Geometry-aware Instance-reweighted Adversarial Training
This repository provides codes for Geometry-aware Instance-reweighted Adversarial Training (https://openreview.net/forum?id=iAX0l6Cz8ub) (ICLR oral)
Jingfeng Zhang, Jianing Zhu, Gang Niu, Bo Han, Masashi Sugiyama and Mohan Kankanhalli
What is the nature of adversarial training?
Adversarial training employs adversarial data for updating the models.
For more details of the nature of adversarial training, refer to this FAT's GitHub for the preliminary.
In this repo, you will know:
FACT 1: Model Capacity is NOT enough for adversarial training.
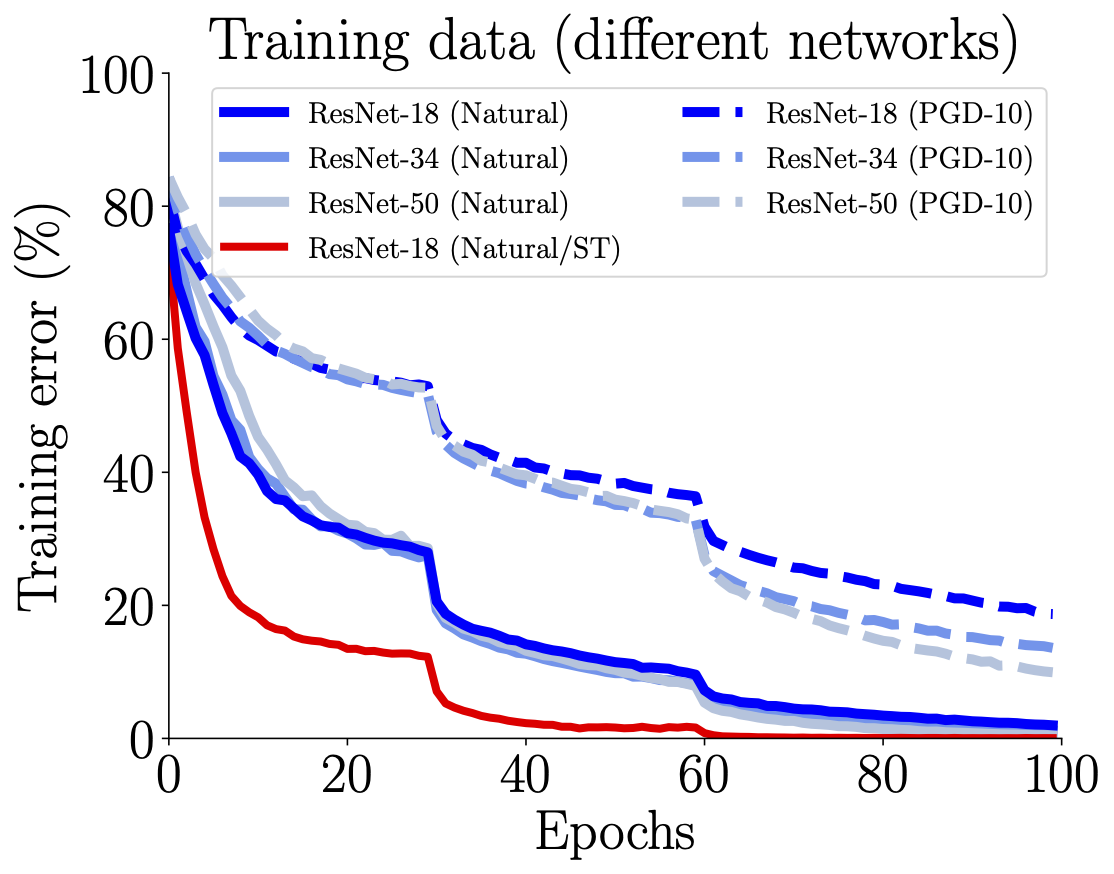
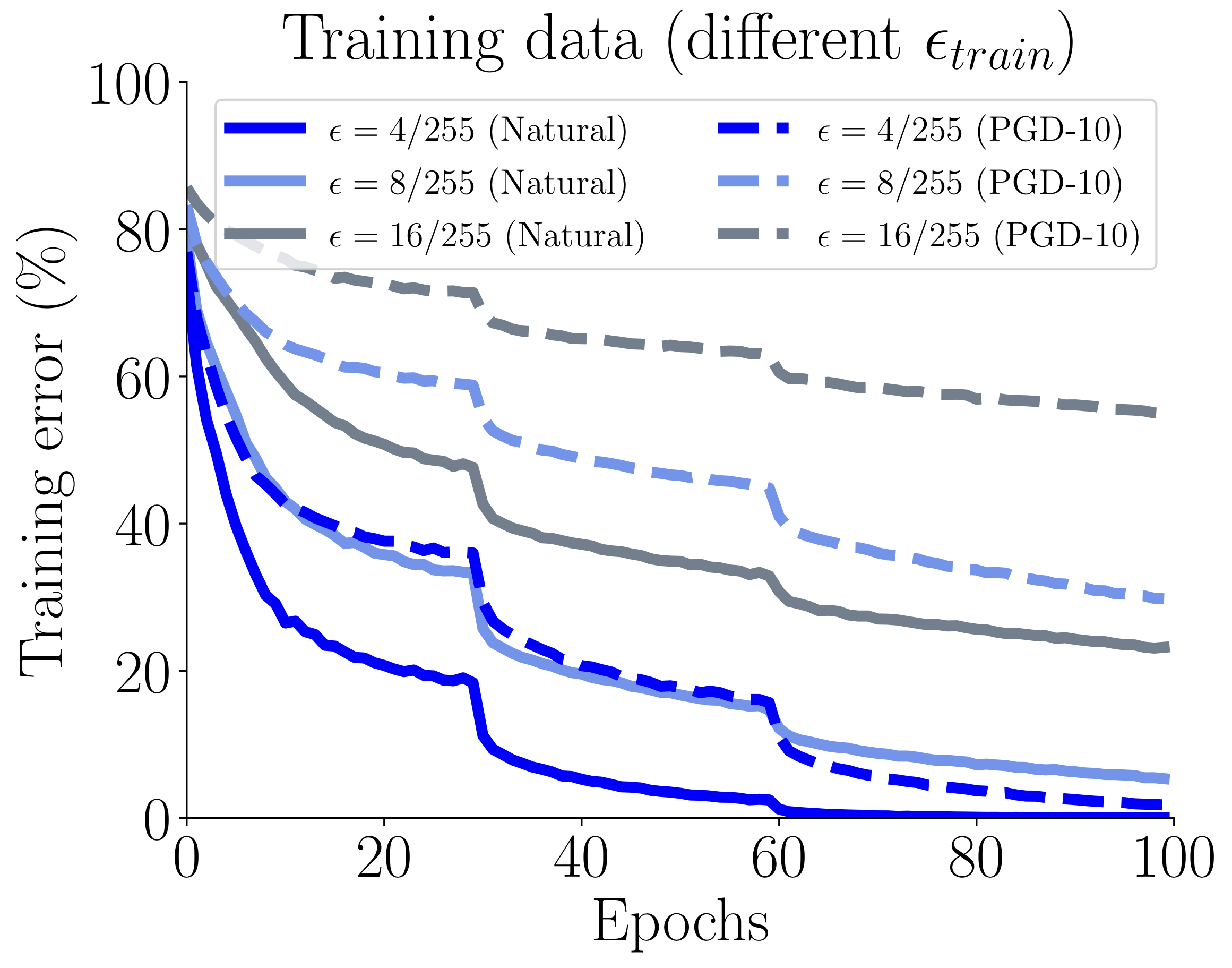
We plot standard training error (Natural) and adversarial training error (PGD-10) over the training epochs of the standard AT (Madry's) on CIFAR-10 dataset. *Left panel*: AT on different sizes of network (blue lines) and standard training (ST, the red line) on ResNet-18. *Right panel*: AT on ResNet-18 under different perturbation bounds eps_train.
Refer to FAT's GitHub for the standard AT by setting
python FAT.py --epsilon 0.031 --net 'resnet18' --tau 10 --dynamictau False
OR using codes in this repo by setting
python GAIRAT.py --epsilon 0.031 --net 'resnet18' --Lambda 'inf'
to recover the standard AT (Madry's).
The over-parameterized models that fit nataral data entirely in the standard training (ST) are still far from enough for fitting adversarial data in adversarial training (AT).
Compared with ST fitting the natural data points, AT smooths the neighborhoods of natural data, so that adversarial data consume significantly more model capacity than natural data.
The volume of this neighborhood is exponentially large w.r.t. the input dimension
, even if
is small.
Under the computational budget of 100 epochs, the networks hardly reach zero error on the adversarial training data.
FACT 2: Data points are inherently different.
More attackable data are closer to the decision boundary.
More guarded data are farther away from the decision boundary.
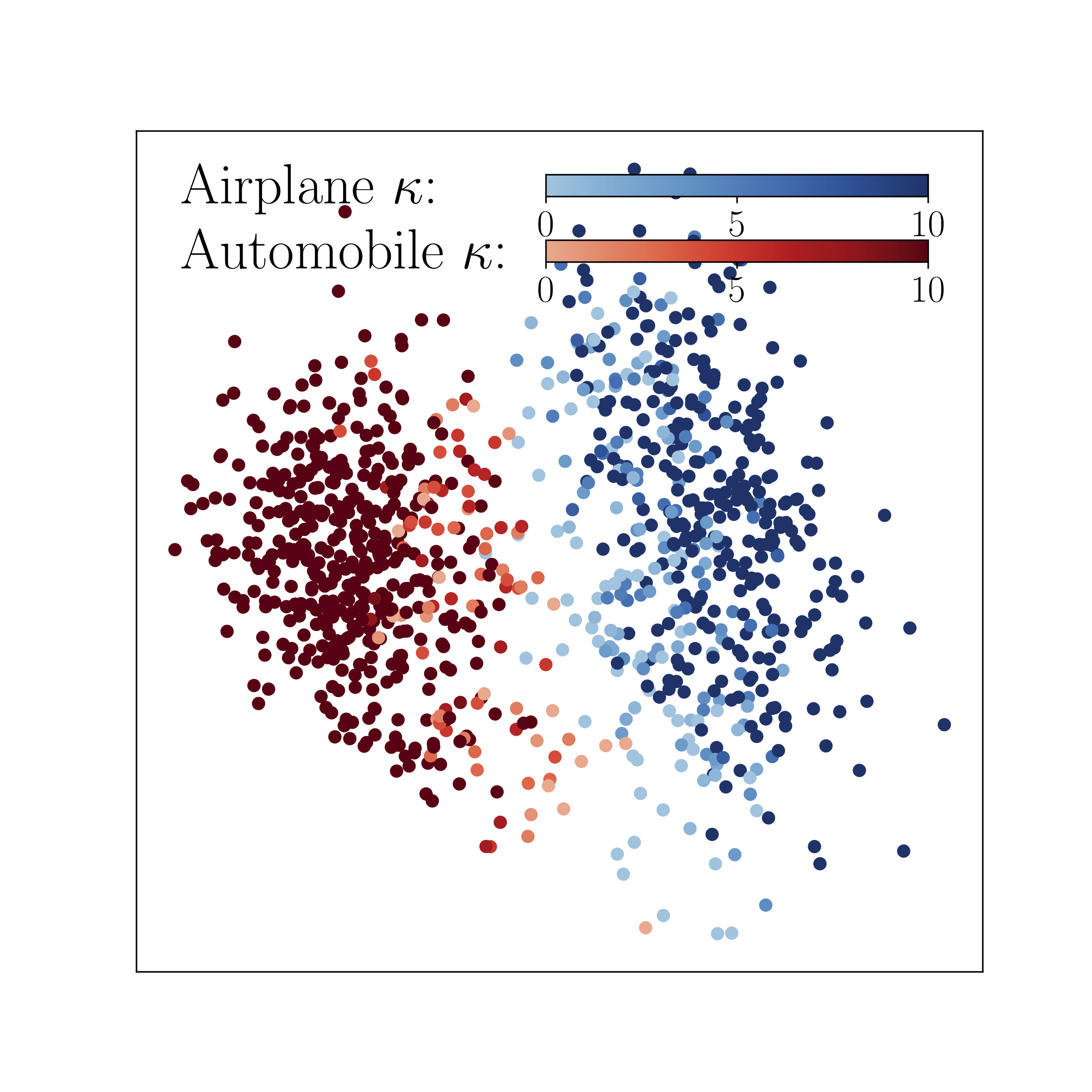
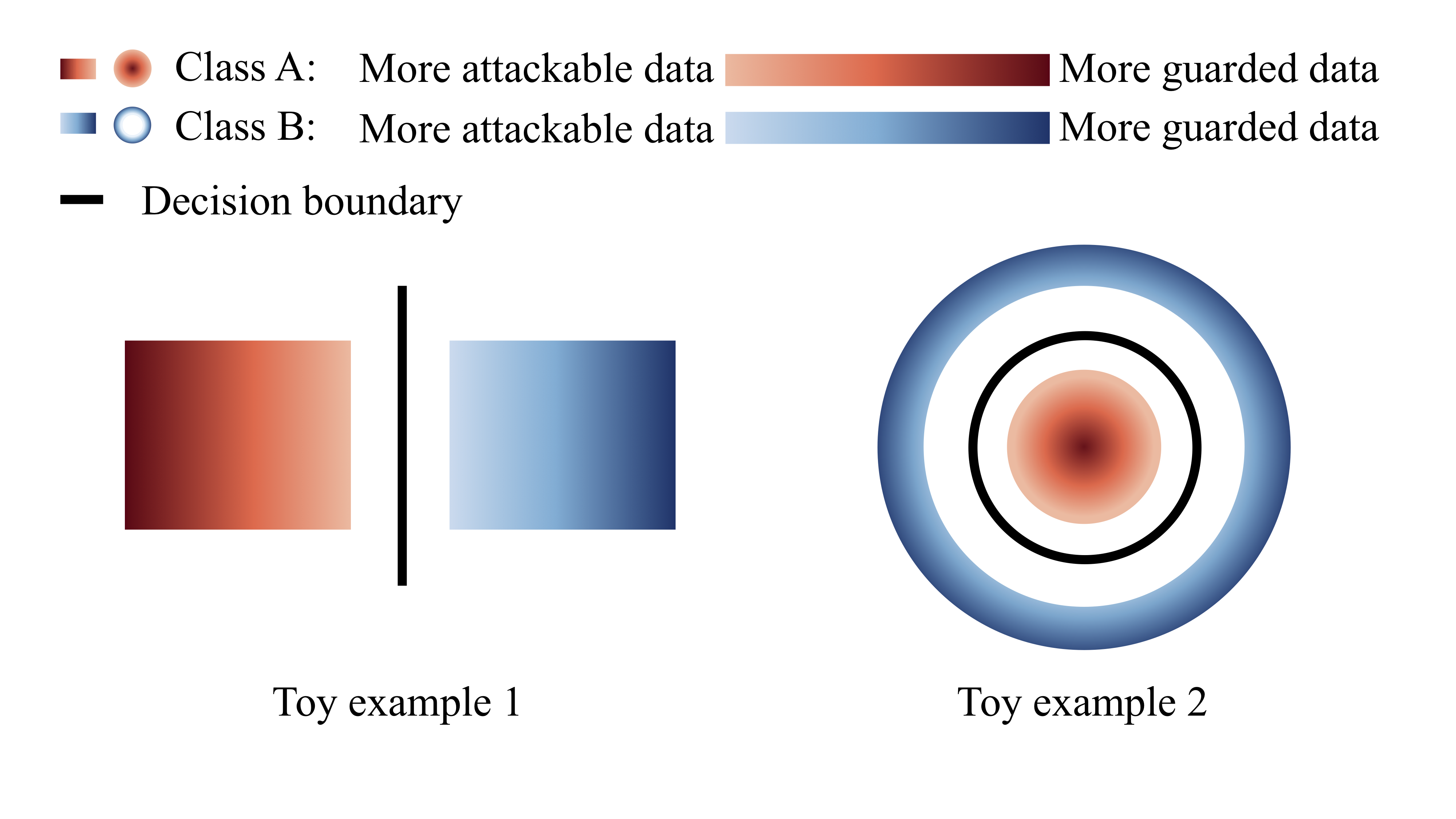
More attackable data (lighter red and blue) are closer to the decision boundary; more guarded data (darker red and blue) are farther away from the decision boundary. *Left panel*: Two toy examples. *Right panel*: The model’s output distribution of two randomly selected classes from the CIFAR-10 dataset. The degree of robustness (denoted by the color gradient) of a data point is calculated based on the least number of iterations κ that PGD needs to find its misclassified adversarial variant.
Therefore, given the limited model capacity, we should treat data differently for updating the model in adversarial training.
IDEA: Geometrically speaking, a natural data point closer to/farther from the class boundary is less/more robust, and the corresponding adversarial data point should be assigned with larger/smaller weight for updating the model.
To implement the idea, we propose geometry-aware instance-reweighted adversarial training (GAIRAT), where the weights are based on how difficult it is to attack a natural data point.
"how difficult it is to attack a natural data point" is approximated by the number of PGD steps that the PGD method requires to generate its misclassified adversarial variant.
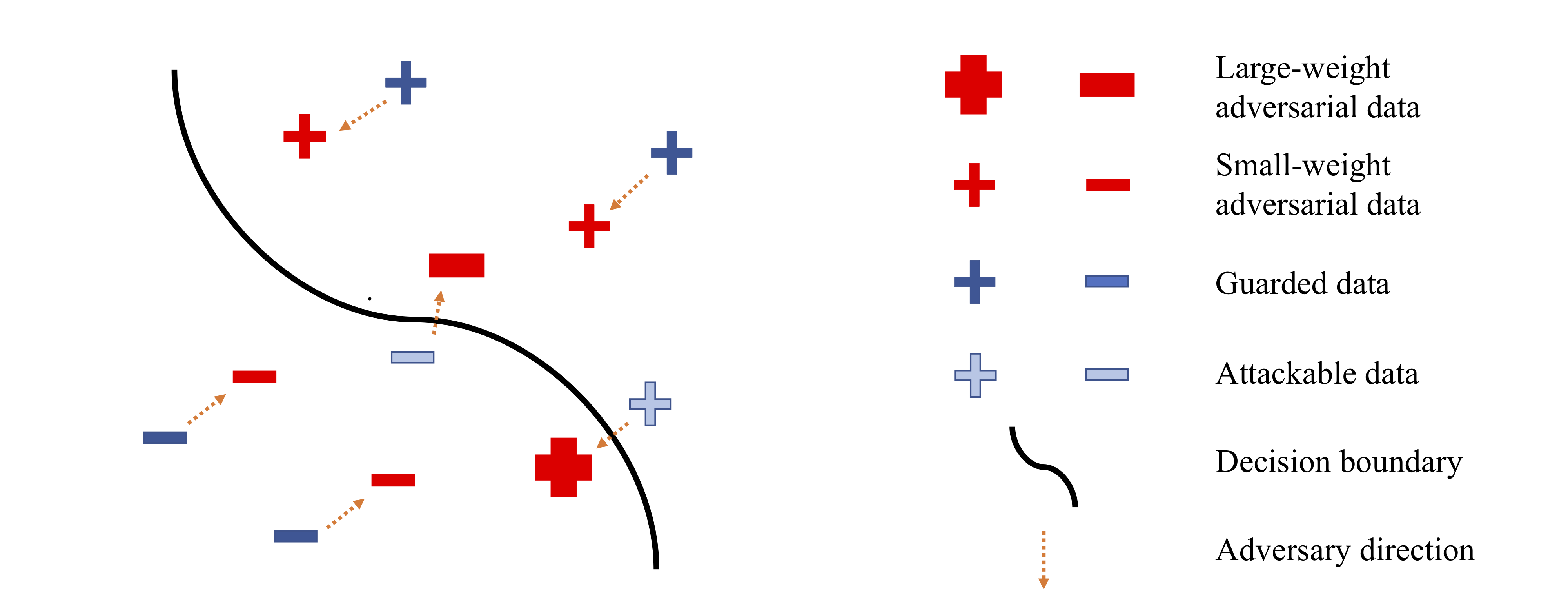
The illustration of GAIRAT. GAIRAT explicitly gives larger weights on the losses of adversarial data (larger red), whose natural counterparts are closer to the decision boundary (lighter blue). GAIRAT explicitly gives smaller weights on the losses of adversarial data (smaller red), whose natural counterparts are farther away from the decision boundary (darker blue).
GAIRAT's Implementation
For updating the model, GAIRAT assigns instance dependent weight (reweight) on the loss of the adversarial data (found in GAIR.py).
The instance dependent weight depends on num_steps, which indicates the least PGD step numbers needed for the misclassified adversarial variant.
Preferred Prerequisites
- Python (3.6)
- Pytorch (1.2.0)
- CUDA
- numpy
- foolbox
Running GAIRAT, GAIR-FAT on benchmark datasets (CIFAR-10 and SVHN)
Here are examples:
CUDA_VISIBLE_DEVICES='0' python GAIRAT.py
CUDA_VISIBLE_DEVICES='0' python GAIR_FAT.py
- How to recover the original FAT and AT using our code?
CUDA_VISIBLE_DEVICES='0' python GAIRAT.py --Lambda 'inf' --output_dir './AT_results'
CUDA_VISIBLE_DEVICES='0' python GAIR_FAT.py --Lambda 'inf' --output_dir './FAT_results'
- Evaluations
After running, you can find./GAIRAT_result/log_results.txtand./GAIR_FAT_result/log_results.txtfor checking Natural Acc. and PGD-20 test Acc.
We also evaluate our models using PGD+. PGD+ is the same asPG_oursin RST repo.PG_oursis PGD with 5 random starts, and each start has 40 steps with step size 0.01 (It has 40 × 5 = 200 iterations for each test data).
Since PGD+ is computational defense, we only evaluate the best checkpointbestpoint.pth.tarand the last checkpointcheckpoint.pth.tarin the foldersGAIRAT_resultandGAIR_FAT_resultrespectively.
CUDA_VISIBLE_DEVICES='0' python eval_PGD_plus.py --model_path './GAIRAT_result/bestpoint.pth.tar' --output_suffix='./GAIRAT_PGD_plus'
CUDA_VISIBLE_DEVICES='0' python eval_PGD_plus.py --model_path './GAIR_FAT_result/bestpoint.pth.tar' --output_suffix='./GAIR_FAT_PGD_plus'
White-box evaluations on WRN-32-10
| Defense (best checkpoint) | Natural Acc. | PGD-20 Acc. | PGD+ Acc. |
|---|---|---|---|
| AT(Madry) | 86.92 % |
51.96% |
51.28% |
| FAT | 89.16% |
51.24% |
46.14% |
| GAIRAT | 85.75% |
57.81% |
55.61% |
| GAIR-FAT | 88.59% |
56.21% |
53.50% |
| Defense (last checkpoint) | Natural Acc. | PGD-20 Acc. | PGD+ Acc. |
|---|---|---|---|
| AT(Madry) | 86.62 % |
46.73% |
46.08% |
| FAT | 88.18% |
46.79% |
45.80% |
| GAIRAT | 85.49% |
53.76% |
50.32% |
| GAIR-FAT | 88.44% |
50.64% |
47.51% |
For more details, refer to Table 1 and Appendix C.8 in the paper.
Benchmarking robustness with additional 500K unlabeled data on CIFAR-10 dataset.
In this repo, we unleash the full power of our geometry-aware instance-reweighted methods by incorporating 500K unlabeled data (i.e., GAIR-RST).
In terms of both evaluation metrics, i.e., generalization and robustness, we can obtain the best WRN-28-10 model among all public available robust models.
- How to create the such the superior model from scratch?
- Download
ti_500K_pseudo_labeled.picklecontaining our 500K pseudo-labeled TinyImages from this link (Auxillary data provided by Carmon et al. 2019). Storeti_500K_pseudo_labeled.pickleinto the folder./data - You may need mutilple GPUs for running this.
chmod +x ./GAIR_RST/run_training.sh
./GAIR_RST/run_training.sh
- We evaluate the robust model using natural test accuracy on natural test data and roubust test accuracy by Auto Attack.
Auto Attack is combination of two white box attacks and two black box attacks.
chmod +x ./GAIR_RST/autoattack/examples/run_eval.sh
White-box evaluations on WRN-28-10
We evaluate the robustness on CIFAR-10 dataset under auto-attack (Croce & Hein, 2020).
Here we list the results using WRN-28-10 on the leadboard and our results. In particular, we use the test eps = 0.031 which keeps the same as the training eps of our GAIR-RST.
CIFAR-10 - Linf
The robust accuracy is evaluated at eps = 8/255, except for those marked with * for which eps = 0.031, where eps is the maximal Linf-norm allowed for the adversarial perturbations. The eps used is the same set in the original papers.
Note: ‡ indicates models which exploit additional data for training (e.g. unlabeled data, pre-training).
| # | method/paper | model | architecture | clean | report. | AA |
|---|---|---|---|---|---|---|
| 1 | (Gowal et al., 2020)‡ | authors | WRN-28-10 | 89.48 | 62.76 | 62.80 |
| 2 | (Wu et al., 2020b)‡ | available | WRN-28-10 | 88.25 | 60.04 | 60.04 |
| - | GAIR-RST (Ours)*‡ | available | WRN-28-10 | 89.36 | 59.64 | 59.64 |
| 3 | (Carmon et al., 2019)‡ | available | WRN-28-10 | 89.69 | 62.5 | 59.53 |
| 4 | (Sehwag et al., 2020)‡ | available | WRN-28-10 | 88.98 | - | 57.14 |
| 5 | (Wang et al., 2020)‡ | available | WRN-28-10 | 87.50 | 65.04 | 56.29 |
| 6 | (Hendrycks et al., 2019)‡ | available | WRN-28-10 | 87.11 | 57.4 | 54.92 |
| 7 | (Moosavi-Dezfooli et al., 2019) | authors | WRN-28-10 | 83.11 | 41.4 | 38.50 |
| 8 | (Zhang & Wang, 2019) | available | WRN-28-10 | 89.98 | 60.6 | 36.64 |
| 9 | (Zhang & Xu, 2020) | available | WRN-28-10 | 90.25 | 68.7 | 36.45 |
The results show our GAIR-RST method can facilitate a competitive model by utilizing additional unlabeled data.
Wanna download our superior model for other purposes? Sure!
We welcome various attack methods to attack our defense models. For cifar-10 dataset, we normalize all images into [0,1].
Download our pretrained models checkpoint-epoch200.pt into the folder ./GAIR_RST/GAIR_RST_results through this Google Drive link.
You can evaluate this pretrained model through ./GAIR_RST/autoattack/examples/run_eval.sh
Reference
@inproceedings{
zhang2021_GAIRAT,
title={Geometry-aware Instance-reweighted Adversarial Training},
author={Jingfeng Zhang and Jianing Zhu and Gang Niu and Bo Han and Masashi Sugiyama and Mohan Kankanhalli},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=iAX0l6Cz8ub}
}
Contact
Please contact [email protected] or [email protected] and [email protected] if you have any question on the codes.
GitHub
https://github.com/zjfheart/Geometry-aware-Instance-reweighted-Adversarial-Training




