Delving into Deep Imbalanced Regression
This repository contains the implementation code for paper:
Delving into Deep Imbalanced Regression
Yuzhe Yang, Kaiwen Zha, Ying-Cong Chen, Hao Wang, Dina Katabi
38th International Conference on Machine Learning (ICML 2021), Long Oral
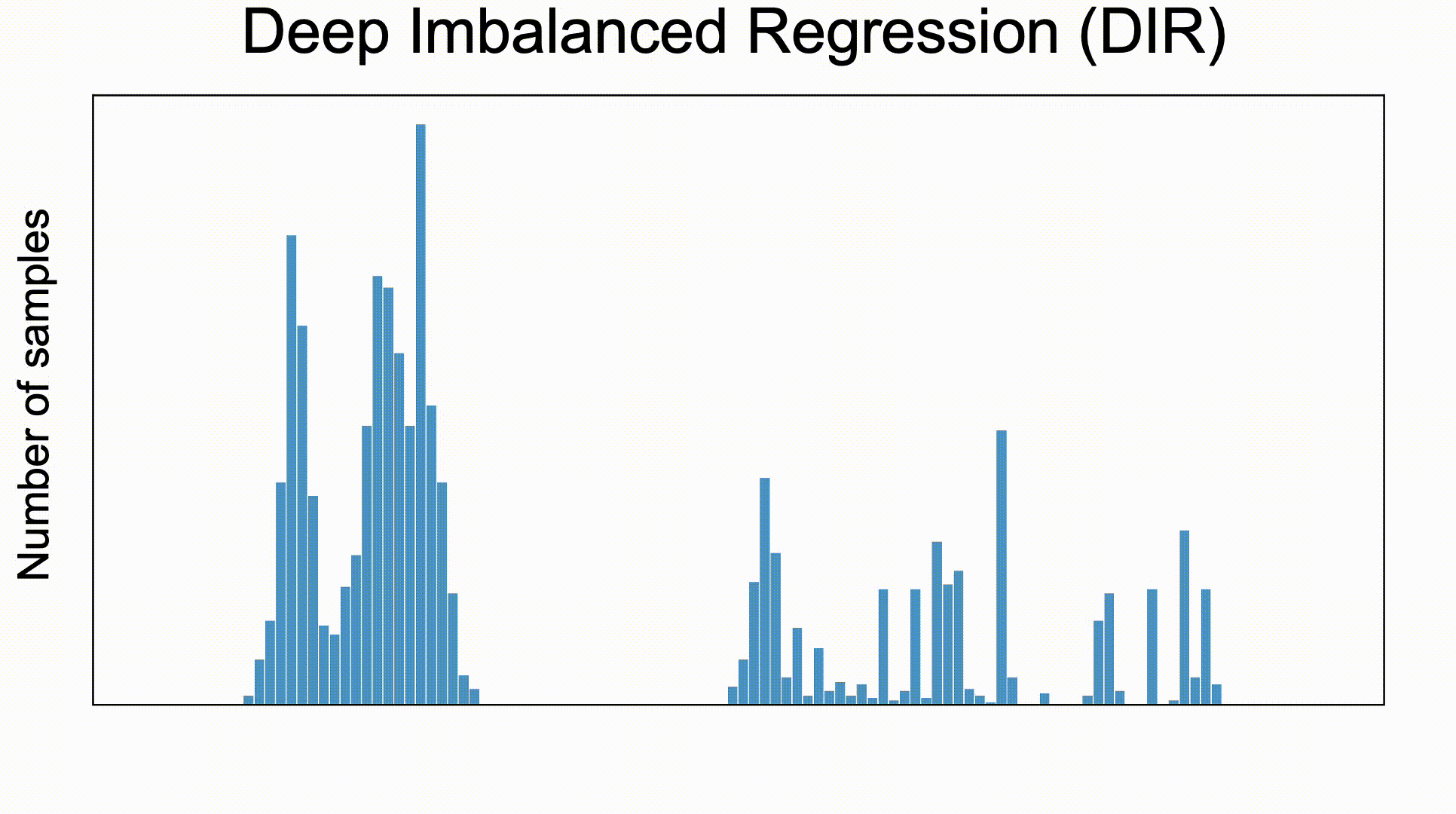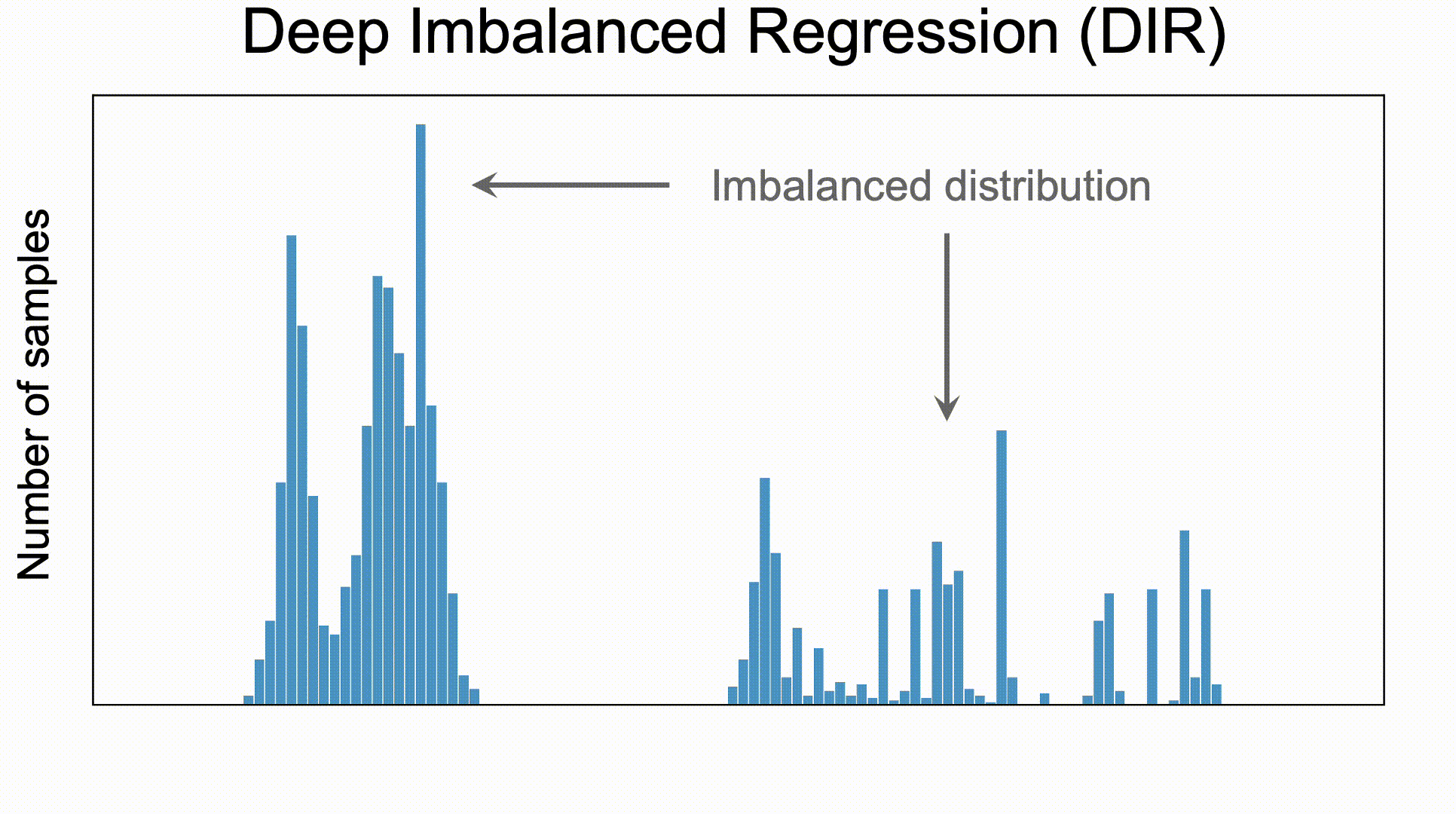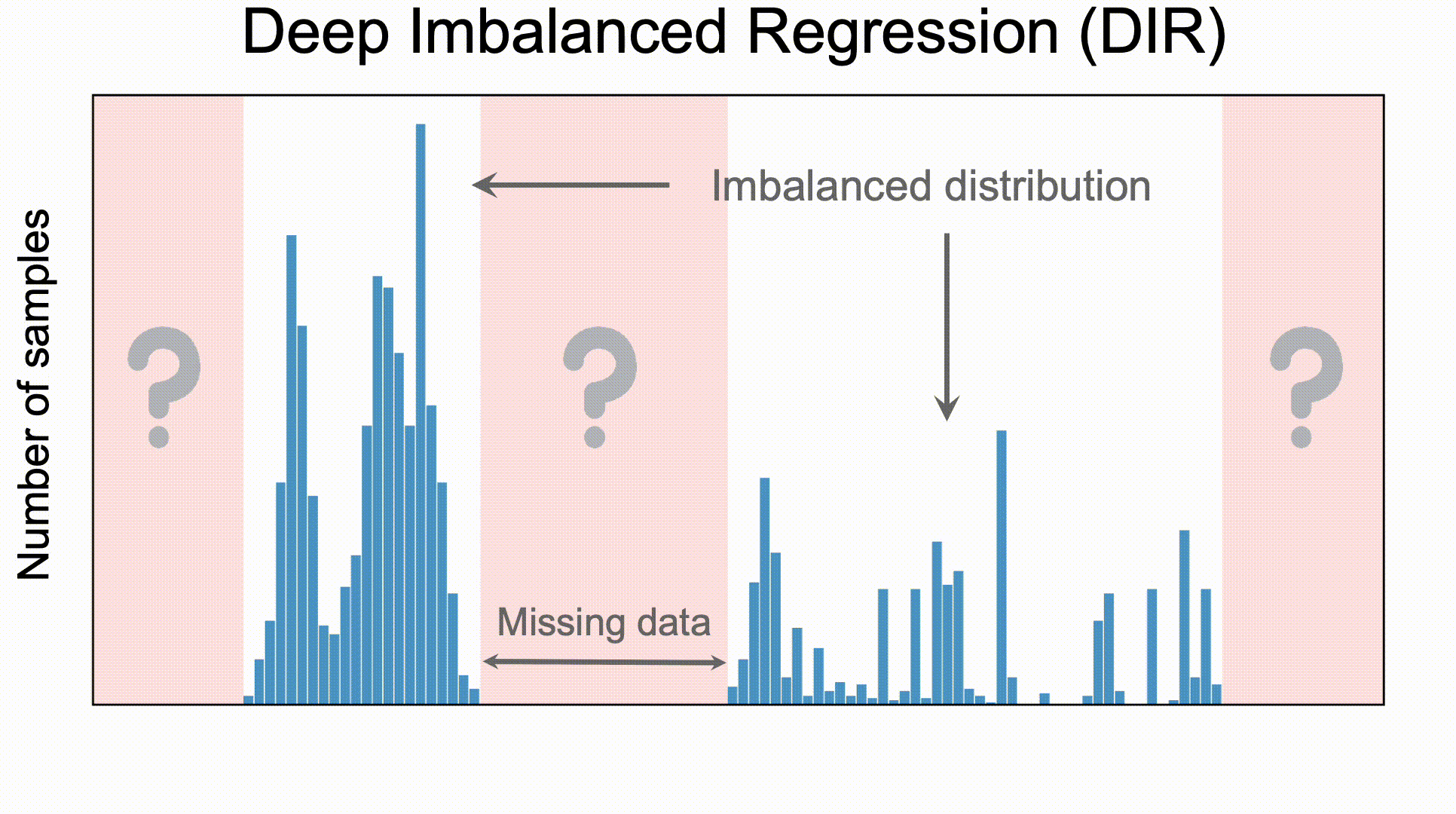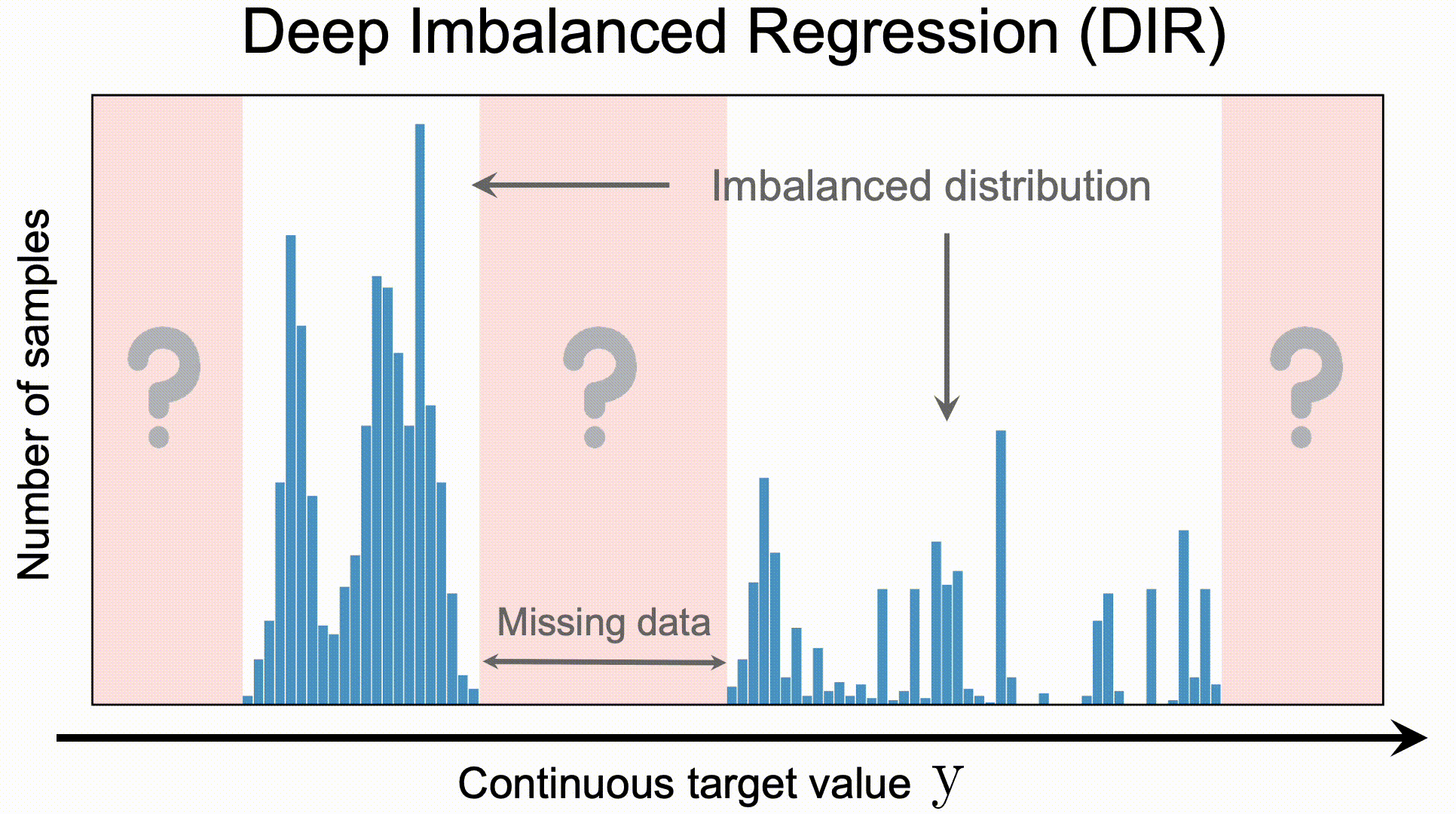
Deep Imbalanced Regression (DIR) aims to learn from imbalanced data with continuous targets,
tackle potential missing data for certain regions, and generalize to the entire target range.
Beyond Imbalanced Classification: Brief Introduction for DIR
Existing techniques for learning from imbalanced data focus on targets with categorical indices, i.e., the targets are different classes. However, many real-world tasks involve continuous and even infinite target values. We systematically investigate Deep Imbalanced Regression (DIR), which aims to learn continuous targets from natural imbalanced data, deal with potential missing data for certain target values, and generalize to the entire target range.
We curate and benchmark large-scale DIR datasets for common real-world tasks in computer vision, natural language processing, and healthcare domains, ranging from single-value prediction such as age, text similarity score, health condition score, to dense-value prediction such as depth.
Usage
We separate the codebase for different datasets into different subfolders. Please go into the subfolders for more information (e.g., installation, dataset preparation, training, evaluation & models).
IMDB-WIKI-DIR | AgeDB-DIR | NYUD2-DIR | STS-B-DIR
Highlights
(1) :heavy_check_mark: New Task: Deep Imbalanced Regression (DIR)
(2) :heavy_check_mark: New Techniques:
 |
 |
|---|---|
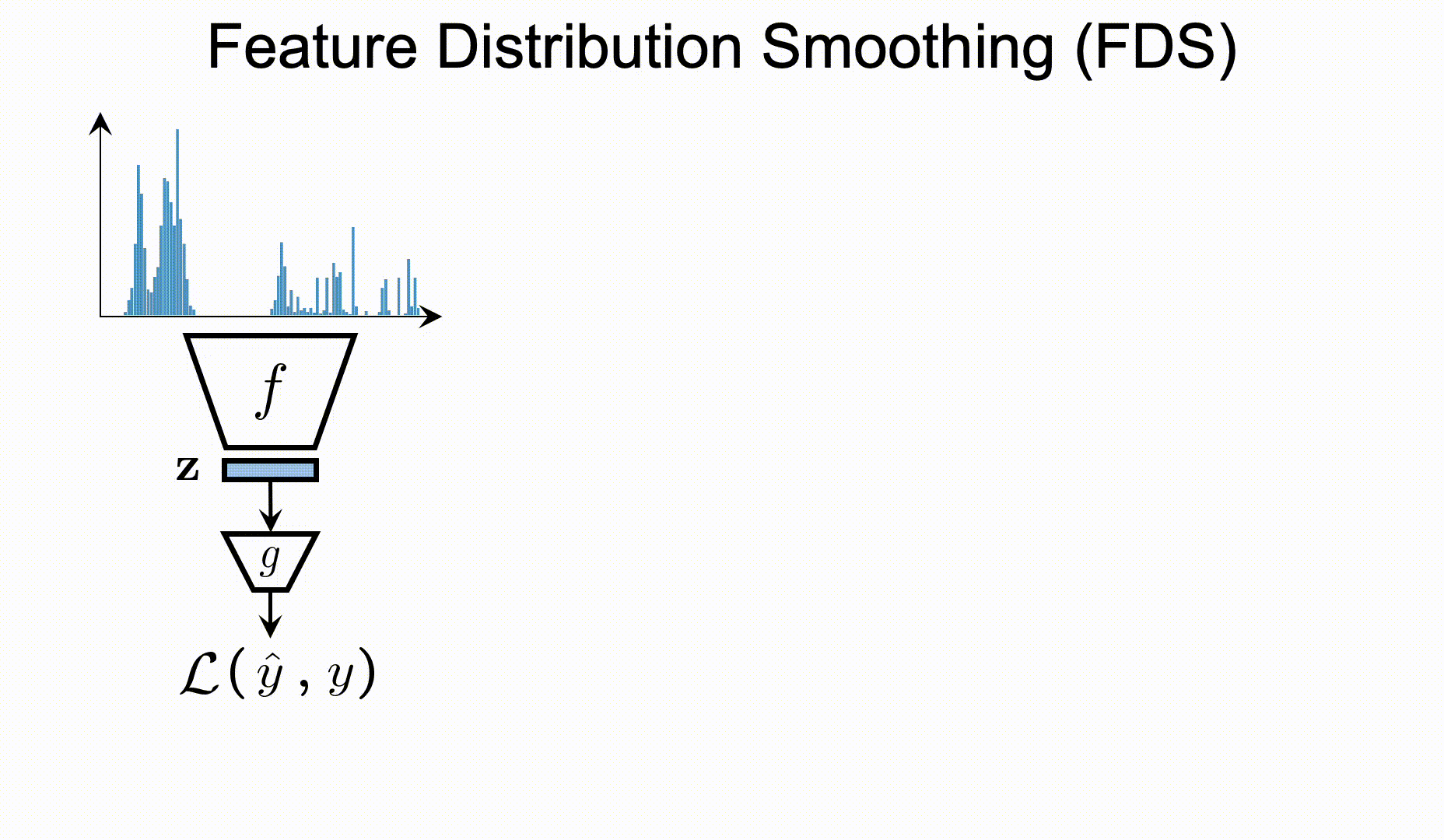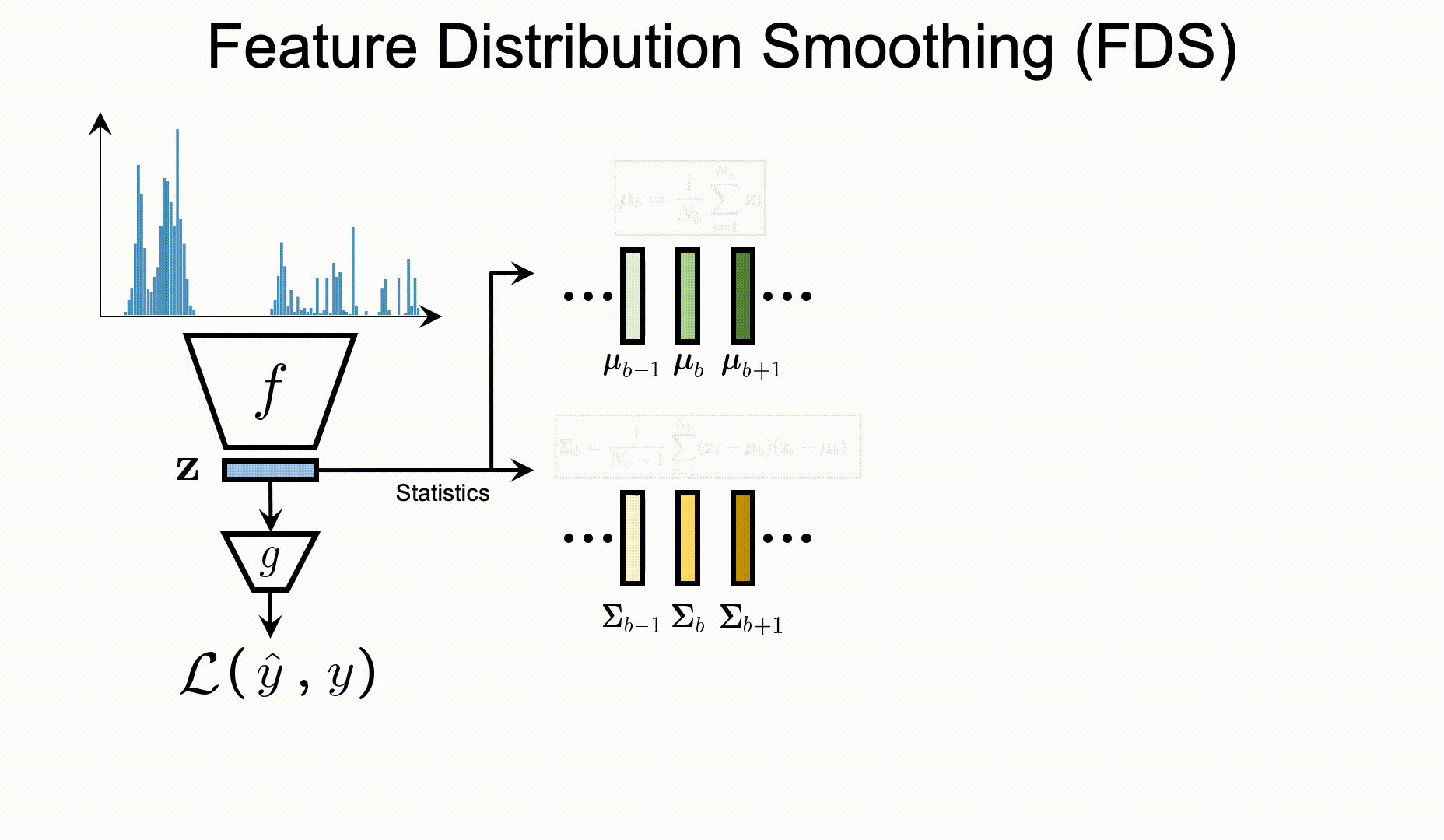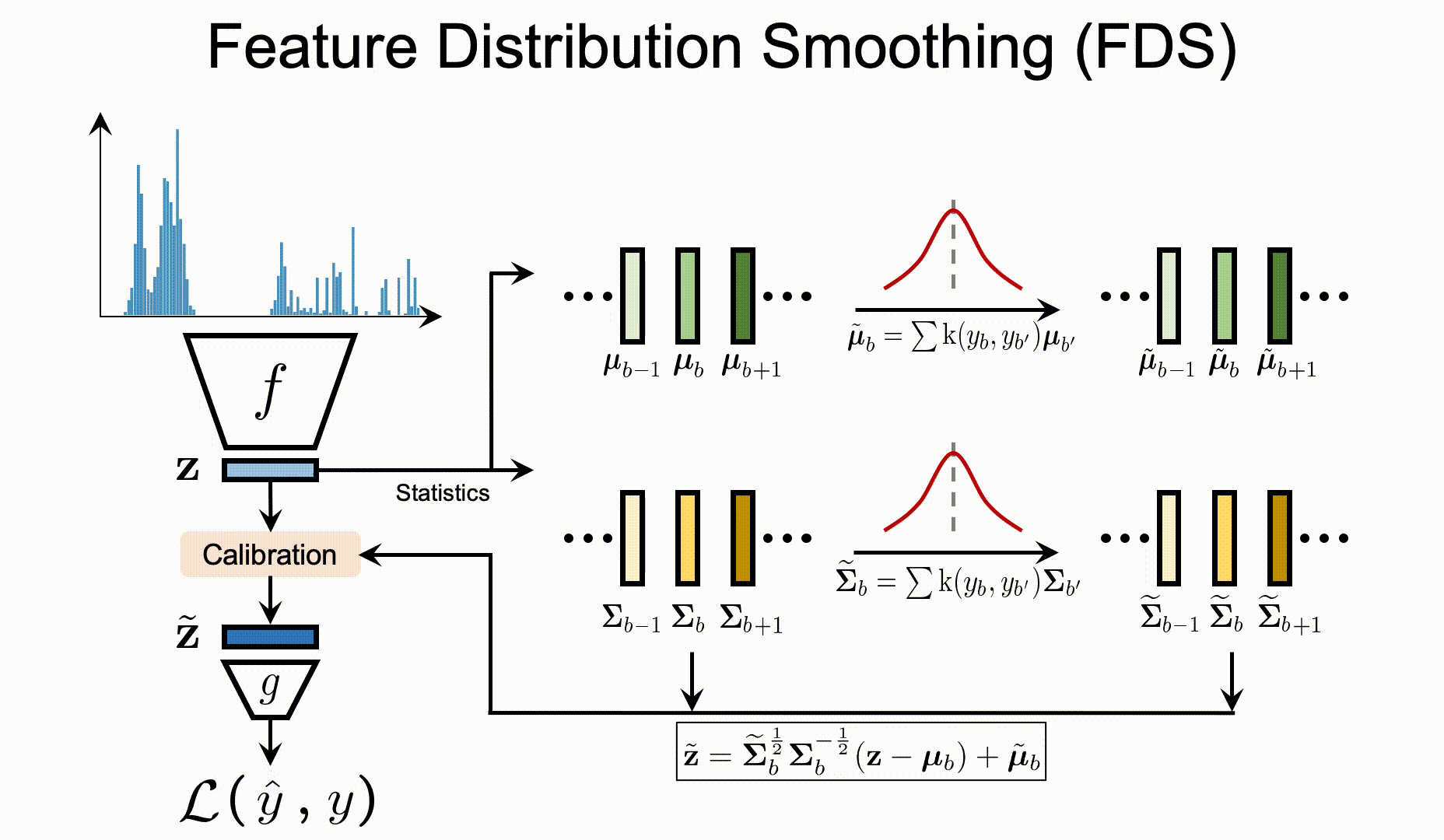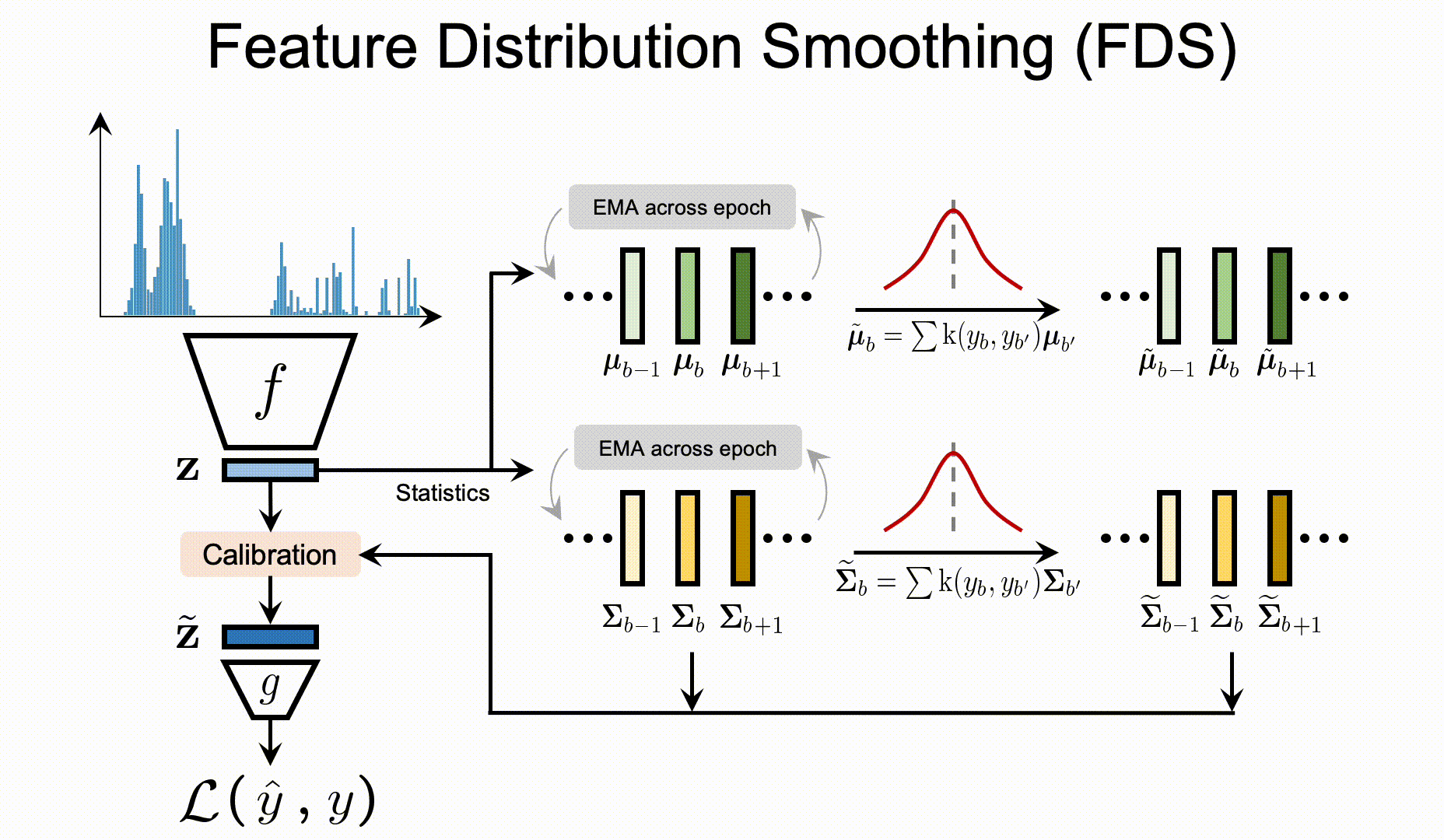
| Label distribution smoothing (LDS) | Feature distribution smoothing (FDS) |
(3) :heavy_check_mark: New Benchmarks:
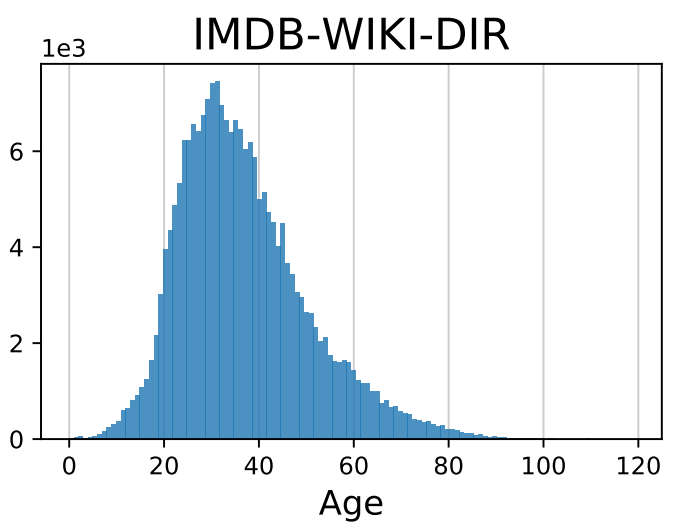
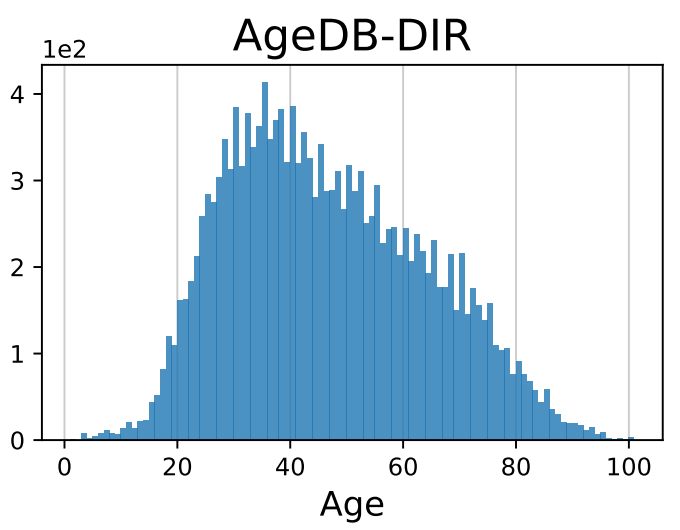
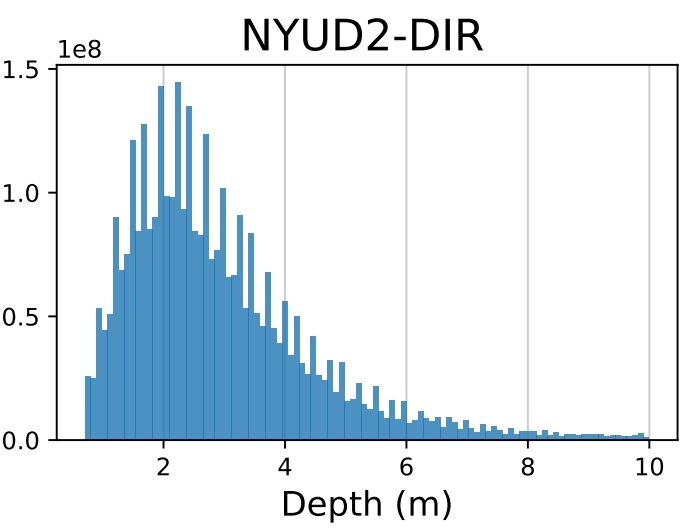
- Computer Vision: :bulb: IMDB-WIKI-DIR (age) / AgeDB-DIR (age) / NYUD2-DIR (depth)
- Natural Language Processing: :clipboard: STS-B-DIR (text similarity score)
- Healthcare: :hospital: SHHS-DIR (health condition score)
| IMDB-WIKI-DIR | AgeDB-DIR | NYUD2-DIR | STS-B-DIR | SHHS-DIR |
|---|---|---|---|---|
 |
 |
 |
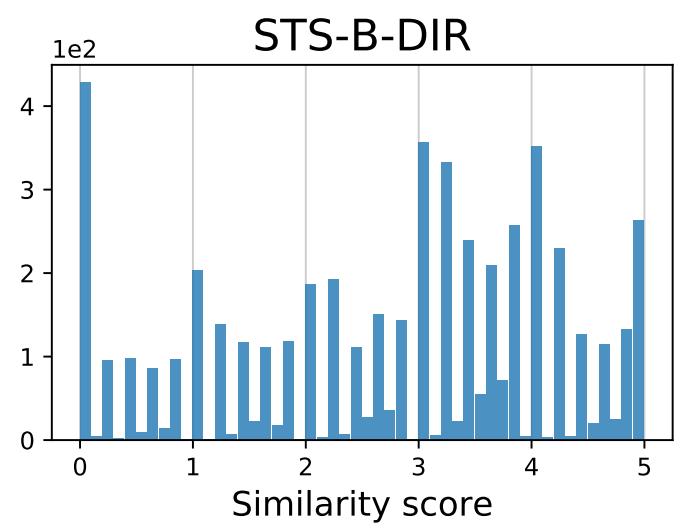 |
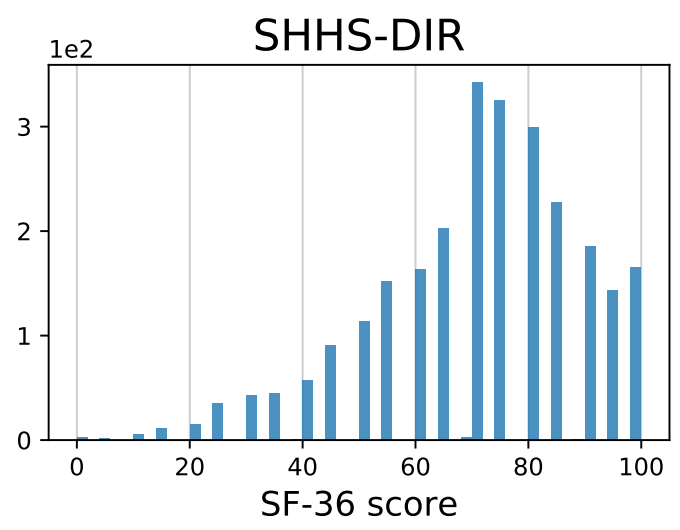 |
Apply LDS and FDS on Other Datasets / Models
We provide examples of how to apply LDS and FDS on other customized datasets and/or models.
LDS
To apply LDS on your customized dataset, you will first need to estimate the effective label distribution:
from collections import Counter
from scipy.ndimage import convolve1d
from utils import get_lds_kernel_window
# preds, labels: [Ns,], "Ns" is the number of total samples
preds, labels = ..., ...
# assign each label to its corresponding bin (start from 0)
# with your defined get_bin_idx(), return bin_index_per_label: [Ns,]
bin_index_per_label = [get_bin_idx(label) for label in labels]
# calculate empirical (original) label distribution: [Nb,]
# "Nb" is the number of bins
Nb = max(bin_index_per_label) + 1
num_samples_of_bins = dict(Counter(bin_index_per_label))
emp_label_dist = [num_samples_of_bins.get(i, 0) for i in Nb]
# lds_kernel_window: [ks,], here for example, we use gaussian, ks=5, sigma=2
lds_kernel_window = get_lds_kernel_window(kernel='gaussian', ks=5, sigma=2)
# calculate effective label distribution: [Nb,]
eff_label_dist = convolve1d(np.array(emp_label_dist), weights=lds_kernel_window, mode='constant')
With the estimated effective label distribution, one straightforward option is to use the loss re-weighting scheme:
from loss import weighted_mse_loss
# Use re-weighting based on effective label distribution, sample-wise weights: [Ns,]
eff_num_per_label = [eff_label_dist[bin_idx] for bin_idx in bin_index_per_label]
weights = [np.float32(1 / x) for x in eff_num_per_label]
# calculate loss
loss = weighted_mse_loss(preds, labels, weights=weights)
FDS
To apply FDS on your customized data/model, you will first need to define the FDS module in your network:
from fds import FDS
config = dict(feature_dim=..., start_update=0, start_smooth=1, kernel='gaussian', ks=5, sigma=2)
def Network(nn.Module):
def __init__(self, **config):
super().__init__()
self.feature_extractor = ...
self.regressor = nn.Linear(config['feature_dim'], 1) # FDS operates before the final regressor
self.FDS = FDS(**config)
def forward(self, inputs, labels, epoch):
features = self.feature_extractor(inputs) # features: [batch_size, feature_dim]
# smooth the feature distributions over the target space
smoothed_features = features
if self.training and epoch >= config['start_smooth']:
smoothed_features = self.FDS.smooth(smoothed_features, labels, epoch)
preds = self.regressor(smoothed_features)
return {'preds': preds, 'features': features}
During training, you will need to update the FDS statistics after each training epoch:
model = Network(**config)
for epoch in range(num_epochs):
for (inputs, labels) in train_loader:
# standard training pipeline
...
# update FDS statistics after each training epoch
if epoch >= config['start_update']:
# collect features and labels for all training samples
...
# training_features: [num_samples, feature_dim], training_labels: [num_samples,]
training_features, training_labels = ..., ...
model.FDS.update_last_epoch_stats(epoch)
model.FDS.update_running_stats(training_features, training_labels, epoch)
Citation
If you find this code or idea useful, please cite our work:
@inproceedings{yang2021delving,
title={Delving into Deep Imbalanced Regression},
author={Yang, Yuzhe and Zha, Kaiwen and Chen, Ying-Cong and Wang, Hao and Katabi, Dina},
booktitle={International Conference on Machine Learning (ICML)},
year={2021}
}
Contact
If you have any questions, feel free to contact us through email ([email protected] & [email protected]) or Github issues. Enjoy!








