Densely Connected Bidirectional LSTM
Tensorflow implementation of Densely Connected Bidirectional LSTM with Applications to Sentence Classification.
Densely Connected Bidirectional LSTM (DC-Bi-LSTM) Overview
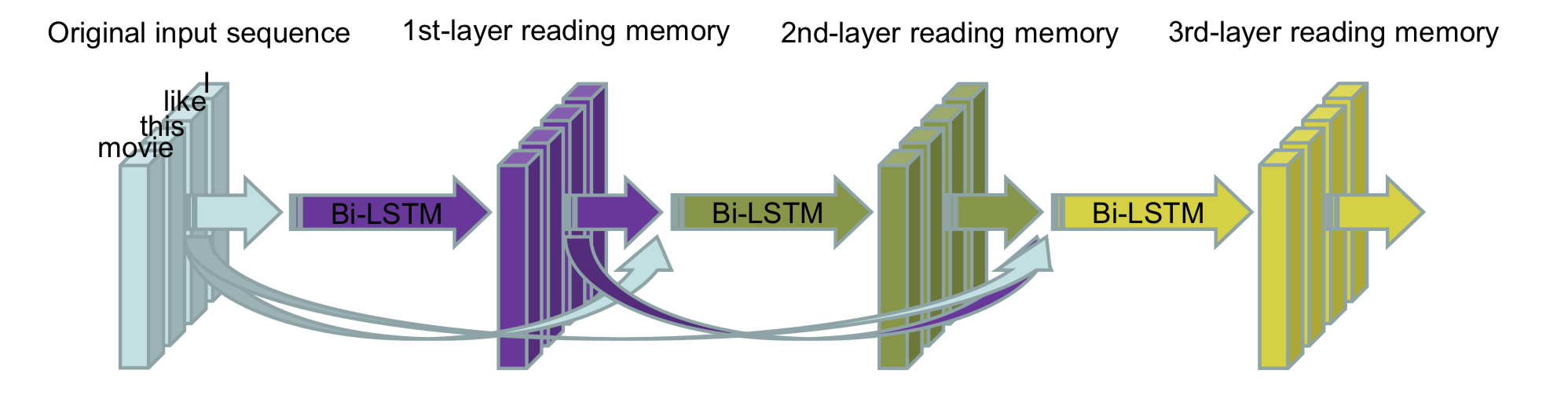
The architecture of DC-Bi-LSTM. The first-layer reading memory is obtained based on original input sequence, and second-layer reading memory based on the position-aligned concatenation of original input sequence and first-layer reading memory, and so on. Finally, get the n-th-layer reading memory and take it as the final feature representation for classification.
Illustration of (a) Deep Stacked Bi-LSTM and (b) DC-Bi-LSTM. Each black node denotes an input layer. Purple, green, and yellow nodes denote hidden layers. Orange nodes denote average pooling of forward or backward hidden layers. Each red node denotes a class. Ellipse represents the concatenation of its internal nodes. Solid lines denote the connections of two layers. Finally, dotted lines indicate the operation of copying.
Usage
Configuration: all parameters and configurations are stored in models/config.py.
The first step is to prepare the required data (pre-trained word embeddings and raw datasets). The raw datasets are already included in this repository, which are located at dataset/raw/, word embeddings used in the paper, the 300-dimensional Glove vectors that were trained on 42 billion words, can be obtained by
$ cd dataset
$ ./download_emb.sh
After downloading the pre-trained word embeddings, run following to build training, development and testing dataset among all raw datasets, the built datasets will be stored in dataset/data/ directory.
$ cd dataset
$ python3 prepro.py
Then training model on a specific dataset via
$ python3 train_model.py --task <str> --resume_training <bool> --has_devset <bool>
# eg:
$ python3 train_model.py --task subj --resume_training True --has_devset False



