AsyncRetriever
Asynchronous requests with persistent caching.
Features
AsyncRetriever has only one purpose; asynchronously sending requests and retrieving responses as text, binary, or json objects. It uses persistent caching to speedup the retrieval even further. Moreover, thanks to nest_asyncio you can use this function in Jupyter notebooks as well.
Please note that since this project is in early development stages, while the provided functionalities should be stable, changes in APIs are possible in new releases. But we appreciate it if you give this project a try and provide feedback. Contributions are most welcome.
Moreover, requests for additional functionalities can be submitted via issue tracker.
Installation
You can install async_retriever using pip:
$ pip install async_retriever
Alternatively, async_retriever can be installed from the conda-forge repository using Conda:
$ conda install -c conda-forge async_retriever
Quick start
AsyncRetriever has one public function: retrieve. By default, this function uses ./cache/aiohttp_cache.sqlite as the cache file. You can use cache_name argument to customize it. Now, let's see it in action!
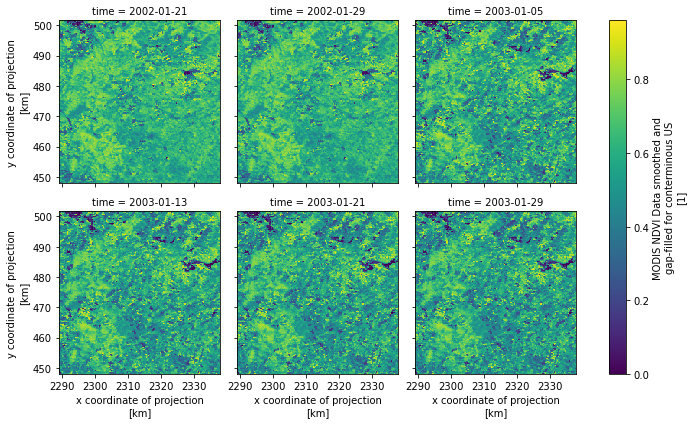
As an example for retrieving a binary response, let's use the DAAC server to get NDVI. The function can be directly passed to xarray.open_mfdataset to get the data as an xarray Dataset.
import io
import xarray as xr
import async_retriever as ar
from datetime import datetime
west, south, east, north = (-69.77, 45.07, -69.31, 45.45)
base_url = "https://thredds.daac.ornl.gov/thredds/ncss/ornldaac/1299"
dates_itr = ((datetime(y, 1, 1), datetime(y, 1, 31)) for y in range(2000, 2005))
urls, kwds = zip(
*[
(
f"{base_url}/MCD13.A{s.year}.unaccum.nc4",
{
"params": {
"var": "NDVI",
"north": f"{north}",
"west": f"{west}",
"east": f"{east}",
"south": f"{south}",
"disableProjSubset": "on",
"horizStride": "1",
"time_start": s.strftime("%Y-%m-%dT%H:%M:%SZ"),
"time_end": e.strftime("%Y-%m-%dT%H:%M:%SZ"),
"timeStride": "1",
"addLatLon": "true",
"accept": "netcdf",
}
},
)
for s, e in dates_itr
]
)
resp = ar.retrieve(urls, "binary", request_kwds=kwds, max_workers=8)
data = xr.open_mfdataset(io.BytesIO(r) for r in resp)
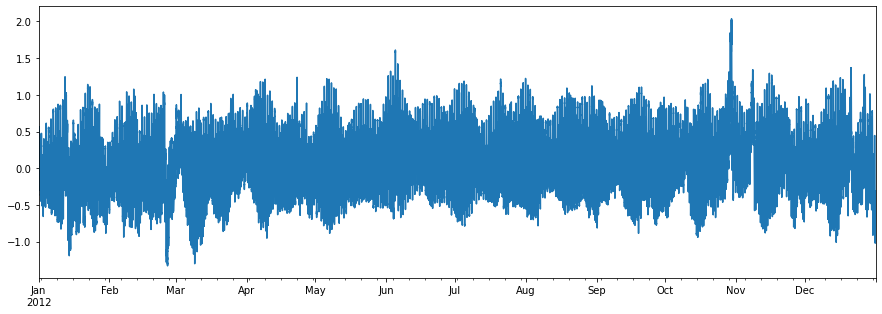
For a json response example, let's get water level recordings of a NOAA's water level station, 8534720 (Atlantic City, NJ), during 2012, using CO-OPS API. Note that this CO-OPS product has a 31-day limit for a single request, so we have to break the request down accordingly.
import pandas as pd
station_id = "8534720"
start = pd.to_datetime("2012-01-01")
end = pd.to_datetime("2012-12-31")
s = start
dates = []
for e in pd.date_range(start, end, freq="m"):
dates.append((s.date(), e.date()))
s = e + pd.offsets.MonthBegin()
url = "https://api.tidesandcurrents.noaa.gov/api/prod/datagetter"
urls, kwds = zip(
*[
(
url,
{
"params": {
"product": "water_level",
"application": "web_services",
"begin_date": f'{s.strftime("%Y%m%d")}',
"end_date": f'{e.strftime("%Y%m%d")}',
"datum": "MSL",
"station": f"{station_id}",
"time_zone": "GMT",
"units": "metric",
"format": "json",
}
},
)
for s, e in dates
]
)
resp = ar.retrieve(urls, read="json", request_kwds=kwds, cache_name="~/.cache/async.sqlite")
wl_list = []
for rjson in resp:
wl = pd.DataFrame.from_dict(rjson["data"])
wl["t"] = pd.to_datetime(wl.t)
wl = wl.set_index(wl.t).drop(columns="t")
wl["v"] = pd.to_numeric(wl.v, errors="coerce")
wl_list.append(wl)
water_level = pd.concat(wl_list).sort_index()
water_level.attrs = rjson["metadata"]
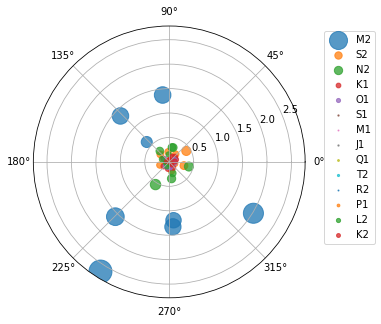
Now, let's see an example without any payload or headers. Here's how we can retrieve harmonic constituents of several NOAA stations from CO-OPS:
stations = [
"8410140",
"8411060",
"8413320",
"8418150",
"8419317",
"8419870",
"8443970",
"8447386",
]
base_url = "https://api.tidesandcurrents.noaa.gov/mdapi/prod/webapi/stations"
urls = [f"{base_url}/{i}/harcon.json?units=metric" for i in stations]
resp = ar.retrieve(urls, "json")
amp_list = []
phs_list = []
for rjson in resp:
sid = rjson["self"].rsplit("/", 2)[1]
const = pd.DataFrame.from_dict(rjson["HarmonicConstituents"]).set_index("name")
amp = const.rename(columns={"amplitude": sid})[sid]
phase = const.rename(columns={"phase_GMT": sid})[sid]
amp_list.append(amp)
phs_list.append(phase)
amp = pd.concat(amp_list, axis=1)
phs = pd.concat(phs_list, axis=1)