One-shot Affordance Detection
PyTorch implementation of our one-shot affordance detection models. This repository contains PyTorch evaluation code, training code and pretrained models.
Abstract
Affordance detection refers to identifying the potential action possibilities of objects in an image, which is a crucial ability for robot perception and manipulation. To empower robots with this ability in unseen scenarios, we first consider the challenging one-shot affordance detection problem in this paper, i.e., given a support image that depicts the action purpose, all objects in a scene with the common affordance should be detected. To this end, we devise a One-Shot Affordance Detection Network (OSAD-Net) that firstly estimates the human action purpose and then transfers it to help detect the common affordance from all candidate images. Through collaboration learning, OSAD-Net can capture the common characteristics between objects having the same underlying affordance and learn a good adaptation capability for perceiving unseen affordances. Besides, we build a Purpose-driven Affordance Dataset v2 (PADv2) by collecting and labeling 30k images from 39 affordance and 94 object categories. With complex scenes and rich annotations, our PADv2 can comprehensively understand the affordance of objects and can even be used in other vision tasks, such as scene understanding, action recognition, robot manipulation, etc. We present a standard one-shot affordance detection benchmark comparing 11 advanced models in several different fields. Experimental results demonstrate the superiority of our model over previous representative ones in terms of both objective metrics and visual quality.
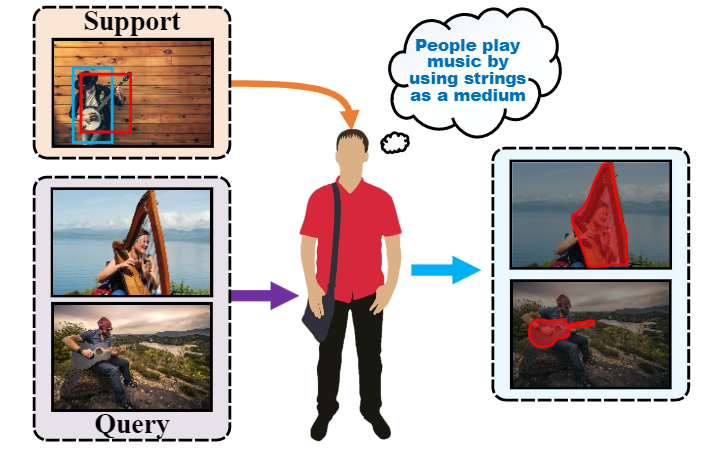
Illustration of perceiving affordance. Given a support image that depicts the action purpose, all objects in ascene with the common affordance could be detected.
? Method
OSAD-Net (IJCAI2021)
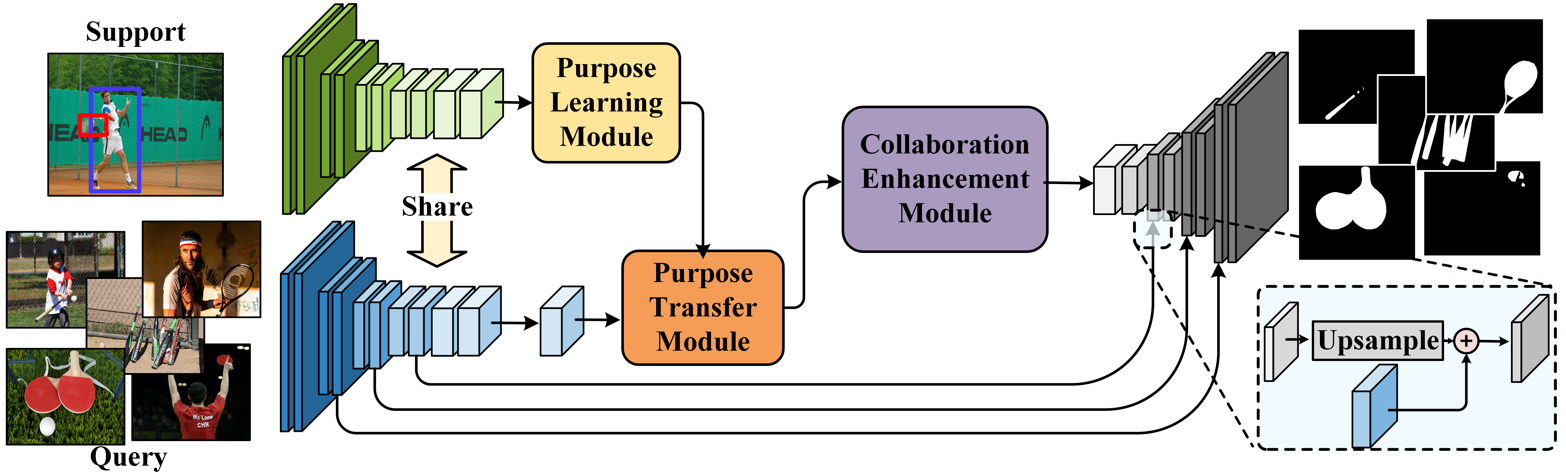
Our One-Shot Affordance Detection (OS-AD) network. OSAD-Net_ijcai consists of three key modules: Purpose Learning Module (PLM), Purpose Transfer Module (PTM), and Collaboration Enhancement Module (CEM). (a) PLM aims to estimate action purpose from the human-object interaction in the support image. (b) PTM transfers the action purpose to the query images via an attention mechanism to enhance the relevant features. (c) CEM captures the intrinsic characteristics between objects having the common affordance to learn a better affordance perceiving ability.
OSAD-Net (Extended Version)

The framework of our OSAD-Net. For our OSAD-Net pipeline, the network first uses a Resnet50 to extract the features of support image and query images. Subsequently, the support feature, the bounding box of the person and object, and the pose of the person are fed together into the action purpose learning (APL) module to obtain the human action purpose features. And then send the human action purpose features and query images together to the mixture purpose transfer (MPT) to transfer the human action purpose to query images and activate the object region belonging to the affordance in the query images. Then, the output of the MPT is fed into a densely collaborative enhancement (DCE) module to learn the commonality among objects of the same affordance and suppress the irrelevant background regions using the cooperative strategy, and finally feed into the decoder to obtain the final detection results.
? Dataset

The samples images in the PADv2 of this paper. Our PADv2 has rich annotations such as affordance masks as well as depth information. Thus it provides a solid foundation for the affordance detection task.
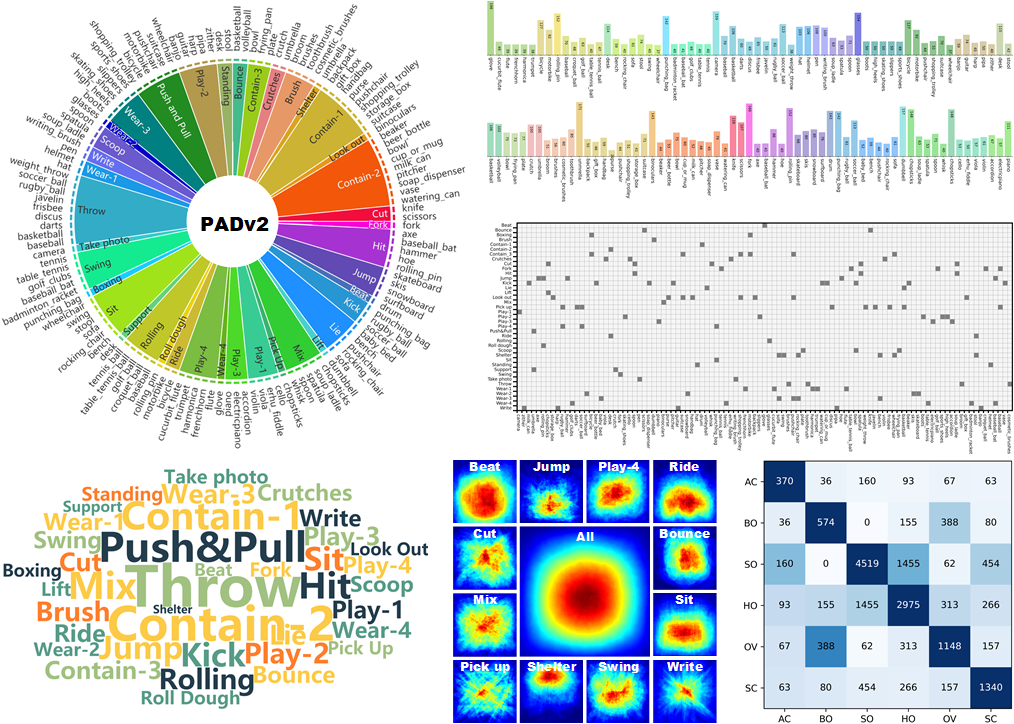
The properties of PADv2. (a) The classification structure of the PADv2 in this paper consists of 39 affordance categories and 94 object categories. (b) The word cloud distribution of the PADv2. (c) Overlapping masks visualization of PADv2 mixed with specific affordance classes and overall category masks. (d) Confusion matrix of PADv2 affordance category and object category, where the horizontal axis corresponds to the object category and the vertical axis corresponds to the affordance category, (e) Distribution of co-occurring attributes of the PADv2, the grid is numbered for the total number of images.
Download PAD
- You can download the PAD from [ Google Drive | Baidu Pan (z40m) ].
cd Downloads/
unzip PAD.zip
cd OSAD-Net
mkdir datasets/PAD
mv Downloads/PAD/divide_1 datasets/PAD/
mv Downloads/PAD/divide_2 datasets/PAD/
mv Downloads/PAD/divide_3 datasets/PAD/
Download PADv2
- You can download the PADv2 from [ Baidu Pan (1ttj) ].
cd Downloads/
unzip PADv2_part1.zip
cd OSAD-Net
mkdir datasets/PADv2_part1
mv Downloads/PADv2_part1/divide_1 datasets/PADv2_part1/
mv Downloads/PADv2_part1/divide_2 datasets/PADv2_part1/
mv Downloads/PADv2_part1/divide_3 datasets/PADv2_part1/
? Requirements
- python 3.7
- pytorch 1.1.0
- opencv
✏️ Usage
git clone https://github.com/lhc1224/OSAD_Net.git
cd OSAD-Net
Train
You can download the pretrained model from [ Google Drive | Baidu Pan (xjk5) ], then move it to the models folder
To train the OSAD-Net_ijcai model, run run_os_ad.py with the desired model architecture:
python run_os_ad.py
To train the OSAD-Net model, run run_os_adv2.py with the desired model architecture:
python run_os_adv2.py
Test
To test the OSAD-Net_ijcai model, run run_os_ad.py:
python run_os_ad.py --mode test
To test the OSAD-Net model, run run_os_ad.py, you can download the trained models from [ Google Drive | Baidu Pan (611r) ]
python run_os_adv2.py --mode test
Evaluation
In order to evaluate the forecast results, the evaluation code can be obtained via the following Evaluation Tools.
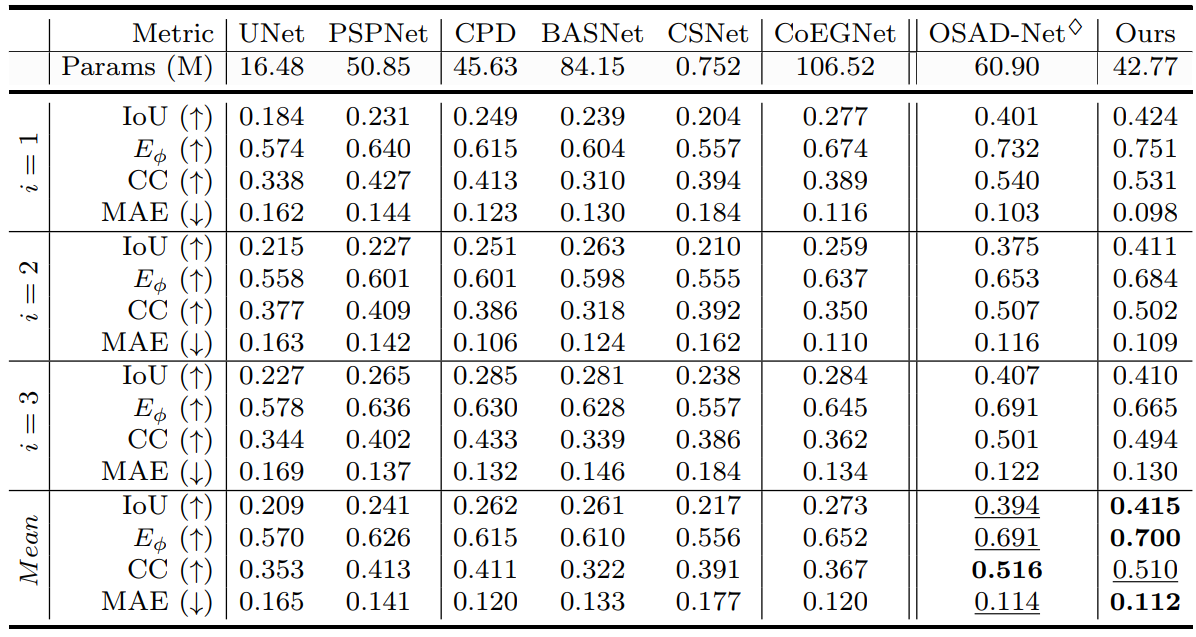
? Experimental Results
Performance on PADv2
You can download the affordance maps from [ Google Drive | Baidu Pan (hwtf) ]
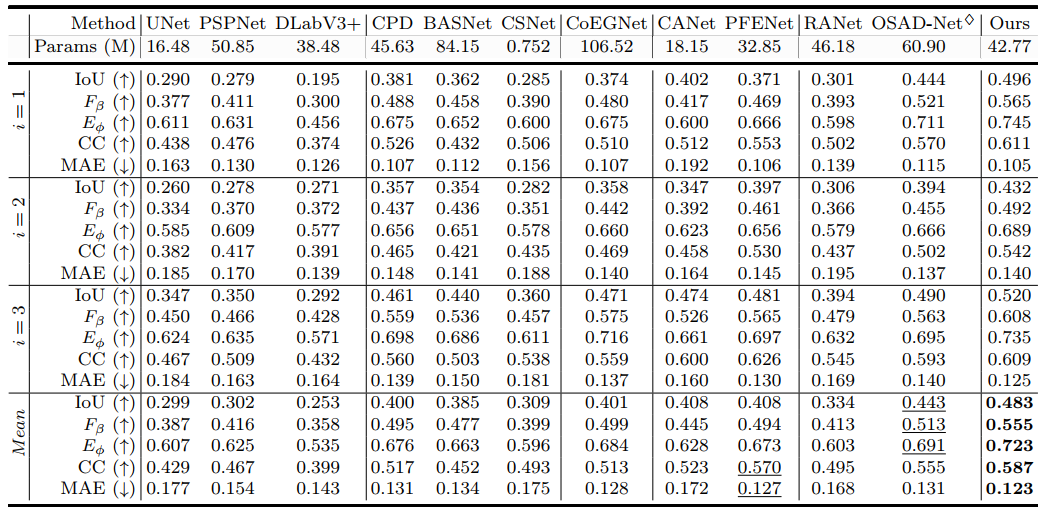
Performance on PAD
You can download the affordance maps from [ Google Drive | Baidu Pan(hrlj) ]
? Potential Applications
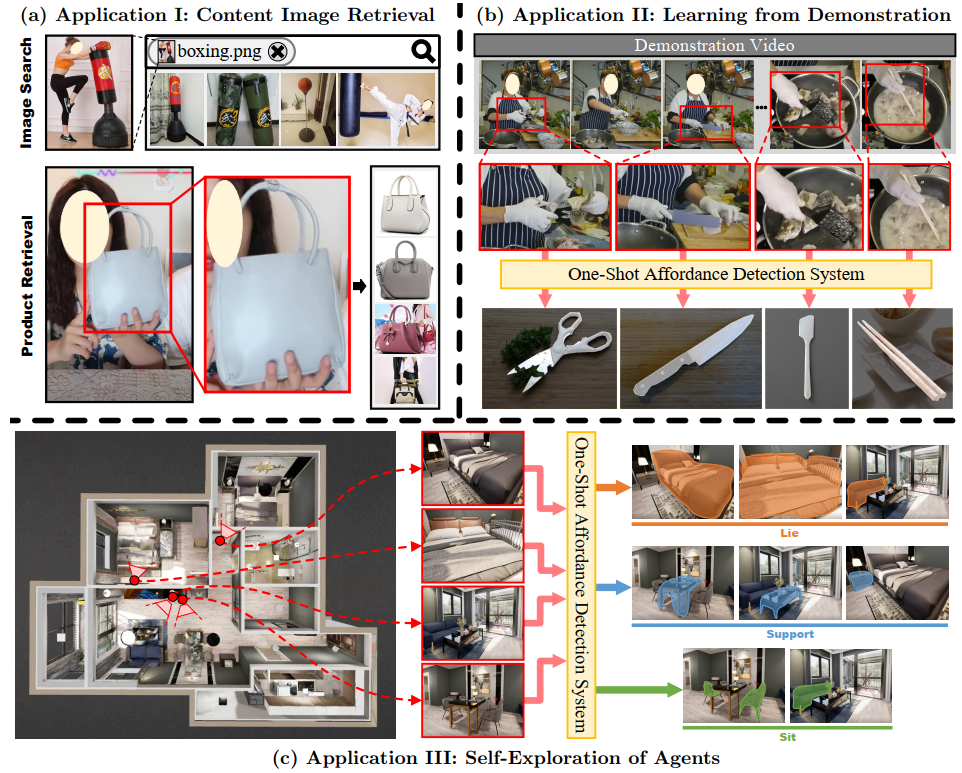
Potential Applications of one-shot affordance system. (a) Application I: Content Image Retrieval. The content image retrieval model combined with affordance detection has a promising application in search engines and online shopping platforms. (b) Application II: Learning from Demonstration. The one-shot affordance detection model can help an agent
to naturally select the correct object based on the expert’s actions. (c) Application III: Self-exploration of Agents. The one-shot affordance detection model helps an agent to autonomously perceive all instances or areas of a scene with the similar affordance property in unknown human spaces based on historical data (e.g., images of human interactions)
✉️ Statement
This project is for research purpose only, please contact us for the licence of commercial use. For any other questions please contact [email protected] or [email protected].
? Citation
@inproceedings{Oneluo,
title={One-Shot Affordance Detection},
author={Hongchen Luo and Wei Zhai and Jing Zhang and Yang Cao and Dacheng Tao},
booktitle={IJCAI},
year={2021}
}
@article{luo2021one,
title={One-Shot Affordance Detection in the Wild},
author={Zhai, Wei and Luo, Hongchen and Zhang, Jing and Cao, Yang and Tao, Dacheng},
journal={arXiv preprint arXiv:2106.14747xx},
year={2021}
}









