TANet
Code will be released before the conference of AAAI-2020. Note: our code is mainly based on PointPillars and SECOND, thanks for them! We also plan to introduce TensorRT to further improve the inference speed. For more information please refer the Paper.
Introduce
In this paper, we focus on exploring the robustness of the 3D object detection in point clouds, which has been rarely discussed in existing approaches. We observe two crucial phenomena: 1) the detection accuracy of the hard objects,e.g., Pedestrians, is unsatisfactory, 2) when adding additionalnoise points, the performance of existing approaches de-creases rapidly. To alleviate these problems, a novel TANet isintroduced in this paper, which mainly contains a Triple At-tention (TA) module, and a Coarse-to-Fine Regression (CFR)module. By considering the channel-wise, point-wise andvoxel-wise attention jointly, the TA module enhances the cru-cial information of the target while suppresses the unsta-ble cloud points. Besides, the novel stacked TA further ex-ploits the multi-level feature attention. In addition, the CFR module boosts the accuracy of localization without excessive computation cost. Experimental results on the validation setof KITTI dataset demonstrate that, in the challenging noisy cases, i.e., adding additional random noisy points around eachobject, the presented approach goes far beyond state-of-the-art approaches, especially for the Pedestrian class.The running speed is around 29 frames per second.
The network architecture of TANet:
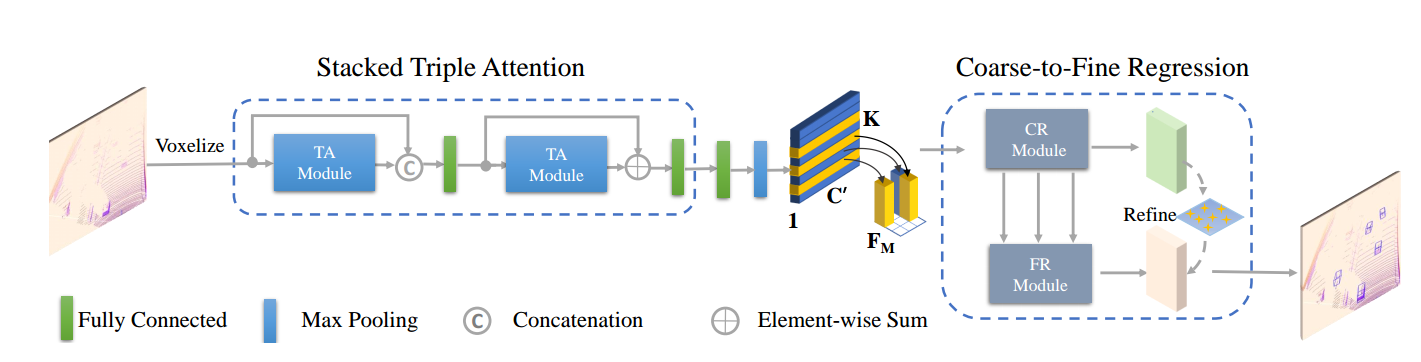
First, we equally divide the point clouds into a voxel grid consisting of a set of voxels. Then, the stacked triple attention separately process each voxel to obtain a more discriminative representation. Subsequently, a compact feature representation for each voxel is extracted by aggregating the points inside it in a max-pooling manner. And we arrange the voxel feature according to its original spatial position in the grid, and thus lead to a feature representation for the voxel grid in the shape of C' × H × W . Finally, the coarse-to-fine regression is employed to generate the final 3D bounding boxes.
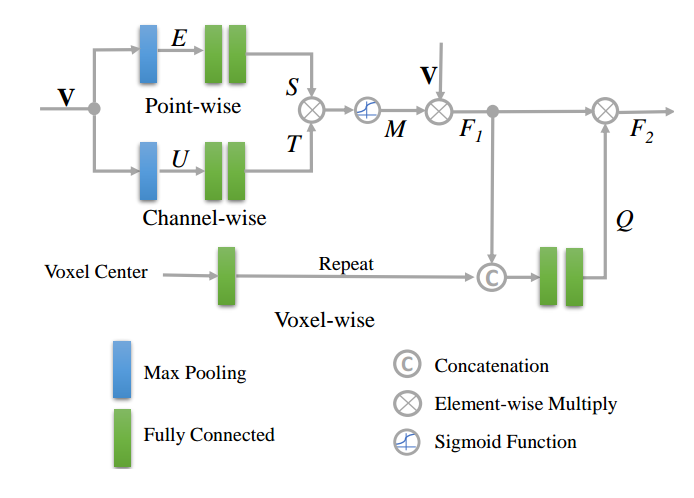
Triple Attention Module:
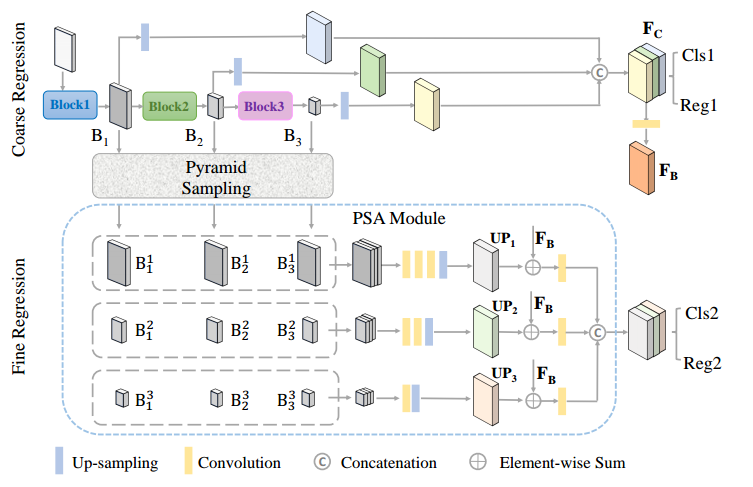
Coarse-To-Fine Regression Module:
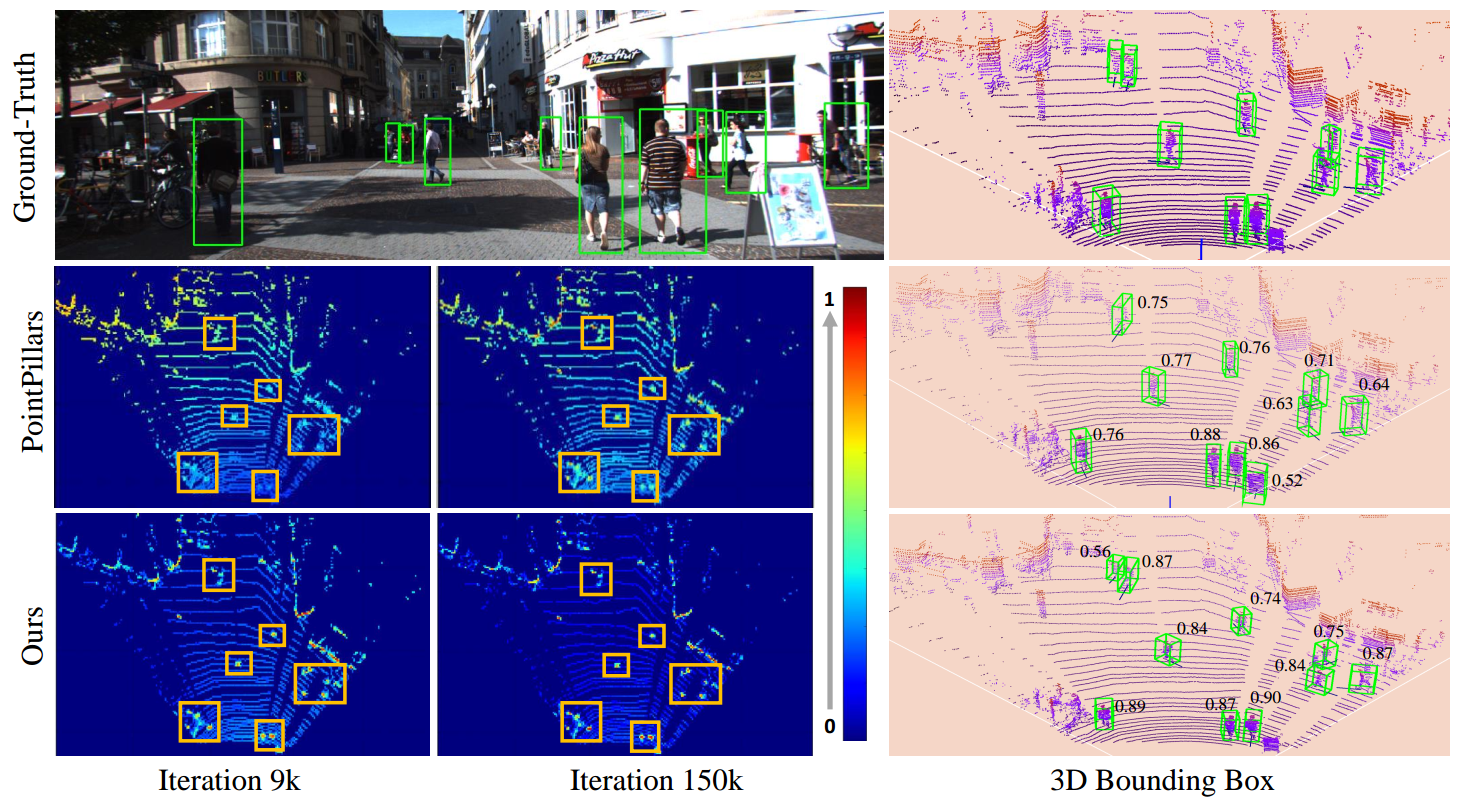
Reuslts
The visualization of learned feature map and predicted confidence score for PointPillars and Ours:
Citation
If you find our work useful in your research, please consider citing:
@article{liu2019tanet,
title={TANet: Robust 3D Object Detection from Point Clouds with Triple Attention},
author={Zhe Liu and Xin Zhao and Tengteng Huang and Ruolan Hu and Yu Zhou and Xiang Bai},
year={2020},
journal={AAAI},
url={https://arxiv.org/pdf/1912.05163.pdf},
eprint={1912.05163},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{lang2018pointpillars,
title={PointPillars: Fast Encoders for Object Detection from
Point Clouds},
author={Lang, Alex H and Vora, Sourabh and Caesar,
Holger and Zhou, Lubing and Yang, Jiong and Beijbom,
Oscar},
journal={CVPR},
year={2019}
}
@article{yan2018second,
title={Second: Sparsely embedded convolutional detection},
author={Yan, Yan and Mao, Yuxing and Li, Bo},
journal={Sensors},
volume={18},
number={10},
pages={3337},
year={2018},
publisher={Multidisciplinary Digital Publishing Institute}
}



