al-fk-self-supervision
Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Abstract
Active learning (AL) aims to minimize labeling efforts for data-demanding deep neural networks (DNNs) by selecting the most representative data points for annotation. However, currently used methods are ill-equipped to deal with biased data. The main motivation of this paper is to consider a realistic setting for pool-based semi-supervised AL, where the unlabeled collection of train data is biased. We theoretically derive an optimal acquisition function for AL in this setting. It can be formulated as distribution shift minimization between unlabeled train data and weakly-labeled validation dataset. To implement such acquisition function, we propose a low-complexity method for feature density matching using Fisher kernel (FK) self-supervision as well as several novel pseudo-label estimators. Our FK-based method outperforms state-of-the-art methods on MNIST, SVHN, and ImageNet classification while requiring only 1/10th of processing. The conducted experiments show at least 40% drop in labeling efforts for the biased class-imbalanced data compared to existing methods.
BibTex Citation
If you like our paper or code, please cite its CVPR2020 preprint using the following BibTex:
@article{gudovskiy2020al,
title={Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision},
author={Gudovskiy, Denis and Hodgkinson, Alec and Yamaguchi, Takuya and Tsukizawa, Sotaro},
journal={arXiv:2003.00393},
year={2020}
}
Installation
- Install v1.1+ PyTorch by selecting your environment on the website and running the appropriate command.
- Clone this repository: code has been tested on Python 3+.
- Install DALI for ImageNet only: tested on v0.11.0.
- Optionally install Kornia for MC-based pseudo-label estimation metrics. However, due to strict Python 3.6+ requirement for this lib, by default, we provide our simple rotation function. Use Kornia to experiment with other sampling strategies.
Datasets
Data and temporary files like descriptors, checkpoints and index files are saved into ./local_data/{dataset} folder. For example, MNIST scripts are located in ./mnist and its data is saved into ./local_data/MNIST folder, correspondingly. In order to get statistically significant results, we execute multiple runs of the same configuration with randomized weights and training dataset splits and save results to ./local_data/{dataset}/runN folders. We suggest to check that you have enough space for large-scale datasets.
MNIST, SVHN
Datasets will be automatically downloaded and converted to PyTorch after the first run of AL.
ImageNet
Due to large size, ImageNet has to be manually downloaded and preprocessed using these scripts.
Code Organization
- Scripts are located in ./{dataset} folder.
- Main parts of the framework are contained in only few files: "unsup.py", "gen_descr.py", "main_descr.py" as well as execution script "run.py".
- Dataset loaders are located in ./{dataset}/custom_datasets and DNN models in ./{dataset}/custom_models
- The "unsup.py" is a script to train initial model by unsupervised pretraining using rotation method and to produce all-random weights initial model.
- The "gen_descr.py" generates descriptor database files in ./local_data/{dataset}/runN/descr.
- The "main_descr.py" performs AL feature matching, adds new data to training dataset and retrains model with new augmented data. Its checkpoints are saved into ./local_data/{dataset}/runN/checkpoint.
- The run.py" can read these checkpoint files and perform AL iteration with retraining.
- The run_plot.py" generates performance curves that can be found in the paper.
- To make confusion matrices and t-SNE plots, use extra "visualize_tsne.py" script for MNIST only.
- VAAL code can be found in ./vaal folder, which is adopted version of official repo.
Running Active Learning Experiments
- Install minimal required packages from requirements.txt.
- The command interface for all methods is combined into "run.py" script. It can run multiple algorithms and data configurations.
- The script parameters may differ depending on the dataset and, hence, it is better to use "python3 run.py --help" command.
- First, you have to set configuration in cfg = list() according to its format and execute "run.py" script with "--initial" flag to generate initial random and unsupervised pretrained models.
- Second, the same script should be run without "--initial".
- Third, after all AL steps are executed, "run_plot.py" should be used to reproduce performance curves.
- All these steps require basic understanding of the AL terminology.
- Use the default configurations to reproduce paper results.
- To speed up or parallelize multiple runs, use --run-start, --run-stop parameters to limit number of runs saved in ./local_data/{dataset}/runN folders. The default setting is 10 runs for MNIST, 5 for SVHN and 1 for ImageNet.
pip3 install -U -r requirements.txt
python3 run.py --gpu 0 --initial # generate initial models
python3 run.py --gpu 0 --unsupervised 0 # AL with the initial all-random parameters model
python3 run.py --gpu 0 --unsupervised 1 # AL with the initial model pretrained using unsupervised rotation method
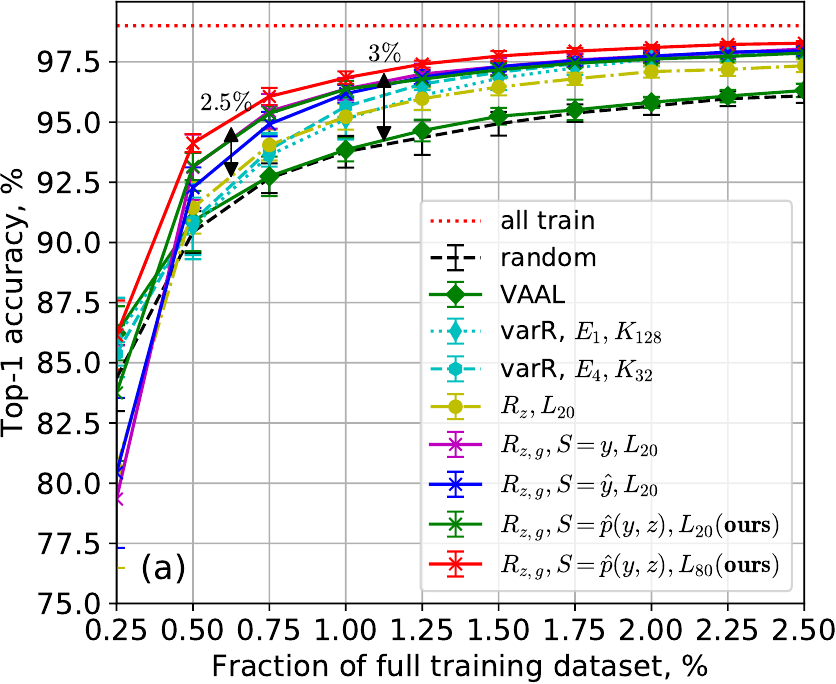
Reference Results
MNIST
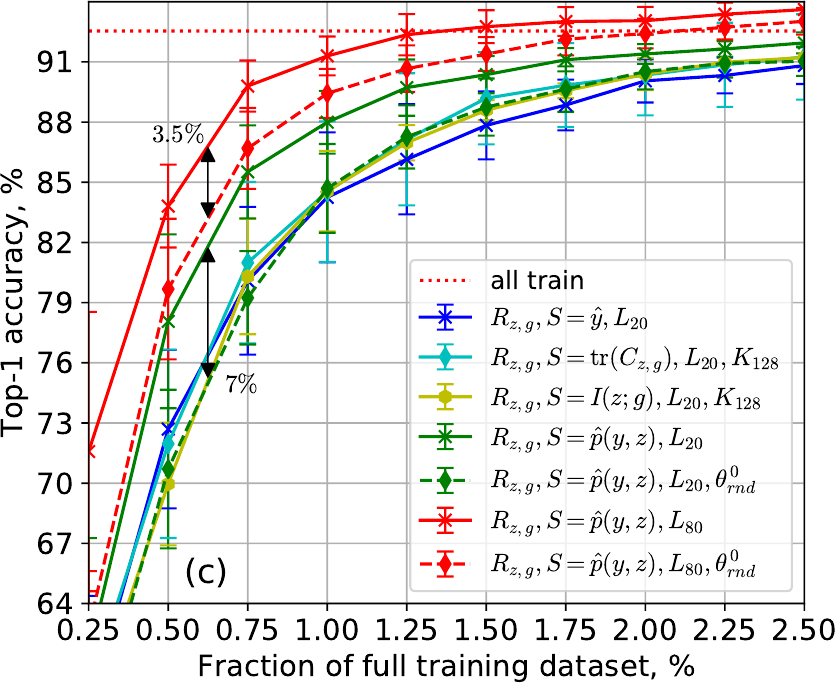
MNIST LeNet test accuracy: (a) no class imbalance, (b) 100x class imbalance, and (c) ablation study of pseudo-labeling and unsupervised pretraining (100x class imbalance). Our method decreases labeling by 40% compared to prior works for biased data.
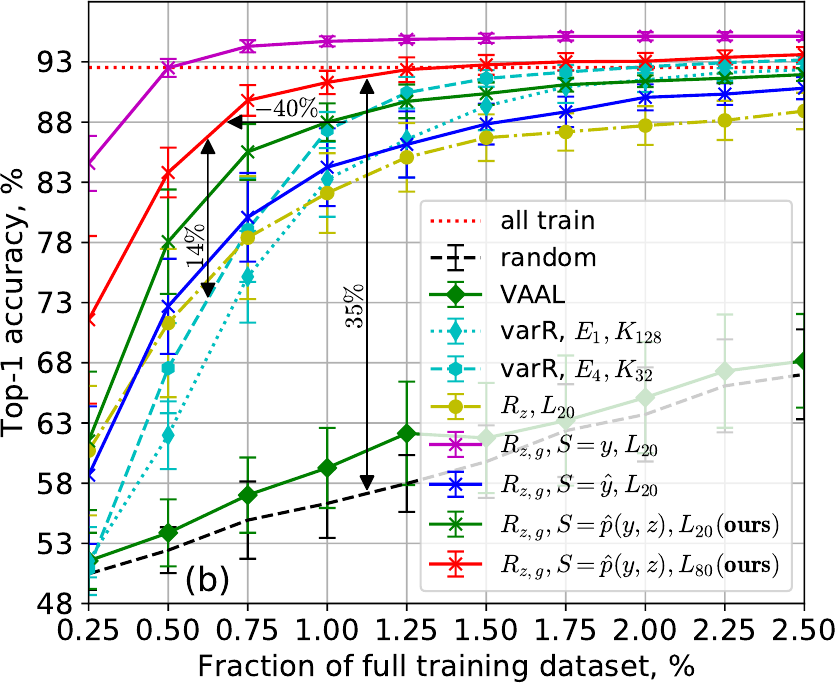
SVHN and ImageNet
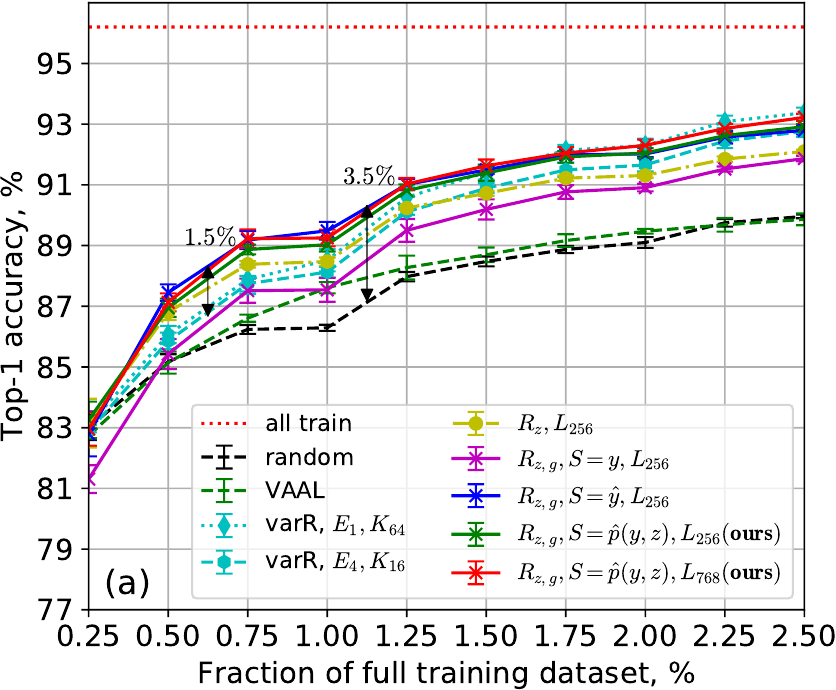
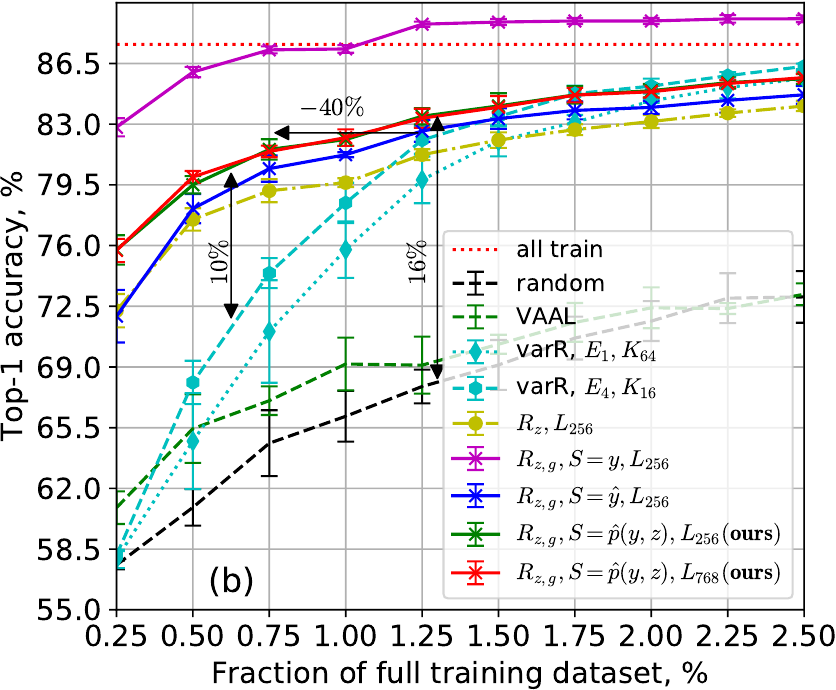
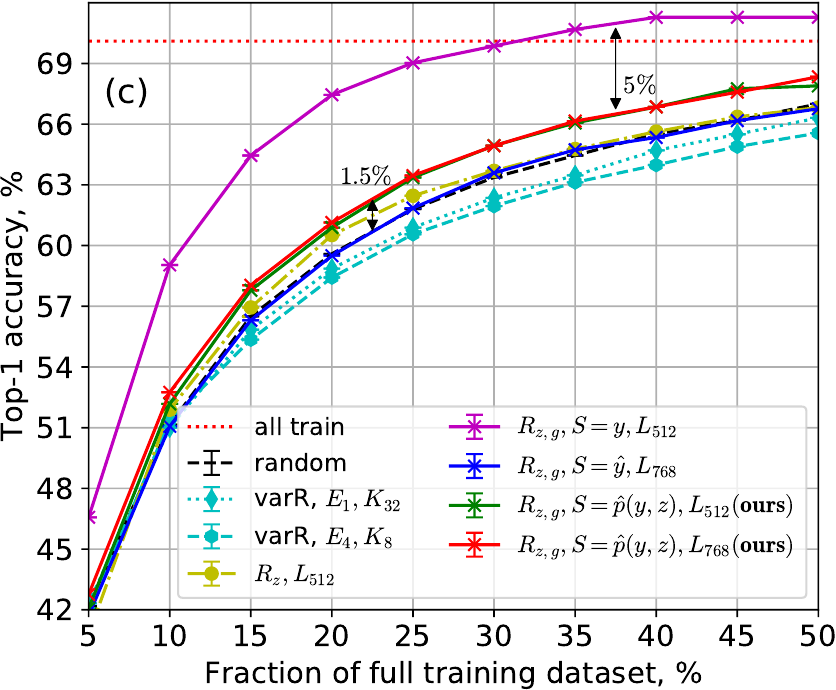
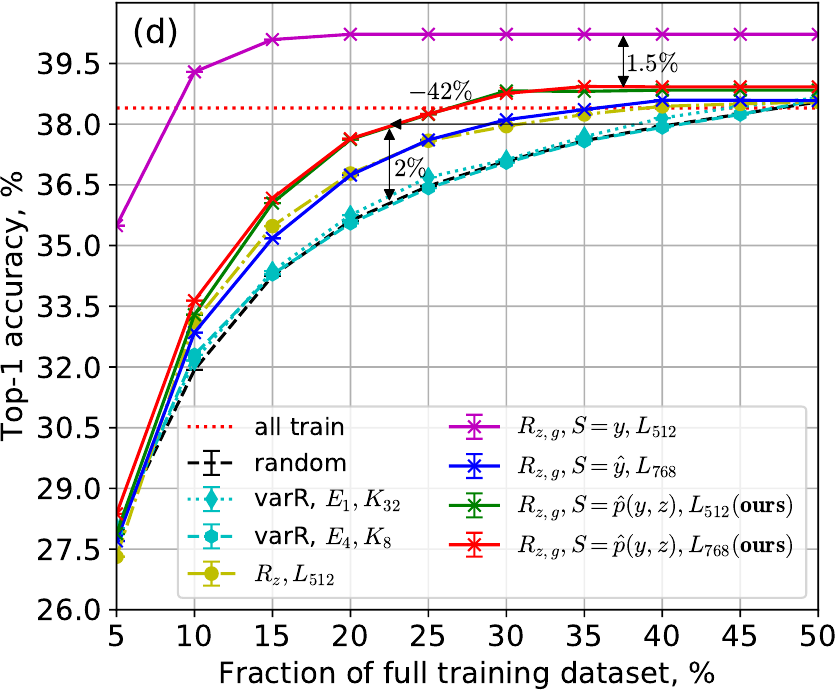
SVHN ResNet-10 test (top) and ImageNet ResNet-18 val (bottom) accuracy: (a,c) no class imbalance and (b,d) with 100x class imbalance.
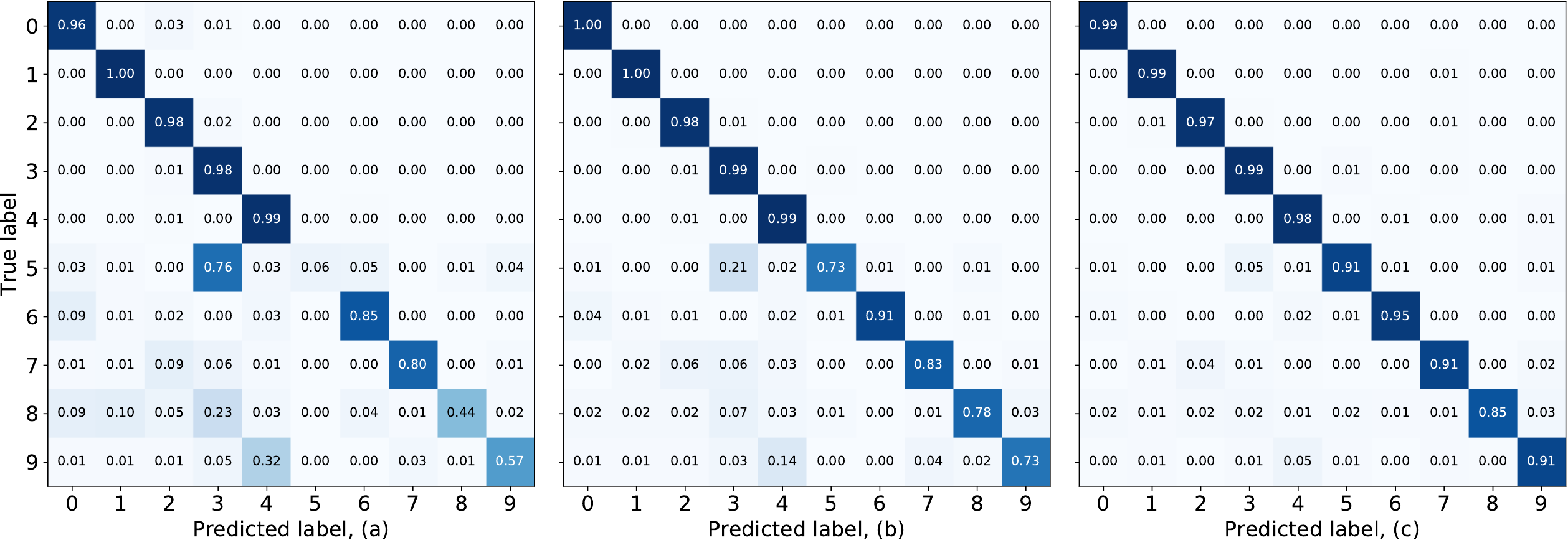
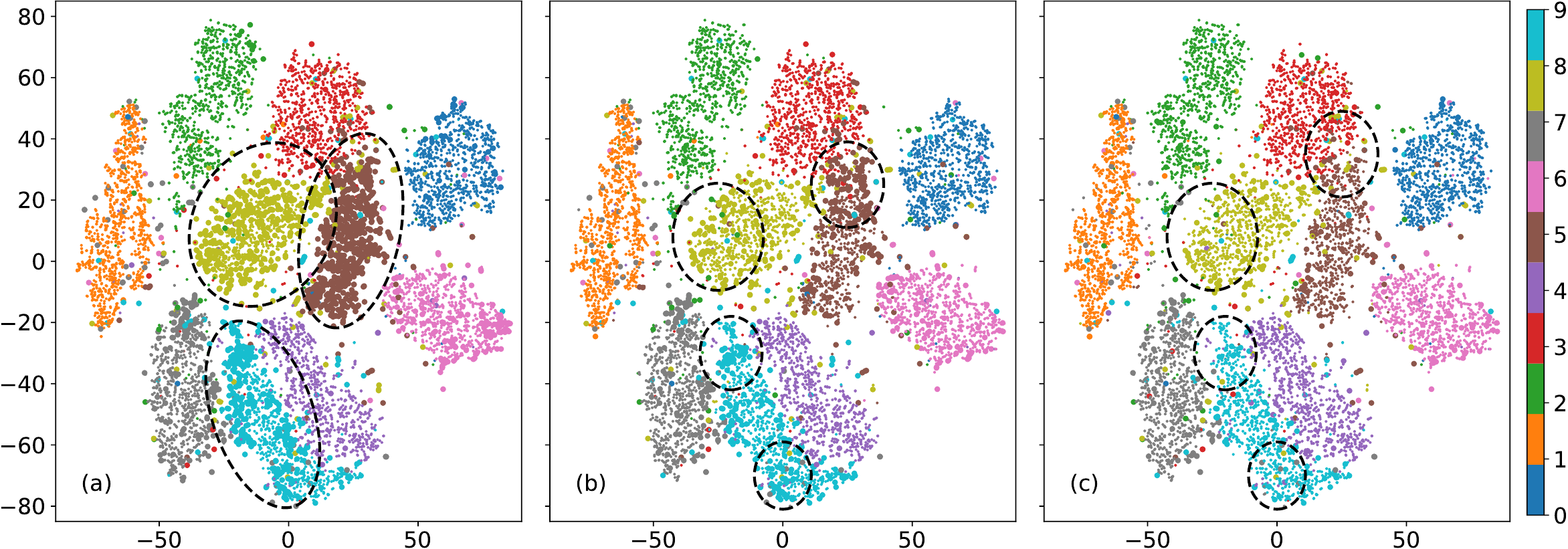
MNIST Visualizations
Confusion matrix (top) and t-SNE (bottom) of MNIST test data at AL iteration b=3 with 100x class imbalance for: (a) varR with E=1, K=128, (b) R_{z,g}, S=hat{p}(y,z), L=80 (ours), and (c) R_{z,g}, S=y, L=80. Dots and balls represent correspondingly correctly and incorrectly classified images for t-SNE visualizations. The underrepresented classes {5,8,9} have on average 36% accuracy for prior work (a), while our method (b) increases their accuracy to 75%. The ablation configuration (c) shows 89% theoretical limit of our method.