoder
- vocabulary_size = 30000 for TensorFlow sample codes, 31538 for PyTorch sample codes
- memory_hidden_dim = 512
- max sequenc elength = 128
More benchmarks are put in docs/decoder_guide.md.
Decoder and Decoding end-to-end translation performance on TensorFlow
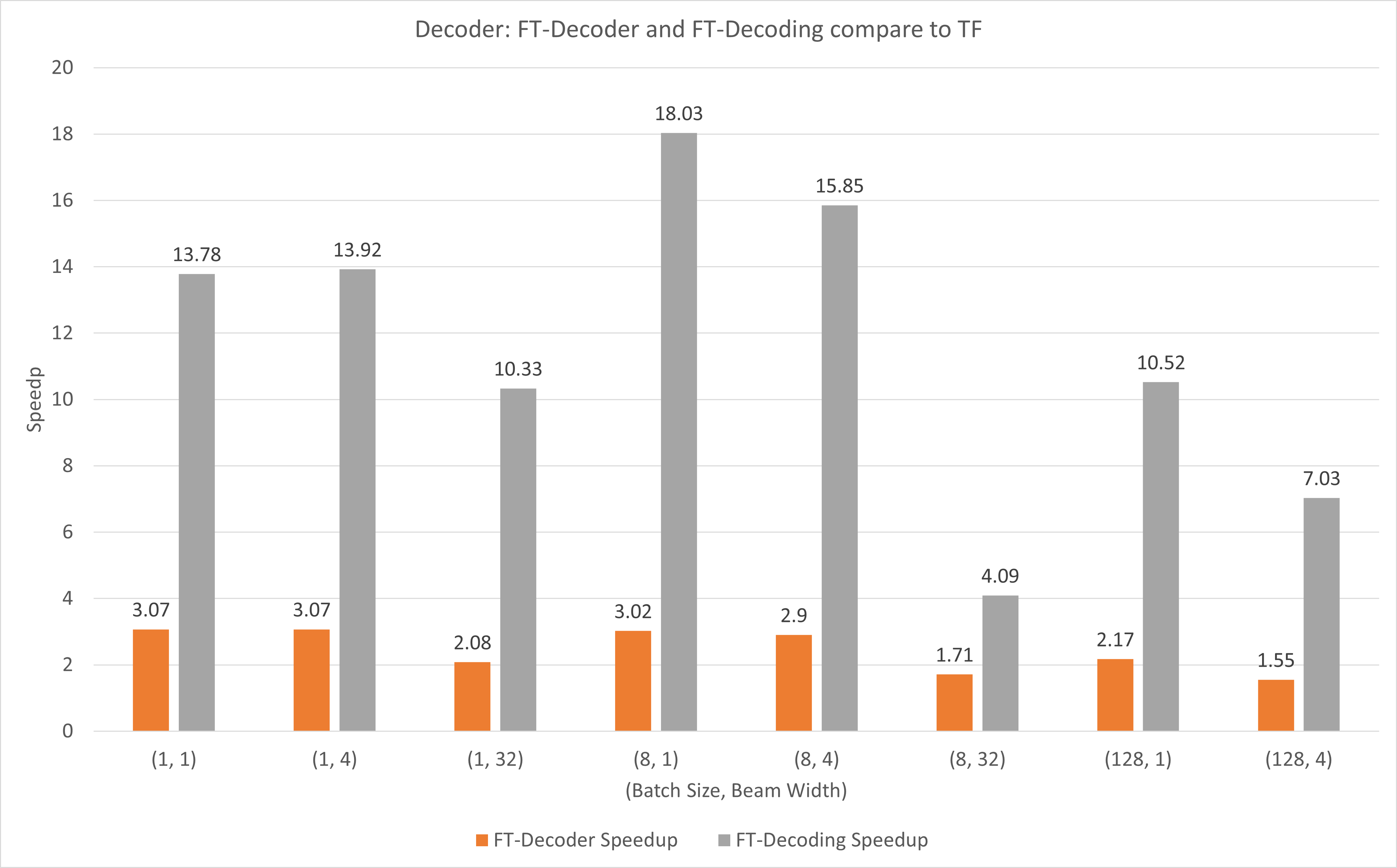
The following figure shows the speedup of of FT-Decoder op and FT-Decoding op compared to TensorFlow under FP16 with T4. Here, we use the throughput of translating a test set to prevent the total tokens of each methods may be different. Compared to TensorFlow, FT-Decoder provides 1.5x ~ 3x speedup; while FT-Decoding provides 4x ~ 18x speedup.
Decoder and Decoding end-to-end translation performance on PyTorch
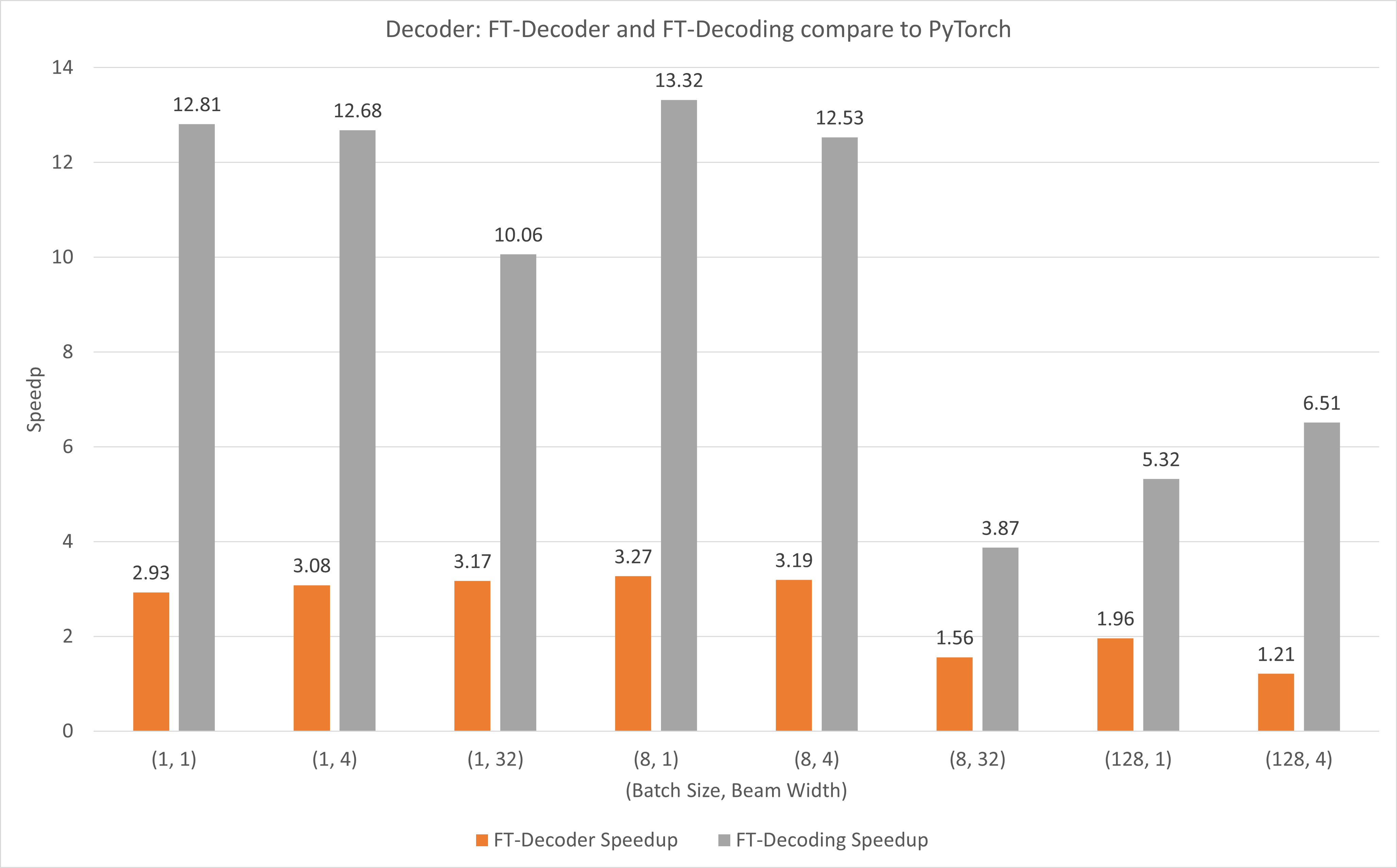
The following figure shows the speedup of of FT-Decoder op and FT-Decoding op compared to PyTorch under FP16 with T4. Here, we use the throughput of translating a test set to prevent the total tokens of each methods may be different. Compared to PyTorch, FT-Decoder provides 1.2x ~ 3x speedup; while FT-Decoding provides 3.8x ~ 13x speedup.
GPT performance
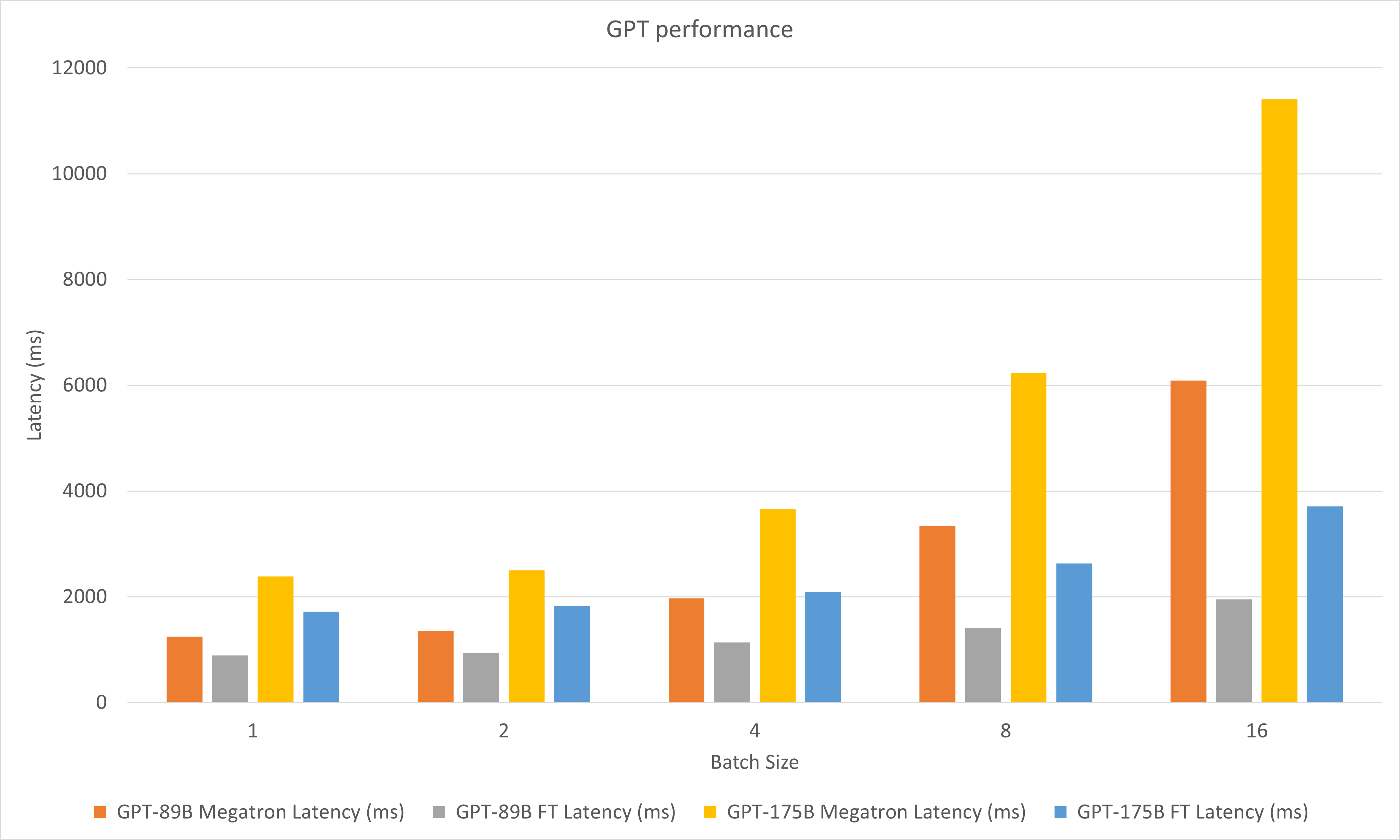
The following figure compares the performances of Megatron and FasterTransformer under FP16 on A100.
In the experiments of decoding, we updated the following parameters:
- head_num = 96
- size_per_head = 128
- num_layers = 48 for GPT-89B model, 96 for GPT-175B model
- data_type = FP16
- vocab_size = 51200
- top_p = 0.9
- tensor parallel size = 8
- input sequence length = 512
- ouptut sequence length = 32
Release notes
Changelog
June 2021
- Support XLNet
April 2021
- Support multi-gpus and multi-nodes inference for GPT model on C++ and PyTorch.
- Support single node, multi-gpus inference for GPT model on triton.
- Add the int8 fused multi-head attention kernel for bert.
- Add the FP16 fused multi-head attention kernel of V100 for bert.
- Optimize the kernel of decoder.
- Move to independent repo.
- Release the FasterTransformer 4.0
Dec 2020
- Optimize the decoding by adding the finisehd mask to prevent useless computing.
- Support opennmt encoder.
- Remove the TensorRT plugin supporting.
- Release the FasterTransformer 3.1
Nov 2020
- Optimize the INT8 inference.
- Support PyTorch INT8 inference.
- Provide PyTorch INT8 quantiztion tools.
- Integrate the fused multi-head attention kernel of TensorRT into FasterTransformer.
- Add unit test of SQuAD.
- Update the missed NGC checkpoints.
Sep 2020
- Support GPT2
- Release the FasterTransformer 3.0
- Support INT8 quantization of encoder of cpp and TensorFlow op.
- Add bert-tf-quantization tool.
- Fix the issue that Cmake 15 or Cmake 16 fail to build this project.
Aug 2020
- Fix the bug of trt plugin.
June 2020
- Release the FasterTransformer 2.1
- Add Effective FasterTransformer based on the idea of Effective Transformer idea.
- Optimize the beam search kernels.
- Add PyTorch op supporting
May 2020
- Fix the bug that seq_len of encoder must be larger than 3.
- Add the position_encoding of decoding as the input of FasterTransformer decoding. This is convenient to use different types of position encoding. FasterTransformer does not compute the position encoding value, but only lookup the table.
- Modifying the method of loading model in
translate_sample.py.
April 2020
- Rename
decoding_opennmt.htodecoding_beamsearch.h - Add DiverseSiblingsSearch for decoding.
- Add sampling into Decoding
- The implementation is in the
decoding_sampling.h - Add top_k sampling, top_p sampling for decoding.
- The implementation is in the
- Refactor the tensorflow custom op codes.
- Merge
bert_transformer_op.h,bert_transformer_op.cu.ccintobert_transformer_op.cc - Merge
decoder.h,decoder.cu.ccintodecoder.cc - Merge
decoding_beamsearch.h,decoding_beamsearch.cu.ccintodecoding_beamsearch.cc
- Merge
- Fix the bugs of finalize function decoding.py.
- Fix the bug of tf DiverseSiblingSearch.
- Add BLEU scorer
bleu_score.pyintoutils. Note that the BLEU score requires python3. - Fuse QKV Gemm of encoder and masked_multi_head_attention of decoder.
- Add dynamic batch size and dynamic sequence length features into all ops.
March 2020
- Add feature in FasterTransformer 2.0
- Add
translate_sample.pyto demonstrate how to translate a sentence by restoring the pretrained model of OpenNMT-tf.
- Add
- Fix bugs of Fastertransformer 2.0
- Fix the bug of maximum sequence length of decoder cannot be larger than 128.
- Fix the bug that decoding does not check finish or not after each step.
- Fix the bug of decoder about max_seq_len.
- Modify the decoding model structure to fit the OpenNMT-tf decoding model.
- Add a layer normalization layer after decoder.
- Add a normalization for inputs of decoder
Febuary 2020
- Release the FasterTransformer 2.0
- Provide a highly optimized OpenNMT-tf based decoder and decoding, including C++ API and TensorFlow op.
- Refine the sample codes of encoder.
- Add dynamic batch size feature into encoder op.
July 2019
- Release the FasterTransformer 1.0
- Provide a highly optimized bert equivalent transformer layer, including C++ API, TensorFlow op and TensorRT plugin.
Known issues
- Undefined symbol errors when import the extension
- Please
import torchfirst. If this has been done, it is due to the incompatible C++ ABI. You may need to check the PyTorch used during compilation and execution are the same, or you need to check how your PyTorch is compiled, or the version of your GCC, etc.
- Please
- Results of TensorFlow and OP would be different in decoding. This problem is caused by the accumulated log probability, and we do not avoid this problem.
- If encounter some problem in the custom environment, try to use the gcc/g++ 4.8 to build the project of TensorFlow op, especially for TensorFlow 1.14.
TODO
- Support the decoding sampling in PyTorch.









