TextRank Demo
A simple website demonstrating TextRank's extractive summarization capability. Currently supports English and Chinese.
Usage
WARNING: At the current state, the backend does almost to none input value validation. Please do not anticipate it to have production quality.
Docker (Recommended)
Two options for you:
- Dockerfile.cpu: No LASER support. Classic textrank, USE-base and USE-large work.
- Dockerfile.laser_cpu: Classic textrank, USE-base, USE-large, and LASER work.
(USE-xling probably won't work in both cases due to reason described in the June 2019 update log.)
Build the docker image using:
docker build -t <name> -f <Dockerfile.cpu or Dockerfile.laser_cpu> .
Start a container using:
docker run -u 1000:1000 --rm -ti -p 8000:8000 -e TFHUB_CACHE_DIR=/some/path/tf_hub_cache/ -e BAIDU_APP_ID=<ID> -e BAIDU_APP_KEY=<key> -e BAIDU_SECRET_KEY=<secret> -v /some/path:/some/path <name>
If you're not feeding Chinese text to the server, you can skip BAIDU related environment variables. Setting TFHUB_CACHE_DIR is recommended to save the time by avoiding downloading the models every time you start a new container.
Visit http://localhost:8000 in your browser.
Local Python Environment
-
This project uses Starlette (a lightweight ASGI framework/toolkit), so Python 3.6+ is required.
-
Install dependencies by running
pip install -r requirements.txt. -
Start the demo server by running
python demo.py, and then visithttp://localhost:8000in your browser.
(Depending on your Python setup, you might need to replace pip with pip3, and python with python3.)
API server
There's a very simple script(api.py) to create a api server using fastapi. It might be a good starting point for you to expand upon (that's what I did to create a private textrank api server).
Languages supported
English
Demo: A static snapshot with an example from Wikipedia.
This largely depends on language preprocessing functions and classes from summanlp/textrank. This project just exposes some of their internal data.
Accoring to summanlp/textrank, you can install an extra library to improve keyword extraction:
For a better performance of keyword extraction, install Pattern.
From a quick glance at the source code, it seems to be using Pattern (if available) to do some POS tag filtering.
Chinese
Demo: A static snapshot with an example from a news article.
This project uses Baidu's free NLP API to do word segmentation and POS tagging. You need to create an account there, install the Python SDK, and set the following environment variables:
- BAIDU_APP_ID
- BAIDU_APP_KEY
- BAIDU_SECRET_KEY
You can of course use other offline NLP tools instead. Please refer to test_text_cleaning_zh.py for information on the data structures expected by the main function.
Traditional Chinese will be converted to Simplified Chinese due to the restrictions of Baidu API.
Japanese
Demo: A static snapshot with an example from a news article.
It uses nagisa to do word segmentation and POS tagging. There are some Japanese peculiarities that make it a bit tricky, and I had to add a few stopwords go get more reasonable results for demo. Obviously there is much room of improvement here.
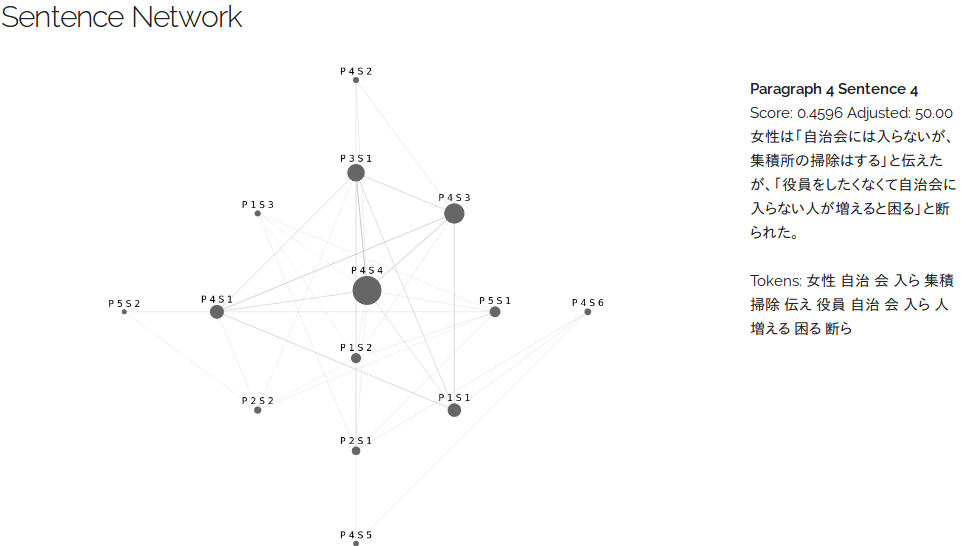
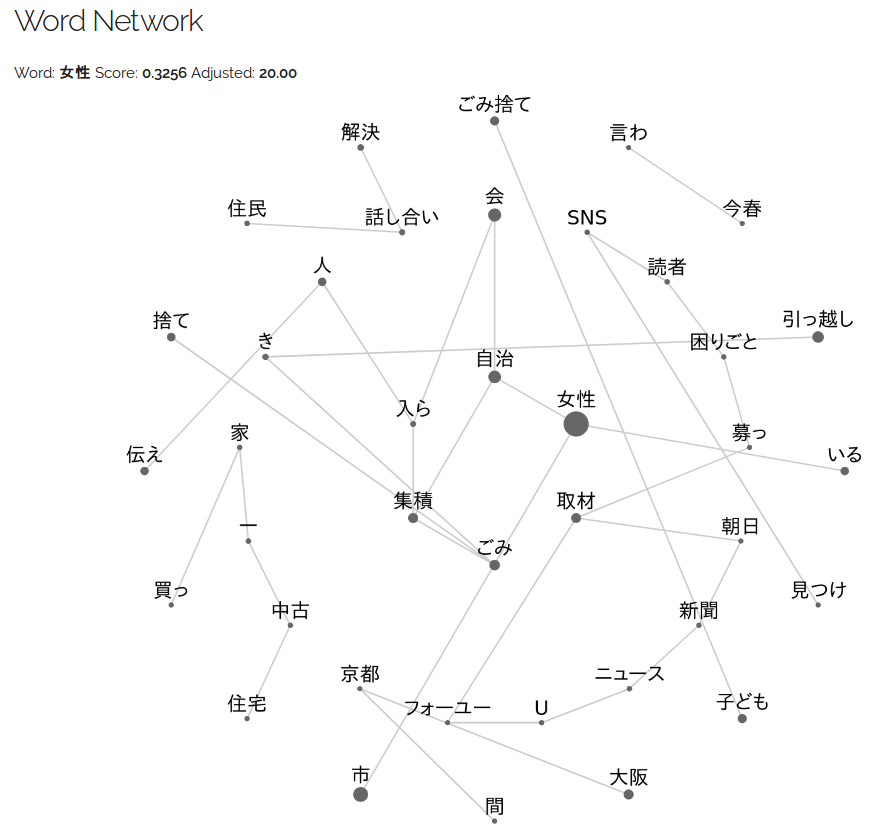
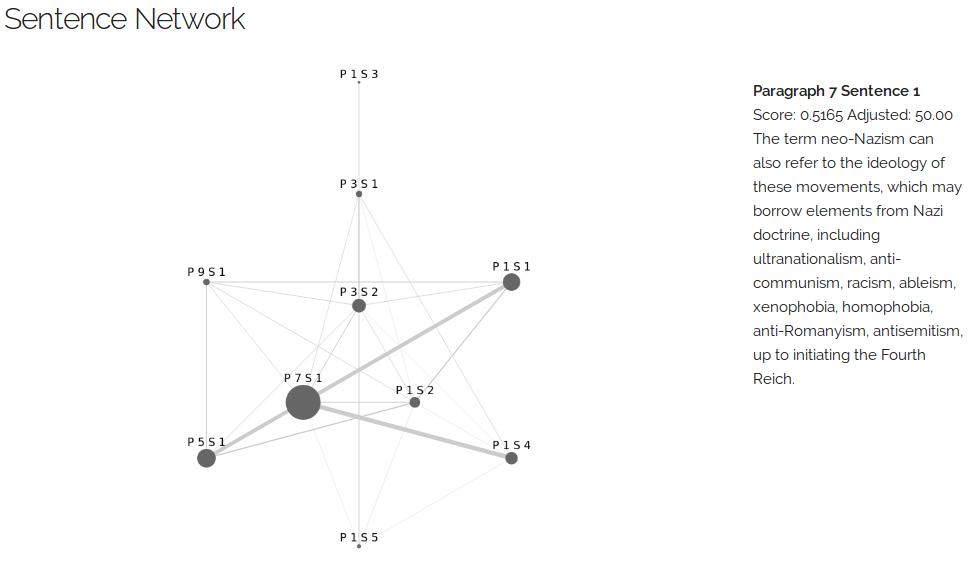
Snapshots
English

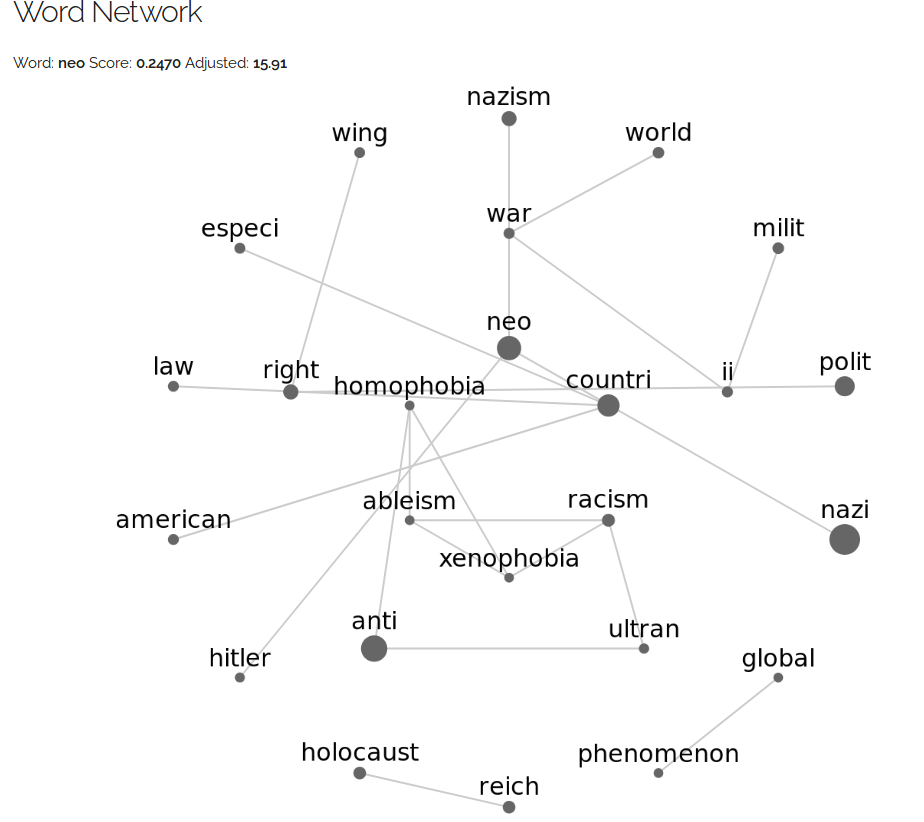
Chinese

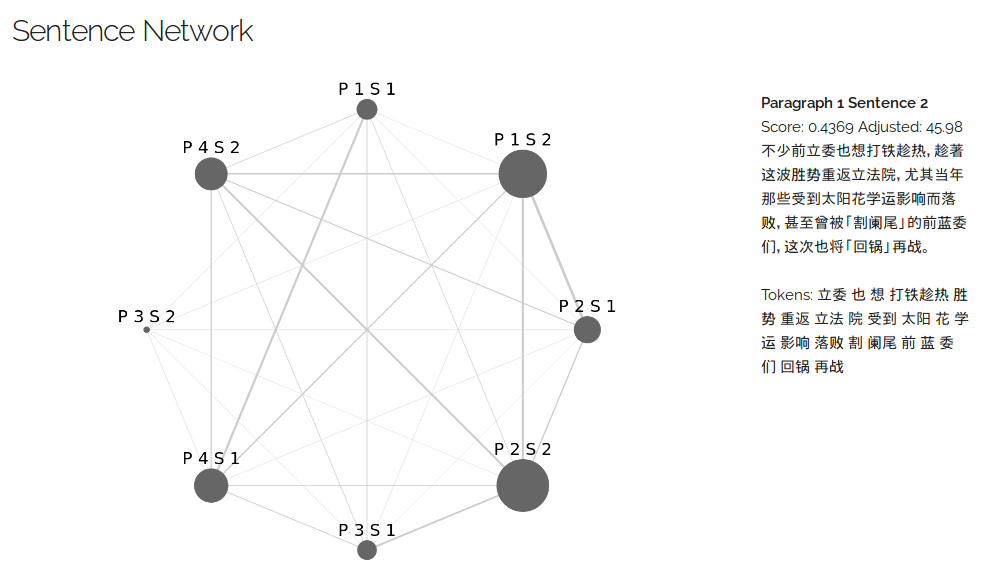
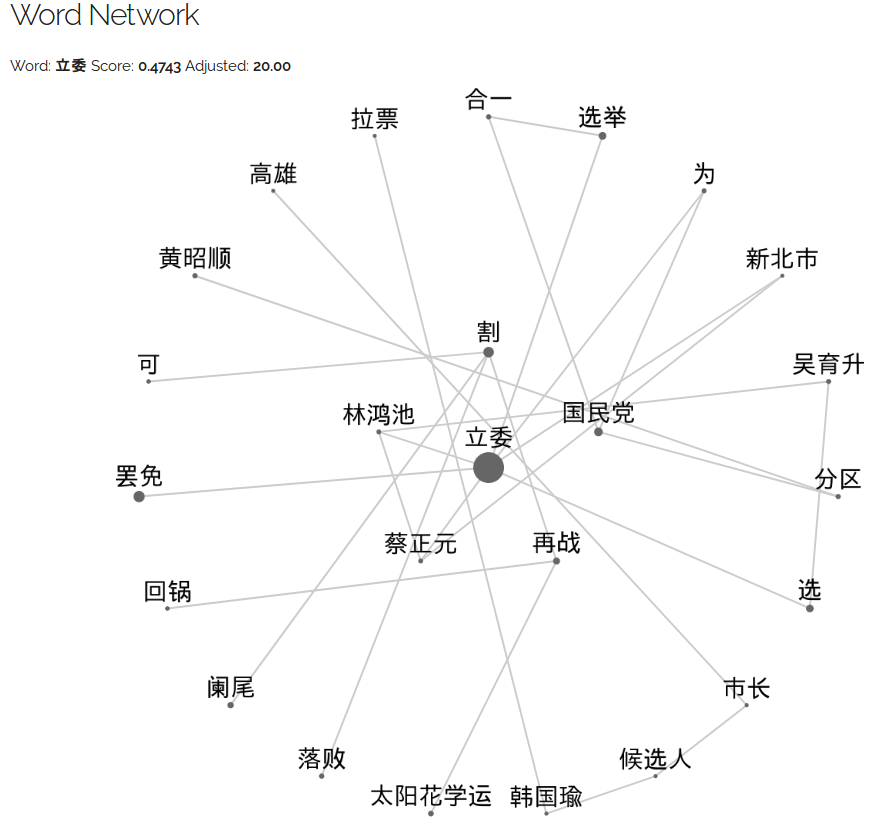
Japanese