ECA-Net: Efficient Channel Attention
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks.
This is an implementation of ECA-Net, created by Banggu Wu.
Channel attention has recently demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules to achieve better performance, inevitably increasing the computational burden. To overcome the paradox of performance and complexity trade-off, this paper makes an attempt to investigate an extremely lightweight attention module for boosting the performance of deep CNNs. In particular, we propose an Efficient Channel Attention (ECA) module, which only involves k (k<=9) parameters but brings clear performance gain. By revisiting the channel attention module in SENet, we empirically show avoiding dimensionality reduction and appropriate cross-channel interaction are important to learn effective channel attention. Therefore, we propose a local cross-channel interaction strategy without dimension reduction, which can be efficiently implemented by a fast 1D convolution. Furthermore, we develop a function of channel dimension to adaptively determine kernel size of 1D convolution, which stands for coverage of local cross-channel interaction. Our ECA module can be flexibly incorporated into existing CNN architectures, and the resulting CNNs are named by ECA-Net.We extensively evaluate the proposed ECA-Net on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our ECA-Net is more efficient while performing favorably against its counterparts.
Citation
@article{wang2019eca,
title={ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks},
author={Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo and Qinghua Hu},
journal={arXiv:1910.03151},
year={2019}
}
ECA module
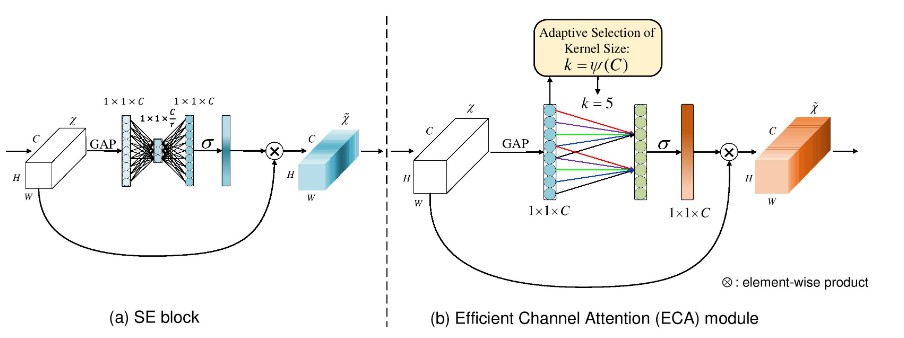
Comparison of (a) SE block and (b) our efficient channel attention (ECA) module. Given the aggregated feature using global average pooling (GAP), SE block computes weights using two FC layers. Differently, ECA generates channel weights by performing a fast 1D convolution of size k, where k is adaptively determined via a function of channel dimension C.
Installation
Requirements
- Python 3.5+
- PyTorch 1.0+
- thop
Our environments
- OS: Ubuntu 16.04
- CUDA: 9.0/10.0
- Toolkit: PyTorch 1.0/1.1
- GPU: GTX 2080Ti/TiTan XP
Start Up
Train with ResNet
You can run the main.py to train or evaluate as follow:
CUDA_VISIBLE_DEVICES={device_ids} python main -a {model_name} --ksize {eca_kernel_size} {the path of you datasets}
For example:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main -a eca_resnet50 --ksize 3557 ./datasets/ILSVRC2012/images
Train with MobileNet_v2
It is same with above ResNet replace main.py by light_main.py.
Compute the parameters and FLOPs
If you have install thop, you can paras_flosp.py to compute the parameters and FLOPs of our models. The usage is below:
python paras_flops.py -a {model_name}
Experiments
ImageNet
| Model | Param. | FLOPs | Top-1(%) | Top-5(%) | Pre trained models | Extract code |
|---|---|---|---|---|---|---|
| ECA-Net50 | 24.37M | 3.86G | 77.48 | 93.68 | eca_resnet50_k3557 | 7qo9 |
| ECA-Net101 | 42.49M | 7.35G | 78.65 | 94.34 | eca_resnet101_k3357 | mvg2 |
| ECA-Net152 | 57.41M | 10.83G | 78.92 | 94.55 | eca_resnet152_k3357 | ysh9 |
| ECA-MobileNet_v2 | 3.34M | 319.9M | 72.56 | 90.81 | eca_mobilenetv2_k13 | atpt |
COCO 2017
Detection with Faster R-CNN and Mask R-CNN
| Model | Param. | FLOPs | AP | AP_50 | AP_75 | Pre trained models | Extract code |
|---|---|---|---|---|---|---|---|
| Fast_R-CNN_ecanet50 | 41.53M | 207.18G | 38.0 | 60.6 | 40.9 | faster_rcnn_ecanet50_k5_bs8_lr0.01 | pmq9 |
| Fast_R-CNN_ecanet101 | 60.52M | 283.32G | 40.3 | 62.9 | 44.0 | faster_rcnn_ecanet101_3357_bs8_lr0.01 | yk8o |
| Mask_R-CNN_ecanet50 | 44.18M | 275.69G | 39.0 | 61.3 | 42.1 | mask_rcnn_ecanet50_k3377_bs8_lr0.01 | gbx2 |
| Mask_R-CNN_ecanet101 | 63.17M | 351.83G | 41.3 | 63.1 | 44.8 | mask_rcnn_ecanet101_k3357_bs8_lr0.01 | wywx |
Instance segmentation with Mask R-CNN
| Model | Param. | FLOPs | AP | AP_50 | AP_75 | Pre trained models | Extract code |
|---|---|---|---|---|---|---|---|
| Mask_R-CNN_ecanet50 | 44.18M | 275.69G | 35.6 | 58.1 | 37.7 | mask_rcnn_ecanet50_k3377_bs8_lr0.01 | gbx2 |
| Mask_R-CNN_ecanet101 | 63.17M | 351.83G | 37.4 | 59.9 | 39.8 | mask_rcnn_ecanet101_k3357_bs8_lr0.01 | wywx |





