Qlib
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
With Qlib, you can easily try your ideas to create better Quant investment strategies.
Framework of Qlib
At the module level, Qlib is a platform that consists of above components. The components are designed as loose-coupled modules and each component could be used stand-alone.
| Name | Description |
|---|---|
| Data layer | DataServer focus on providing high performance infrastructure for user to retrieve and get raw data. DataEnhancement will preprocess the data and provide the best dataset to be fed in to the models |
| Interday Model | Interday model focus on producing forecasting signals(aka. alpha). Models are trained by Model Creator and managed by Model Manager. User could choose one or multiple models for forecasting. Multiple models could be combined with Ensemble module |
| Interday Strategy | Portfolio Generator will take forecasting signals as input and output the orders based on current position to achieve target portfolio |
| Intraday Trading | Order Executor is responsible for executing orders output by Interday Strategy and returning the executed results. |
| Analysis | User could get detailed analysis report of forecasting signal and portfolio in this part. |
- The modules with hand-drawn style is under development and will be released in the future.
- The modules with dashed border is highly user-customizable and extendible.
Quick start
This quick start guide tries to demonstrate
- It's very easy to build a complete Quant research workflow and try you ideas with Qlib.
- Though with simple data and naive models, machine learning technologies work very well in practical Quant investment.
Installation
Before installing Qlib from source, user need to install some dependencies:
pip install numpy
pip install --upgrade cython
Clone the repository and install Qlib:
git clone https://github.com/microsoft/qlib.git
python setup.py install
Get Data
Load and prepare data:
python scripts/get_data.py qlib_data_cn --target_dir ~/.qlib/qlib_data/cn_data
This dataset created by public data collected by crawler scripts, which have been released in
the same repository.
User could create the same dataset with it.
Auto Quant research workflow with estimator
Qlib provides a tool named estimator to run whole workflow automatically(including building dataset, training models, backtest, analysis)
-
Run
estimatorwith estimator_config.yamlcd examples # Avoid running program under the directory contains `qlib` estimator -c estimator/estimator_config.yamlEstimator result:
risk sub_bench mean 0.000662 std 0.004487 annual 0.166720 sharpe 2.340526 mdd -0.080516 sub_cost mean 0.000577 std 0.004482 annual 0.145392 sharpe 2.043494 mdd -0.083584Here are detailed documents for Estimator.
-
Analysis
Run
examples/estimator/analyze_from_estimator.ipynbwithjupyter notebook-
Forecasting signal(model prediction) analysis
- Cumulative Return of groups
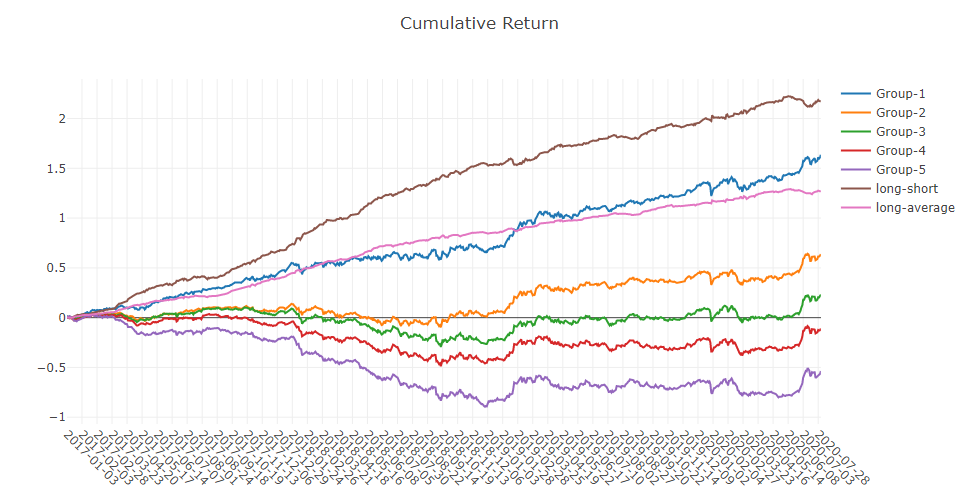
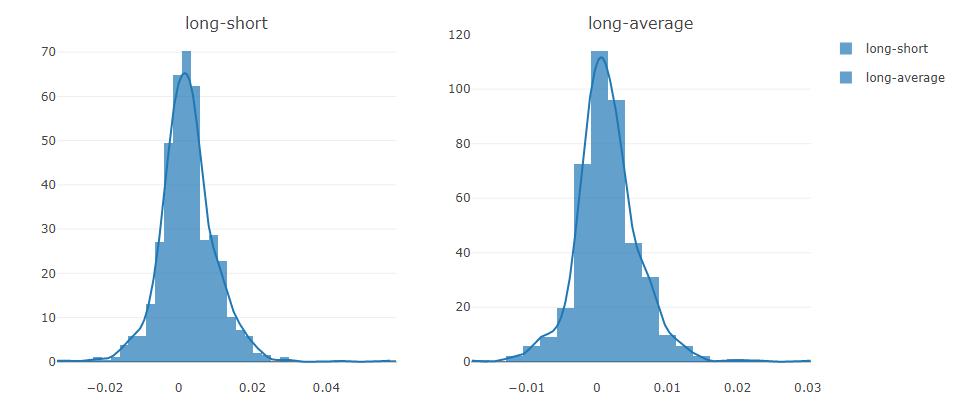
- Return distribution
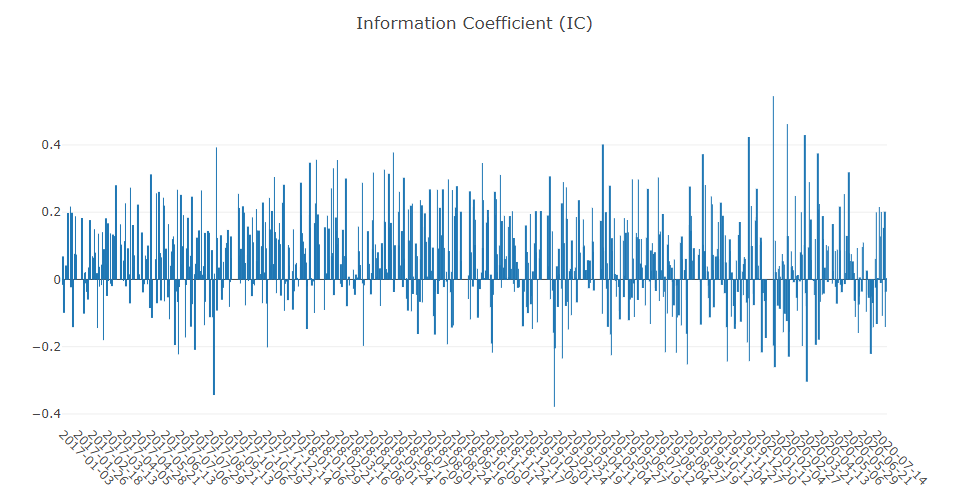
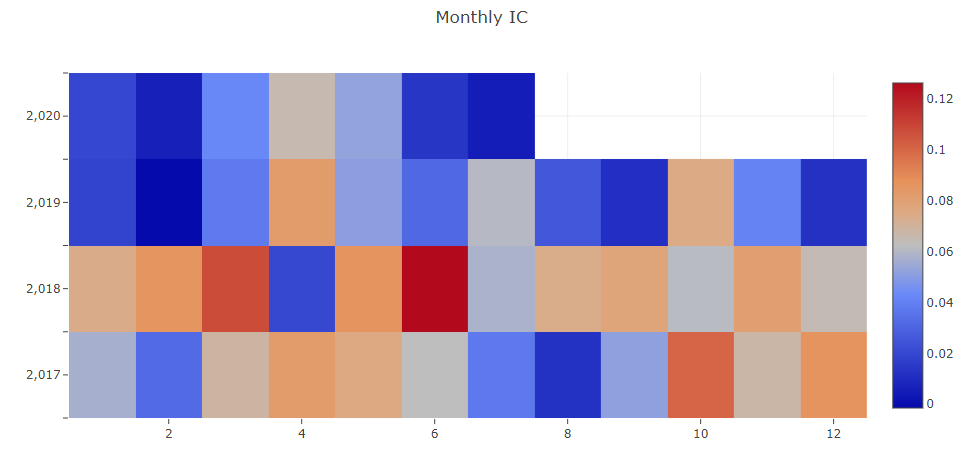
- Information Coefficient(IC)
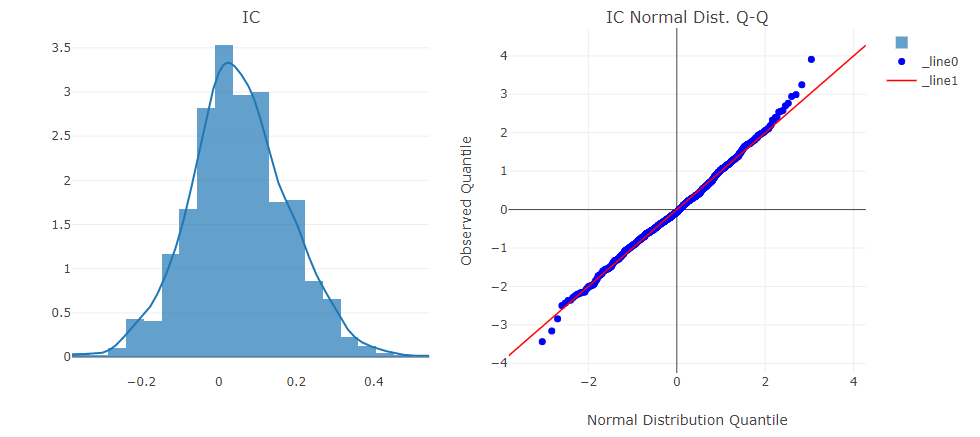
- Auto Correlation of forecasting signal(model prediction)
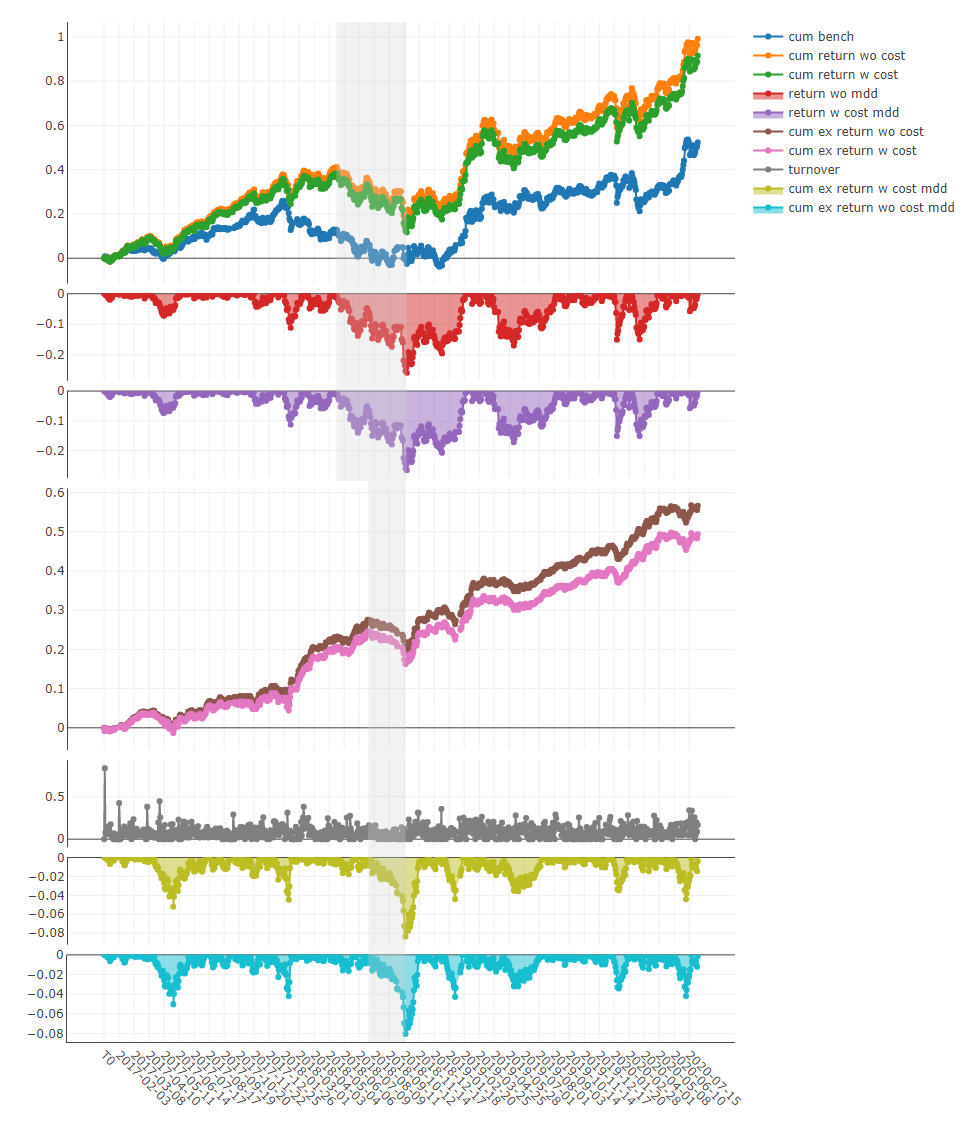
- Cumulative Return of groups
-
Portfolio analysis
- Backtest return

- Backtest return
-
Building customized Quant research workflow by code
Automatic workflow may not suite the research workflow of all Quant researchers. To support flexible Quant research workflow, Qlib also provide modularized interface to allow researchers to build their own workflow by code. Here is a demo for customized Quant research workflow by code
More About Qlib
The detailed documents are organized in docs.
Sphinx and the readthedocs theme is required to build the documentation in html formats.
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make html
You can also view the latest document online directly.
Qlib is in active and continues development. Our plan is in the roadmap, which is managed as a github project.
Offline mode and online mode of data server
The data server of Qlib can either deployed as offline mode or online mode. The default mode is offline mode.
Under offline mode, the data will be deployed locally.
Under online mode, the data will be deployed as a shared data service. The data and their cache will be shared by all the clients. The data retrieval performance is expected to be improved due to a higher rate of cache hits. It will consume less disk space, too. The documents of the online mode can be found in Qlib-Server. The online mode can be deployed automatically with Azure CLI based scripts
Performance of Qlib Data Server
The performance of data processing is important to data-driven methods like AI technologies. As an AI-oriented platform, Qlib provides a solution for data storage and data processing. To demonstrate the performance of Qlib data server, we
compare it with several other data storage solutions.
We evaluate the performance of several storage solutions by finishing the same task,
which creates a dataset(14 features/factors) from the basic OHLCV daily data of a stock market(800 stocks each day from 2007 to 2020). The task involves data queries and processing.
| HDF5 | MySQL | MongoDB | InfluxDB | Qlib -E -D | Qlib +E -D | Qlib +E +D | |
|---|---|---|---|---|---|---|---|
| Total (1CPU) (seconds) | 184.4±3.7 | 365.3±7.5 | 253.6±6.7 | 368.2±3.6 | 147.0±8.8 | 47.6±1.0 | 7.4±0.3 |
| Total (64CPU) (seconds) | 8.8±0.6 | 4.2±0.2 |
+(-)Eindicates with(out)ExpressionCache+(-)Dindicates with(out)DatasetCache
Most general-purpose databases take too much time on loading data. After looking into the underlying implementation, we find that data go through too many layers of interfaces and unnecessary format transformations in general-purpose database solutions.
Such overheads greatly slow down the data loading process.
Qlib data are stored in a compact format, which is efficient to be combined into arrays for scientific computation.



