RL A3C Pytorch
Newly Added A3g A New Gpu/Cpu Architecture Of A3c For Substantially Accelerated Training!!


NEWLY ADDED A3G!!
New implementation of A3C that utilizes GPU for speed increase in training. Which we can call A3G. A3G as opposed to other versions that try to utilize GPU with A3C algorithm, with A3G each agent has its own network maintained on GPU but shared model is on CPU and agent models are quickly converted to CPU to update shared model which allows updates to be frequent and fast by utilizing Hogwild Training and make updates to shared model asynchronously and without locks. This new method greatly increase training speed and models that use to take days to train can be trained in as fast as 10minutes for some Atari games! 10-15minutes for Breakout to start to score over 400! And 10mins to solve Pong!
This repository includes my implementation with reinforcement learning using Asynchronous Advantage Actor-Critic (A3C) in Pytorch an algorithm from Google Deep Mind's paper "Asynchronous Methods for Deep Reinforcement Learning."
See [a3c_continuous][23] a newly added repo of my A3C LSTM implementation for continuous action spaces which was able to solve BipedWalkerHardcore-v2 environment (average 300+ for 100 consecutive episodes)
A3C LSTM
I implemented an A3C LSTM model and trained it in the atari 2600 environments provided in the Openai Gym. So far model currently has shown the best prerfomance I have seen for atari game environments. Included in repo are trained models for SpaceInvaders-v0, MsPacman-v0, Breakout-v0, BeamRider-v0, Pong-v0, Seaquest-v0 and Asteroids-v0 which have had very good performance and currently hold the best scores on openai gym leaderboard for each of those games(No plans on training model for any more atari games right now...). Saved models in trained_models folder. *Removed trained models to reduce the size of repo
Have optimizers using shared statistics for RMSProp and Adam available for use in training as well option to use non shared optimizer.
Gym atari settings are more difficult to train than traditional ALE atari settings as Gym uses stochastic frame skipping and has higher number of discrete actions. Such as Breakout-v0 has 6 discrete actions in Gym but ALE is set to only 4 discrete actions. Also in GYM atari they randomly repeat the previous action with probability 0.25 and there is time/step limit that limits performance.
link to the Gym environment evaluations below
| Tables | Best 100 episode Avg | Best Score |
|---|---|---|
| SpaceInvaders-v0 | 5808.45 ± 337.28 | 13380.0 |
| SpaceInvaders-v3 | 6944.85 ± 409.60 | 20440.0 |
| SpaceInvadersDeterministic-v3 | 79060.10 ± 5826.59 | 167330.0 |
| Breakout-v0 | 739.30 ± 18.43 | 864.0 |
| Breakout-v3 | 859.57 ± 1.97 | 864.0 |
| Pong-v0 | 20.96 ± 0.02 | 21.0 |
| PongDeterministic-v3 | 21.00 ± 0.00 | 21.0 |
| BeamRider-v0 | 8441.22 ± 221.24 | 13130.0 |
| MsPacman-v0 | 6323.01 ± 116.91 | 10181.0 |
| Seaquest-v0 | 54203.50 ± 1509.85 | 88840.0 |
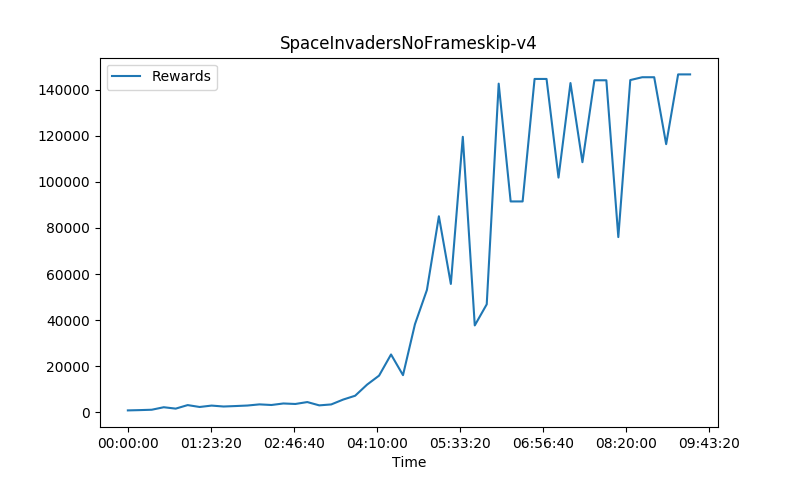
The 167,330 Space Invaders score is World Record Space Invaders score and game ended only due to GYM timestep limit and not from loss of life. When I increased the GYM timestep limit to a million its reached a score on Space Invaders of approximately 2,300,000 and still ended due to timestep limit. Most likely due to game getting fairly redundent after a while
Due to gym version Seaquest-v0 timestep limit agent scores lower but on Seaquest-v4 with higher timestep limit agent beats game (see gif above) with max possible score 999,999!!
Requirements
- Python 2.7+
- Openai Gym and Universe
- Pytorch
Training
When training model it is important to limit number of worker processes to number of cpu cores available as too many processes (e.g. more than one process per cpu core available) will actually be detrimental in training speed and effectiveness
To train agent in Pong-v0 environment with 32 different worker processes:
python main.py --env Pong-v0 --workers 32
A3C-GPU
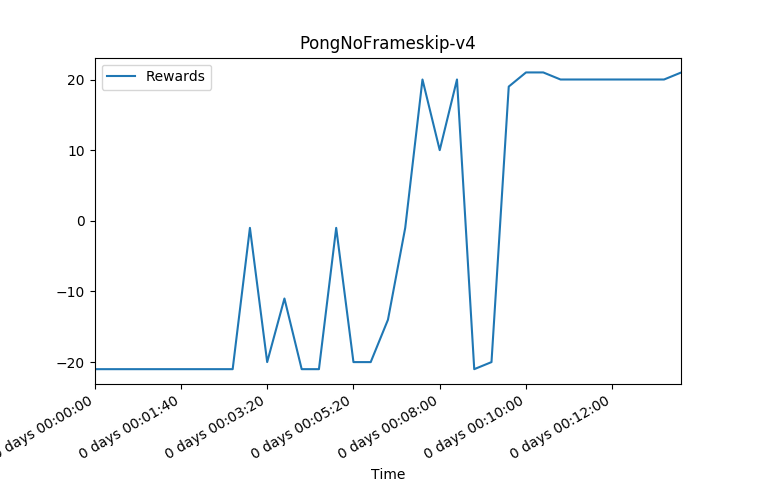
training using machine with 4 V100 GPUs and 20core CPU for PongDeterministic-v4 took 10 minutes to converge
To train agent in PongDeterministic-v4 environment with 32 different worker processes on 4 GPUs with new A3G:
python main.py --env PongDeterministic-v4 --workers 32 --gpu-ids 0 1 2 3 --amsgrad True
Hit Ctrl C to end training session properly

Evaluation
To run a 100 episode gym evaluation with trained model
python gym_eval.py --env Pong-v0 --num-episodes 100
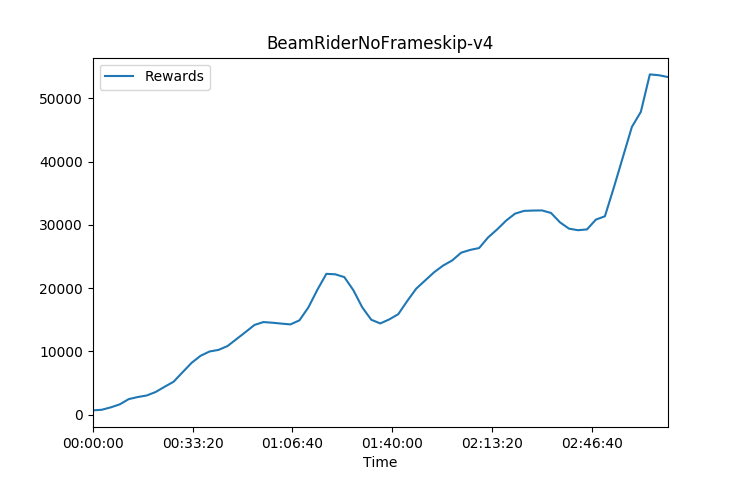
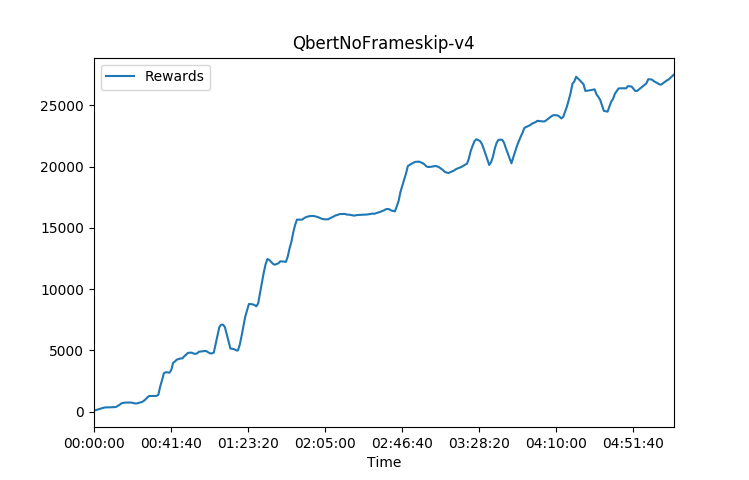
Notice BeamRiderNoFrameskip-v4 reaches scores over 50,000 in less than 2hrs of training compared to the gym v0 version this shows the difficulty of those versions but also the timelimit being a major factor in score level
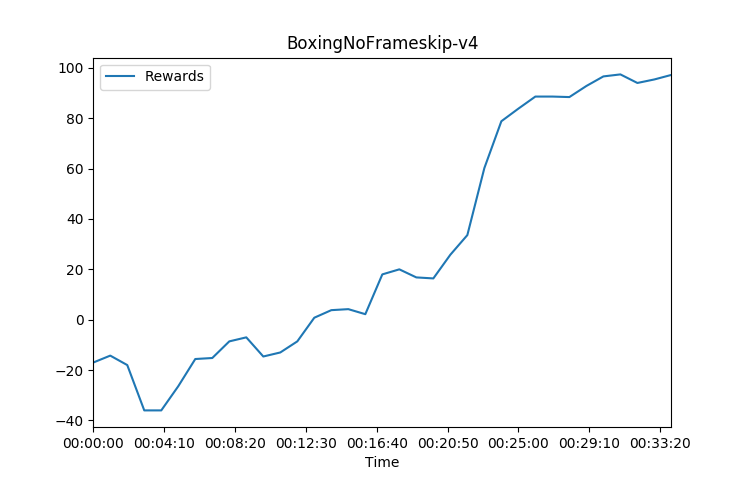
These training charts were done on a DGX Station using 4GPUs and 20core Cpu. I used 36 worker agents and a tau of 0.92 which is the lambda in Generalized Advantage Estimation equation to introduce more variance due to the more deterministic nature of using just a 4 frame skip environment and a 0-30 NoOp start