SIMPLE
Selfplay In MultiPlayer Environments.
About The Project
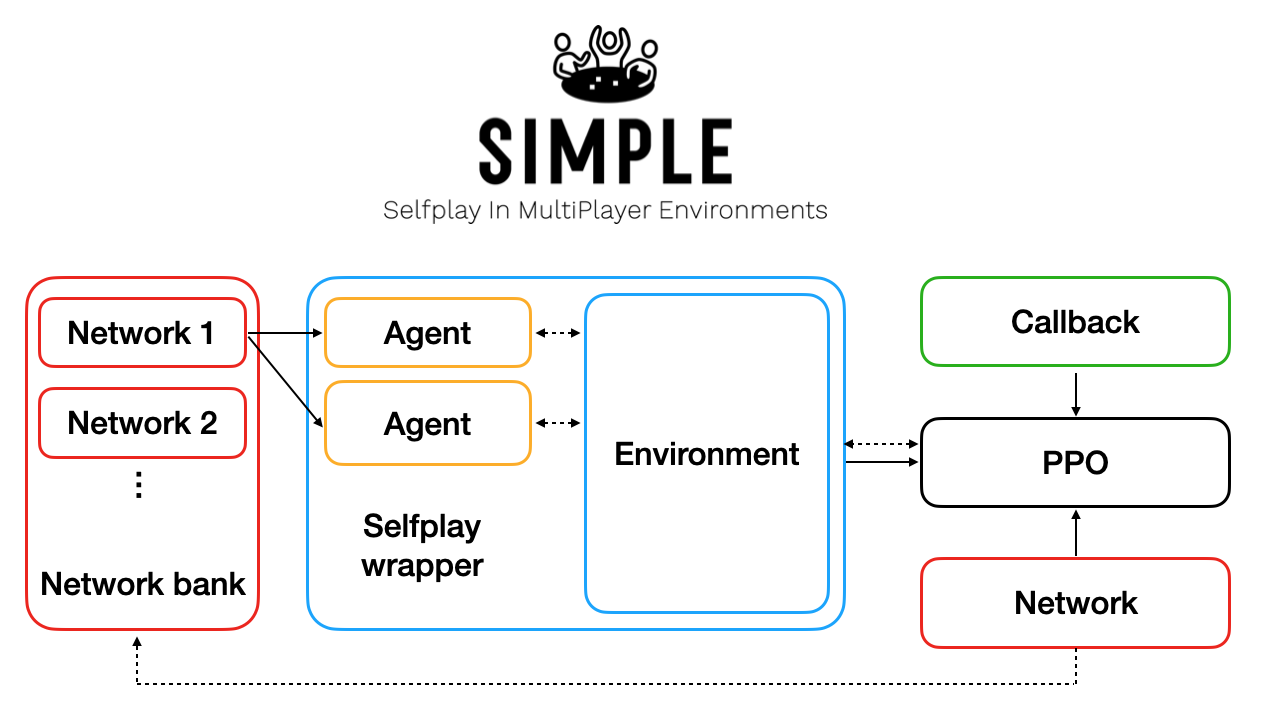
This project allows you to train AI agents on custom-built multiplayer environments, through self-play reinforcement learning.
It implements Proximal Policy Optimisation (PPO), with a built-in wrapper around the multiplayer environments that handles the loading and action-taking of opponents in the environment. The wrapper delays the reward back to the PPO agent, until all opponents have taken their turn. In essence, it converts the multiplayer environment into a single-player environment that is constantly evolving as new versions of the policy network are added to the network bank.
To learn more, check out the accompanying blog post.
This guide explains how to get started with the repo, add new custom environments and tune the hyperparameters of the system.
Have fun!
Getting Started
To get a local copy up and running, follow these simple steps.
Prerequisites
Install Docker and Docker Compose to make use of the docker-compose.yml file
Installation
- Clone the repo
git clone https://github.com/davidADSP/SIMPLE.git cd SIMPLE - Build the image and 'up' the container.
docker-compose up -d - Choose an environment to install in the container (
tictactoe,connect4and 3-playersushigoare currently implemented)bash ./scripts/install_env.sh sushigo
Tutorial
This is a quick tutorial to allow you to start using the two entrypoints into the codebase: test.py and train.py.
TODO - I'll be adding more substantial documentation for both of these entrypoints in due course! For now, descriptions of each command line argument can be found at the bottom of the files themselves.
Quickstart
test.py
This entrypoint allows you to play against a trained AI, pit two AIs against eachother or play against a baseline random model.
For example, try the following command to play against a baseline random model in the Sushi Go environment.
docker-compose exec app python3 test.py -d -g 1 -a base base human -e sushigo
train.py
This entrypoint allows you to start training the AI using selfplay PPO. The underlying PPO engine is from the Stable Baselines package.
For example, you can start training the agent to learn how to play SushiGo with the following command:
docker-compose exec app python3 train.py -r -e sushigo
After 30 or 40 iterations the process should have achieved above the default threshold score of 0.2 and will output a new best_model.zip to the /zoo/sushigo folder.
Training runs until you kill the process manually (e.g. with Ctrl-C), so do that now.
You can now use the test.py entrypoint to play 100 games silently between the current best_model.zip and the random baselines model as follows:
docker-compose exec app python3 test.py -g 100 -a best_model base base -e sushigo
You should see that the best_model scores better than the two baseline model opponents.
Played 100 games: {'best_model_btkce': 31.0, 'base_sajsi': -15.5, 'base_poqaj': -15.5}
You can continue training the agent by dropping the -r reset flag from the train.py entrypoint arguments - it will just pick up from where it left off.
docker-compose exec app python3 train.py -e sushigo
Congratulations, you've just completed one training cycle for the game Sushi Go! The PPO agent will now have to work out a way to beat the model it has just created...
Tensorboard
To monitor training, you can start Tensorboard with the following command:
bash scripts/tensorboard.sh
Navigate to localhost:6006 in a browser to view the output.
In the /zoo/pretrained/ folder there is a pre-trained /<game>/best_model.zip for each game, that can be copied up a directory (e.g. to /zoo/sushigo/best_model.zip) if you want to test playing against a pre-trained agent right away.
Custom Environments
You can add a new environment by copying and editing an existing environment in the /environments/ folder.
For the environment to work with the SIMPLE self-play wrapper, the class must contain the following methods (expanding on the standard methods from the OpenAI Gym framework):
__init__
In the initiation method, you need to define the usual action_space and observation_space, as well as two additional variables:
n_players- the number of players in the gamecurrent_player_num- an integer that tracks which player is currently active
step
The step method accepts an action from the current active player and performs the necessary steps to update the game environment. It should also it should update the current_player_num to the next player, and check to see if an end state of the game has been reached.
reset
The reset method is called to reset the game to the starting state, ready to accept the first action.
render
The render function is called to output a visual or human readable summary of the current game state to the log file.
observation
The observation function returns a numpy array that can be fed as input to the PPO policy network. It should return a numeric representation of the current game state, from the perspective of the current player, where each element of the array is in the range [-1,1].
legal_actions
The legal_actions function returns a numpy vector of the same length as the action space, where 1 indicates that the action is valid and 0 indicates that the action is invalid.
Please refer to existing environments for examples of how to implement each method.
Parallelisation
The training process can be parallelised using MPI across multiple cores.
For example to run 10 parallel threads that contribute games to the current iteration, you can simply run:
docker-compose exec app mpirun -np 10 python3 train.py -e sushigo
Roadmap
See the open issues for a list of proposed features (and known issues).
Contributing
Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request



