Deep-Reinforcement-Learning-Algorithms-with-PyTorch
This repository contains PyTorch implementations of deep reinforcement learning algorithms.
Algorithms Implemented
- Deep Q Learning (DQN) (Mnih 2013)
- DQN with Fixed Q Targets (Mnih 2013)
- Double DQN (Hado van Hasselt 2015)
- Double DQN with Prioritised Experience Replay (Schaul 2016)
- REINFORCE (Williams 1992)
- PPO (Schulman 2017)
- DDPG (Lillicrap 2016)
- Hill Climbing
- Genetic Evolution
- DQN with Hindsight Experience Replay (DQN-HER) (Andrychowicz 2018)
- DDPG with Hindsight Experience Replay (DDPG-HER) (Andrychowicz 2018)
All implementations are able to quickly solve Cart Pole (discrete actions), Mountain Car Continuous (continuous actions),
Bit Flipping (discrete actions with dynamic goals) or Fetch Reach (continuous actions with dynamic goals). I plan to add A2C, A3C and PPO-HER soon.
Results
a) Discrete Action Games
Cart Pole:
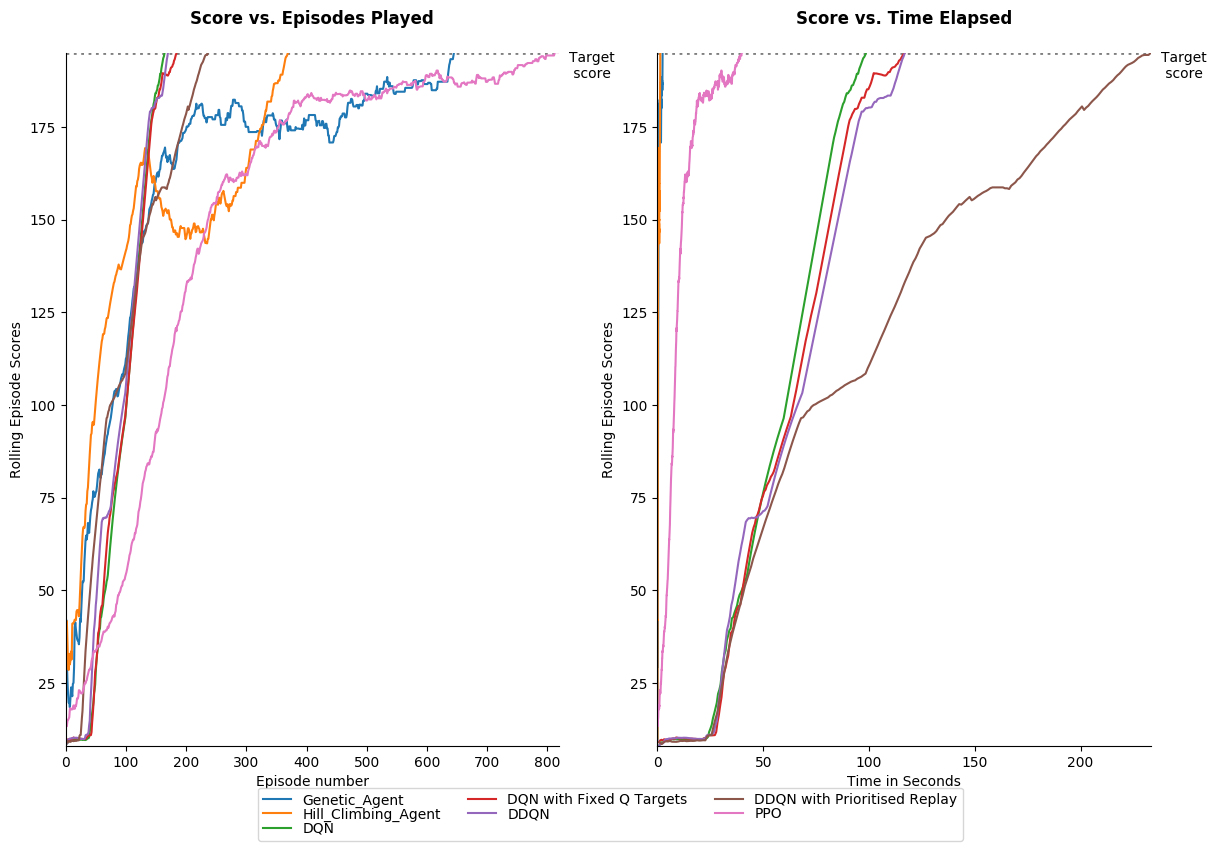
Below shows the number of episodes taken and also time taken for each algorithm to achieve the solution score for the game Cart Pole. Because results can vary greatly each run, each agent plays the game 10 times and we show the median result.
We show the results in terms of number of episodes taken to reach the required score
and also time taken. The algorithms were run on a 2017 Macbook Pro (no GPUs were used). The hyperparameters used are shown in the file Results/Cart_Pole/Results.py.
b) Continuous Action Games
Mountain Car
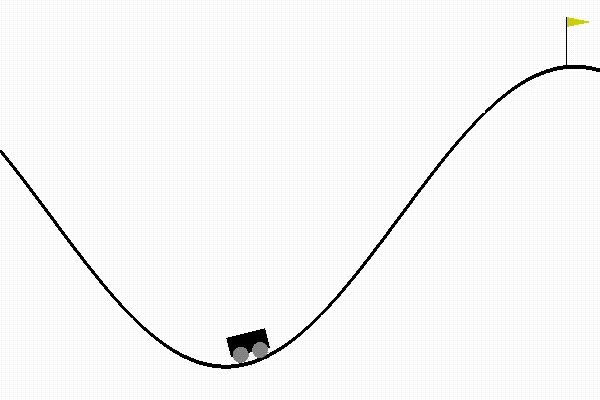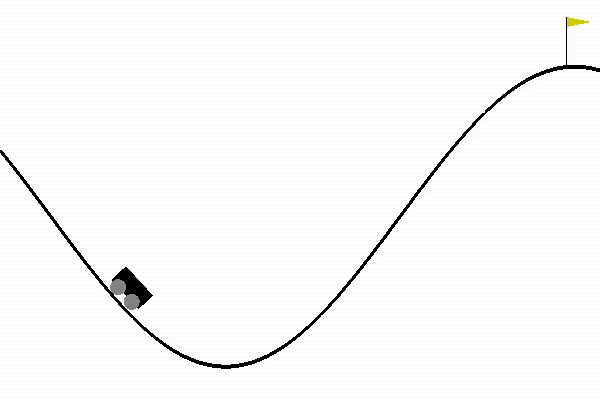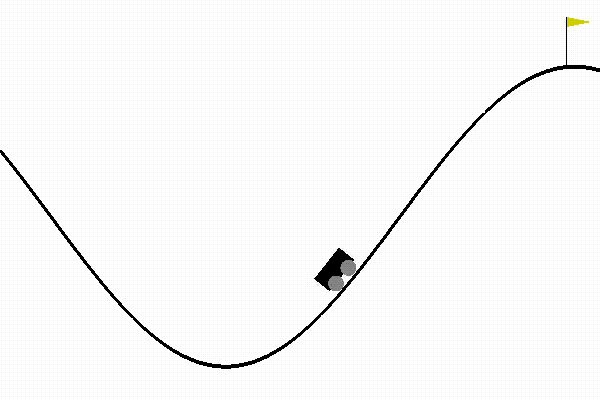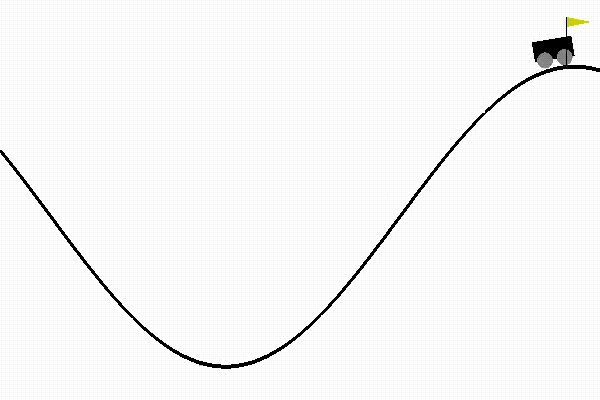
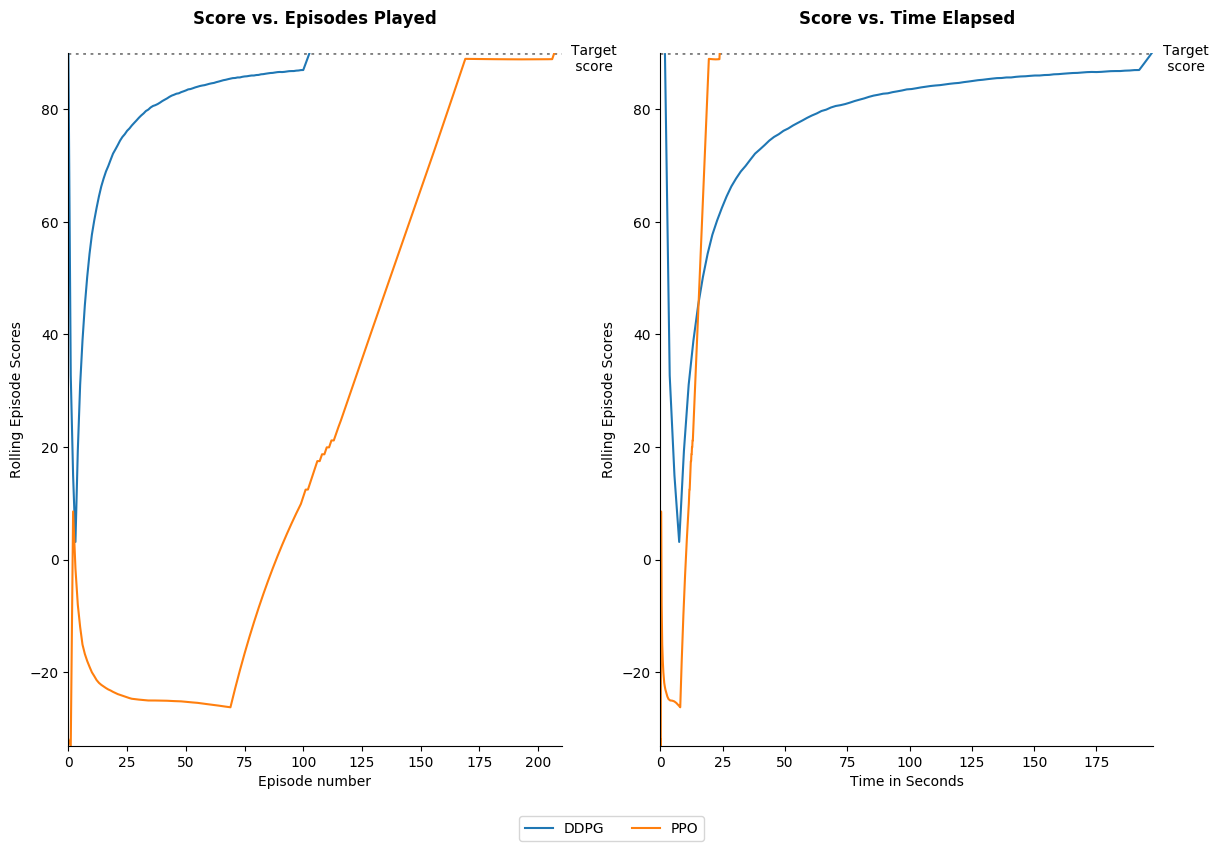
Here are the results for DDPG with respect to the Mountain Car (Continuous) game. The hyperparameters used are shown in the file Results/Mountain_Car_Continuous/Results.py.
Tennis
The Tennis environment is a multi-agent
cooperative environment where the goal of each agent is to hit the ball back to the other play as many times
as possible without the ball going out of play or hitting the ground.

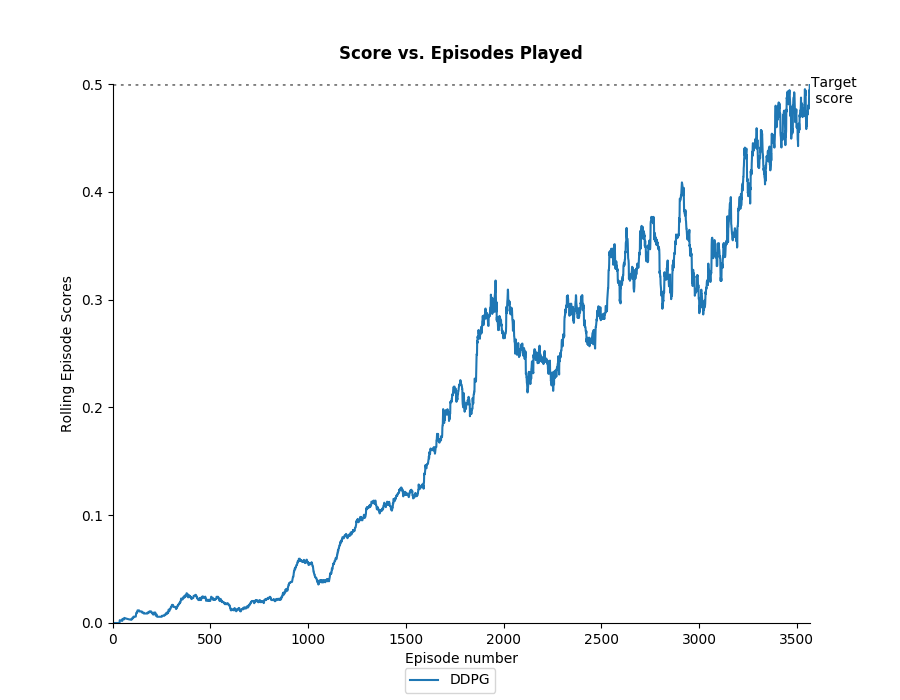
A DDPG agent was used to solve the environment with the results below. The hyperparameters used can be found in Results/Tennis/Results.py:

c) Hindsight Experience Replay (HER) Experiments
Bit Flipping
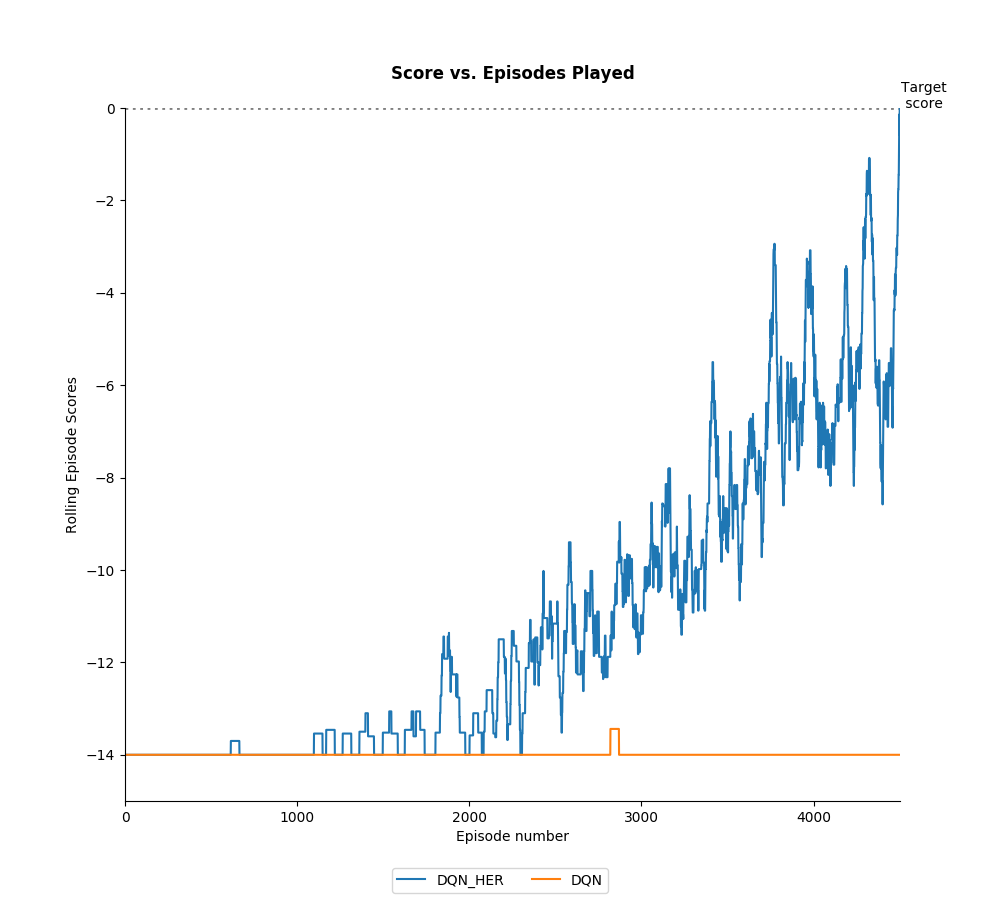
Below shows the performance of DQN with and without Hindsight Experience Replay (HER) in the Bit Flipping Environment (14 bits) described
in the paper Hindsight Experience Replay 2018. The results replicate the result
found in the paper and show that adding HER allowed the agent to solve a problem that vanilla DQN was not able
to practically solve. The hyperparameters used were the same for both agents and the same as in the paper, they can be found in the file: Results/Bit_Flipping/Results.py
Fetch Reach
Below shows the performance of DDPG with and without Hindsight Experience Replay in the Fetch Reach environment
which is introduced in this Open AI blog post. The results
mirror those seen in paper Multi-Goal Reinforcement Learning 2018 and show that adding Hindsight Experience Replay
dramatically improved the ability of the agent to learn the task. The hyperparameters used were the same for both agents and the same as in the paper, they can be found
in the file: Results/Fetch_Reach/Results.py
Usage
The repository's high-level structure is:
├── Agents
├── Actor_Critic_Agents
├── DQN_Agents
├── Policy_Gradient_Agents
└── Stochastic_Policy_Search_Agents
├── Environments
├── Open_AI_Gym_Environments
├── Other_Environments
└── Unity_Environments
├── Results
├── Bit_Flipping_Environment
├── Cart_Pole
├── Fetch_Reach
├── Mountain_Car_Continuous
└── Tennis
├── Tests
├── Utilities
├── Data_Structures
└── Models
i) To Watch the Agents Learn the Above Games
To watch all the different agents learn the above games follow these steps:
git clone https://github.com/p-christ/Deep_RL_Implementations.git
cd Deep_RL_Implementations
conda create --name myenvname
y
conda activate myenvname
pip3 install -r requirements.txt
export PYTHONPATH="${PYTHONPATH}:/Deep_RL_Implementations"
And then to watch them learn Cart Pole run:
python Results/Cart_Pole/Results.py
To watch them learn Mountain Car run: python Results/Mountain_Car_Continuous/Results.py
To watch them learn Tennis you will need to download the environment:
- Linux: click here
- Mac OSX: click here
- Windows (32-bit): click here
- Windows (64-bit): click here
and then run: python Results/Tennis/Results.py
To watch them learn Bit Flipping run: python Results/Bit_Flipping/Results.py
To watch them learn Fetch Reach run: python Results/Fetch_Reach/Results.py
ii) To Train the Agents on your Own Game
To use the algorithms with your own particular game instead you follow these steps:
-
Create an Environment class to represent your game - the environment class you create should extend the
Base_Environmentclass found in theEnvironmentsfolder to make
it compatible with all the agents. -
Create a config object with the hyperparameters and game you want to use. See
Results/Cart_Pole/Results.pyfor an example of this. -
Use function
run_games_for_agentsto have the different agents play the game. Again seeResults/Cart_Pole/Results.pyfor an example of this.



