meta-interpolation
Myungsub Choi, Janghoon Choi, Sungyong Baik, Tae Hyun Kim, Kyoung Mu Lee
Source code for CVPR 2020 paper "Scene-Adaptive Video Frame Interpolation via Meta-Learning"
Requirements
- Ubuntu 18.04
- Python==3.7
- numpy==1.18.1
- PyTorch1.4.0, cudatoolkit10.1
- opencv==3.4.2
- cupy==7.3 (recommended:
conda install cupy -c conda-forge) - tqdm==4.44.1
For [DAIN], the environment is different; please check dain/dain_env.yml for the requirements.
Usage
Disclaimer : This code is re-organized to run multiple different models in this single codebase. Due to a lot of version and env changes, the numbers obtained from this code may be different (usually better) from those reported in the paper. The original code modifies the main training scripts for each frame interpolation github repo ([DVF (voxelflow)], [SuperSloMo], [SepConv], [DAIN]), and are put in ./legacy/*.py. If you want to exactly reproduce the numbers reported in our paper, please contact @myungsub for legacy experimental settings.
Dataset Preparation
- We use [ Vimeo90K Septuplet dataset ] for training + testing
- After downloading the full dataset, make symbolic links in
data/folder:ln -s /path/to/vimeo_septuplet_data/ ./data/vimeo_septuplet
- After downloading the full dataset, make symbolic links in
- For further evaluation, use:
- [ Middlebury-OTHERS dataset ] - download
other-color-allframes.zipandother-gt-interp.zip - [ HD dataset ] - download the original ground truth videos [here]
- [ Middlebury-OTHERS dataset ] - download
Frame Interpolation Model Preparation
- Download pretrained models from [Here], and save them to
./pretrained_models/*.pth
Training / Testing with Vimeo90K-Septuplet dataset
- For training, simply run:
./scripts/run_{VFI_MODEL_NAME}.sh- Currently supports:
sepconv,voxelflow,superslomo,cain, andrrin - Other models are coming soon!
- Currently supports:
- For testing, just uncomment two lines containing:
--mode valand--pretrained_model {MODEL_NAME}
Testing with custom data
- See
scripts/run_test.shfor details: - Things to change:
- Modify the folder directory containing the video frames by changing
--data_rootto your desired dir/ - Make sure to match the image format
--img_fmt(defaults topng) - Change
--model,--loss, and--pretrained_modelsto what you want- For SepConv,
--modelshould besepconv, and--lossshould be1*L1 - For VoxelFlow,
--modelshould bevoxelflow, and--lossshould be1*MSE - For SuperSloMo,
--modelshould besuperslomo,--lossshould be1*Super - For DAIN,
--modelshould bedain, and--lossshould be1*L1 - For CAIN,
--modelshould becain, and--lossshould be1*L1 - For RRIN, '
--modelshould berrin, and--lossshould be1*L1
- For SepConv,
- Modify the folder directory containing the video frames by changing
Using Other Meta-Learning Algorithms
- Current code supports using more advanced meta-learning algorithms compared to vanilla MAML, e.g. MAML++, L2F, or Meta-SGD.
- For MAML++ you can explore many different hyperparameters by adding additional options (see
config.py) - For L2F, just uncomment
--attenuateinscripts/run_{VFI_MODEL_NAME}.sh - For Meta-SGD, just uncomment
--metasgd(This usually results in the best performance!)
- For MAML++ you can explore many different hyperparameters by adding additional options (see
Framework Overview
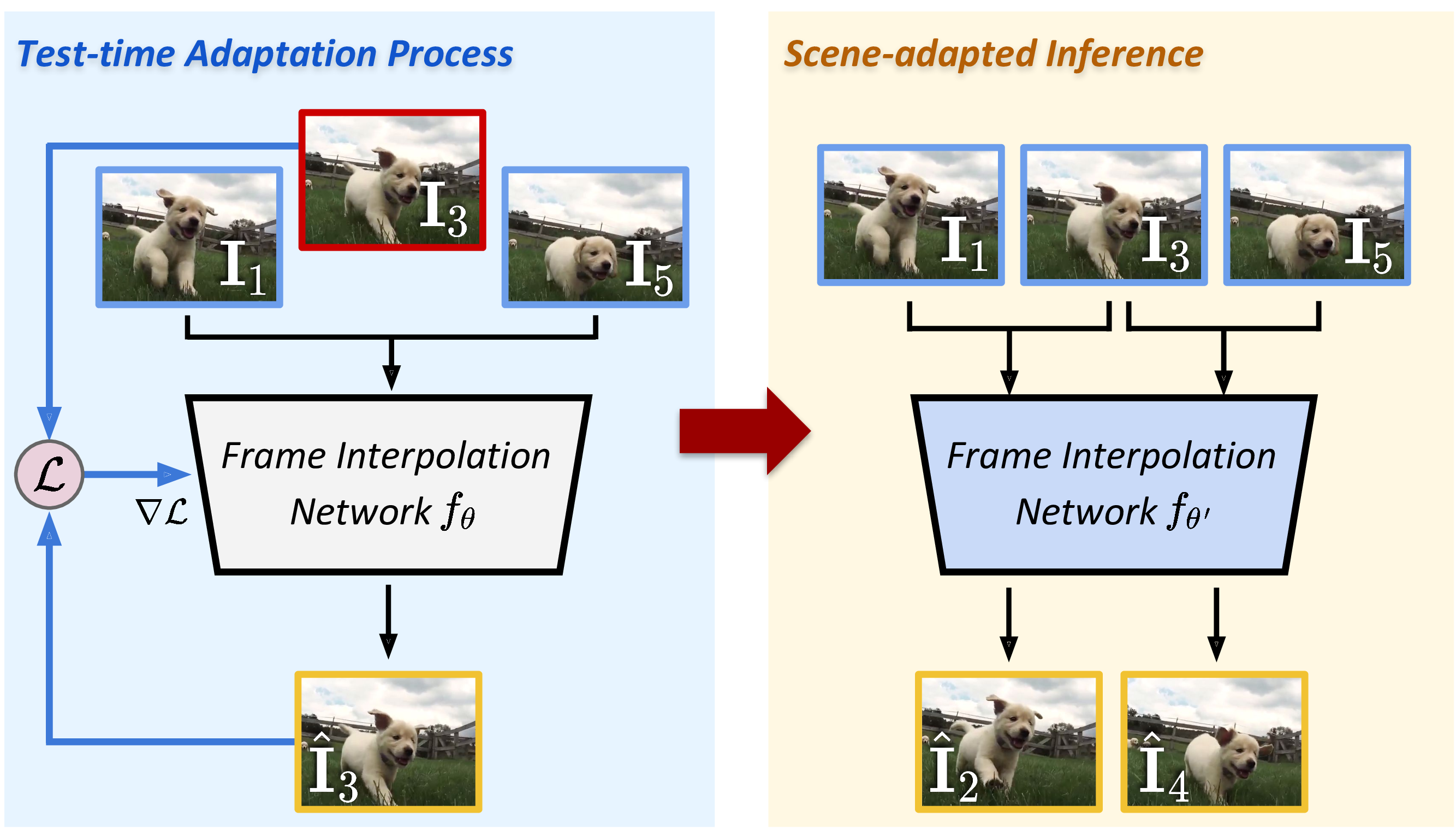
Results
- Qualitative results for VimeoSeptuplet dataset

- Qualitative results for Middlebury-OTHERS dataset

- Qualitative results for HD dataset

Additional Results Video
Citation
If you find this code useful for your research, please consider citing the following paper:
@inproceedings{choi2020meta,
author = {Choi, Myungsub and Choi, Janghoon and Baik, Sungyong and Kim, Tae Hyun and Lee, Kyoung Mu},
title = {Scene-Adaptive Video Frame Interpolation via Meta-Learning},
booktitle = {CVPR},
year = {2020}
}


