DarkTorch (Work In Progress)
A docker based low-latency deep learning library and inference server written in C++11 using the PyTorch C++ frontend.
Above all, this project is a step by step tutorial for building production grade AI systems in Libtorch / C++.
What is it all about?
There is no better way of depicting the usefulness of DarkTorch by viewing several demos:
- A C++ demo of running inference on a traced PyTorch Resnet34 CNN model using a tqdm like callback.
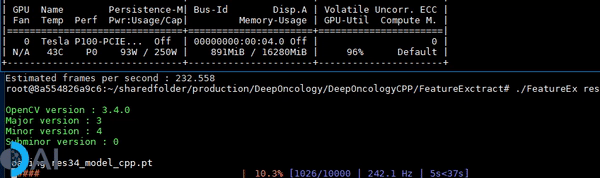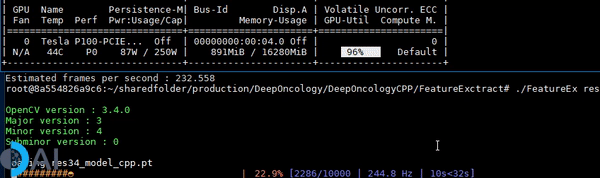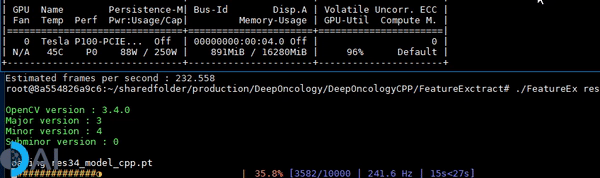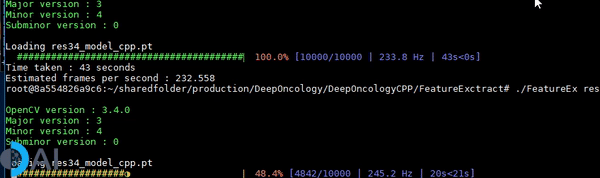
Introduction
![]()
This repository implements a low-latency deep learning inference LIBRARY and server using pytorch C++ frontend.
The DarkTorch service is a C++ application running a HTTP server with a REST API. This service is able to run inference on multiple deep learning models in parallel on all the available GPU processors to obtain the results in the shortest time possible.
Performance (In progress):
The inference speed is benchmarked on a single NVIDIA Tesla P-100 GPU.
| Architecture | Threads | Batch Size | Inference Speed(FPS) | Checkpoint |
|---|---|---|---|
| ResNet9 (C++) https://github.com/lambdal/cifar10-fast | 1 | 1 | |
| BaiduNet8 (C++) https://github.com/BAIDU-USA-GAIT-LEOPARD/CIFAR10-Inference-BaiduNet8 | 1 | 1 | |
| Yolo-v3 (C++) https://github.com/walktree/libtorch-yolov3 | 1 | 1 | |
| Mask-RCNN (C++) https://github.com/lsrock1/maskrcnn_benchmark.cpp | 1 | 1 |
Table of contents
torch::jit::script::Module module = torch::jit::load(s_model_name, torch::kCUDA);
Technologies
This projects makes use of several technologies:
- C++11 welll ...
#include <chrono>
#include <stdio.h>
#include <torch/torch.h>
#include <torch/script.h>
etc etc
- Docker: for bundling all the dependencies of our program and for easier deployment.
We inherit from:
FROM nvcr.io/nvidia/pytorch:19.02-py3
RUN apt-get update &&\
apt-get install -y sudo git bash
ENV PATH /usr/local/nvidia/bin:/usr/local/cuda/bin:/code/cmake-3.14.3-Linux-x86_64/bin:${PATH}
ENV PYTHONPATH=/opt/conda/lib/python3.6/site-packages/:$PYTHONPATH
ENV LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/opt/conda/lib/:/opt/conda/lib/python3.6
...
...
The whole docker file is availabe here:
- Libtorch: because it has good performance and a simple C++ API. Torch has now two versions:
(Pre-cxx11 ABI):
https://download.pytorch.org/libtorch/cu100/libtorch-shared-with-deps-1.2.0.zip
(cxx11 ABI, compiled with _GLIBCXX_USE_CXX11_ABI = 1):
https://download.pytorch.org/libtorch/cu100/libtorch-cxx11-abi-shared-with-deps-1.2.0.zip
- OpenCV: to have a simple C++ API for GPU image processing.
- [CMake] (https://cmake.org/): refer to the sample C++ applications. Sample
CMakeLists.txtfile is available here:
cmake_minimum_required(VERSION 3.5 FATAL_ERROR)
project(FeatureEx VERSION 1.2.3.4 LANGUAGES CXX)
set(PROJECT_NAME FeatureEx)
if (NOT DEFINED CMAKE_CXX_STANDARD)
SET(CMAKE_CXX_STANDARD 11)
SET(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_VERBOSE_MAKEFILE ON)
endif ()
if (CMAKE_CXX_STANDARD LESS 11)
message(FATAL_ERROR "CMAKE_CXX_STANDARD is less than 11.")
endif ()
set(CMAKE_BUILD_TYPE Release)
set(CXX_RELEASE_FLAGS = -O3 -march=native)
Building
Prerequisites
- A Kepler or Maxwell NVIDIA GPU with at least 8 GB of memory.
- A Linux host system with recent NVIDIA drivers (recommended: 415).
- Install nvidia-docker2.
Build command
The command might take a while to execute:
sudo docker build -t cuda10-trt cuda10-trt
Testing
Start the docker container
sudo nvidia-docker run -it --shm-size=4g --env="DISPLAY" --volume="$HOME/.Xauthority:/root/.Xauthority:rw" -v /tmp/.X11-unix:/tmp/.X11-unix:rw -p 8097:8097 -p 3122:22 -p 7842:7842 -p 8787:8787 -p 8786:8786 -p 8788:8788 -p 8888:8888 -p 5000:5000 -v ~/dev/:/root/sharedfolder -v ~/dev/.torch/models/:/root/.cache/torch/checkpoints/ cuda10-trt bash
We assume that the PyTorch models are mapped externally to docker via the -v command and reside here: ~/dev/.torch/models/. You can ammend that path to reflect the settings in your environment.
Starting the server
Execute the following command and wait a few seconds for the initialization of the classifiers:
Single image Classifiation
Tested CNN models
- ResNet9
- ResNet18
- BaiduNet8
- Yolo-v3 (C++)
Environment
The code is developed under the following configurations.
- Hardware: 1 GPU for testing
- Software: Ubuntu 16.04.3 LTS, CUDA>=10.0, Python>=3.6, PyTorch>=1.2.0
- Dependencies: refer to the docker file
Benchmarking performance
We can benchmark the performance of our inference server using any tool that can generate HTTP load. We included a Dockerfile
for a benchmarking client using rakyll/hey:
Contributing
Feel free to report issues during build or execution. We also welcome suggestions to improve the performance of this application.
Author
Shlomo Kashani, Head of AI at DeepOncology AI,
Kaggle Expert, Founder of Tel-Aviv Deep Learning Bootcamp: [email protected]



