High-Resolution Transformer for Dense Prediction
This is the official implementation of High-Resolution Transformer (HRT). We present a High-Resolution Transformer (HRT) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformeron human pose estimation and semantic segmentation tasks.
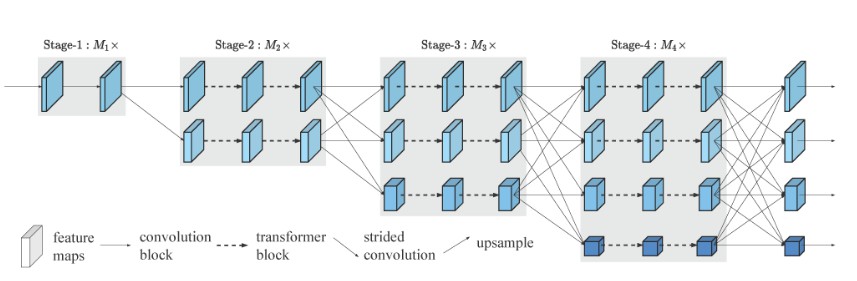
- The High-Resolution Transformer architecture:
Pose estimation
2d Human Pose Estimation
Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
| Backbone | Input Size | AP | AP50 | AP75 | ARM | ARL | AR | ckpt | log | script |
|---|---|---|---|---|---|---|---|---|---|---|
| HRT-S | 256x192 | 74.0% | 90.2% | 81.2% | 70.4% | 80.7% | 79.4% | ckpt | log | script |
| HRT-S | 384x288 | 75.6% | 90.3% | 82.2% | 71.6% | 82.5% | 80.7% | ckpt | log | script |
| HRT-B | 256x192 | 75.6% | 90.8% | 82.8% | 71.7% | 82.6% | 80.8% | ckpt | log | script |
| HRT-B | 384x288 | 77.2% | 91.0% | 83.6% | 73.2% | 84.2% | 82.0% | ckpt | log | script |
Results on COCO test-dev with detector having human AP of 56.4 on COCO val2017 dataset
| Backbone | Input Size | AP | AP50 | AP75 | ARM | ARL | AR | ckpt | log | script |
|---|---|---|---|---|---|---|---|---|---|---|
| HRT-S | 384x288 | 74.5% | 92.3% | 82.1% | 70.7% | 80.6% | 79.8% | ckpt | log | script |
| HRT-B | 384x288 | 76.2% | 92.7% | 83.8% | 72.5% | 82.3% | 81.2% | ckpt | log | script |
The models are first pre-trained on ImageNet-1K dataset, and then fine-tuned on COCO val2017 dataset.
Semantic segmentation
Cityscapes
Performance on the Cityscapes dataset. The models are trained and tested with input size of 512x1024 and 1024x2048 respectively.
| Methods | Backbone | Window Size | Train Set | Test Set | Iterations | Batch Size | OHEM | mIoU | mIoU (Multi-Scale) | Log | ckpt | script |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCRNet | HRT-S | 7x7 | Train | Val | 80000 | 8 | Yes | 80.0 | 81.0 | log | ckpt | script |
| OCRNet | HRT-B | 7x7 | Train | Val | 80000 | 8 | Yes | 81.4 | 82.0 | log | ckpt | script |
| OCRNet | HRT-B | 15x15 | Train | Val | 80000 | 8 | Yes | 81.9 | 82.6 | log | ckpt | script |
PASCAL-Context
The models are trained with the input size of 520x520, and tested with original size.
| Methods | Backbone | Window Size | Train Set | Test Set | Iterations | Batch Size | OHEM | mIoU | mIoU (Multi-Scale) | Log | ckpt | script |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCRNet | HRT-S | 7x7 | Train | Val | 60000 | 16 | Yes | 53.8 | 54.6 | log | ckpt | script |
| OCRNet | HRT-B | 7x7 | Train | Val | 60000 | 16 | Yes | 56.3 | 57.1 | log | ckpt | script |
| OCRNet | HRT-B | 15x15 | Train | Val | 60000 | 16 | Yes | 57.6 | 58.5 | log | ckpt | script |
COCO-Stuff
The models are trained with input size of 520x520, and tested with original size.
| Methods | Backbone | Window Size | Train Set | Test Set | Iterations | Batch Size | OHEM | mIoU | mIoU (Multi-Scale) | Log | ckpt | script |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCRNet | HRT-S | 7x7 | Train | Val | 60000 | 16 | Yes | 37.9 | 38.9 | log | ckpt | script |
| OCRNet | HRT-B | 7x7 | Train | Val | 60000 | 16 | Yes | 41.6 | 42.5 | log | ckpt | script |
| OCRNet | HRT-B | 15x15 | Train | Val | 60000 | 16 | Yes | 42.4 | 43.3 | log | ckpt | script |
ADE20K
The models are trained with input size of 520x520, and tested with original size. The results with window size 15x15 will be updated latter.
| Methods | Backbone | Window Size | Train Set | Test Set | Iterations | Batch Size | OHEM | mIoU | mIoU (Multi-Scale) | Log | ckpt | script |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCRNet | HRT-S | 7x7 | Train | Val | 150000 | 8 | Yes | 44.0 | 45.1 | log | ckpt | script |
| OCRNet | HRT-B | 7x7 | Train | Val | 150000 | 8 | Yes | 46.3 | 47.6 | log | ckpt | script |
| OCRNet | HRT-B | 13x13 | Train | Val | 150000 | 8 | Yes | 48.7 | 50.0 | log | ckpt | script |
| OCRNet | HRT-B | 15x15 | Train | Val | 150000 | 8 | Yes | - | - | - | - | - |
Classification
Results on ImageNet-1K
| Backbone | acc@1 | acc@5 | #params | FLOPs | ckpt | log | script |
|---|---|---|---|---|---|---|---|
| HRT-T | 78.6% | 94.2% | 8.0M | 1.83G | ckpt | log | script |
| HRT-S | 81.2% | 95.6% | 13.5M | 3.56G | ckpt | log | script |
| HRT-B | 82.8% | 96.3% | 50.3M | 13.71G | ckpt | log | script |
Citation
If you find this project useful in your research, please consider cite:
@article{YuanFHZCW21,
title={HRT: High-Resolution Transformer for Dense Prediction},
author={Yuhui Yuan and Rao Fu and Lang Huang and Chao Zhang and Xilin Chen and Jingdong Wang},
booktitle={arXiv},
year={2021}
}
Acknowledgment
This project is developed based on the Swin-Transformer, openseg.pytorch, and mmpose.
git diff-index HEAD
git subtree add -P pose <url to sub-repo> <sub-repo branch>









