Hermione
Hermione is the newest open source library that will help Data Scientists on setting up more organized codes, in a quicker and simpler way. Besides, there are some classes in Hermione which assist with daily tasks such as: column normalization and denormalization, data view, text vectoring, etc. Using Hermione, all you need is to execute a method and the rest is up to her, just like magic.
Why Hermione?
To bring in a little of A3Data experience, we work in Data Science teams inside several client companies and it’s undeniable the excellence of notebooks as a data exploration tool. Nevertheless, when it comes to data science products and their context, when the models needs to be consumed, monitored and have periodic maintenance, putting it into production inside a Jupyter Notebook is not the best choice (we are not even mentioning memory and CPU performance yet). And that’s why Hermione comes in!
We have been inspired by this brilliant, empowered and awesome witch of The Harry Potter saga to name this framework!
This is also our way of reinforcing our position that women should be taking more leading roles in the technology field. #CodeLikeAGirl
Installing
Dependencies
- Anaconda or Miniconda Python (>= 3.6)
- conda (>= 4.8)
Hermione depends on conda to build and manage virtual conda environments. If you don't have it installed, please visit
Anaconda website or
Miniconda website.
Install
pip install -U hermione-ml
How do I use Hermione?
After installed Hermione:
- Create you new project:

- Enter “y” if you want to start with an example code

- Hermione already creates a conda virtual environment for the project. Activate it
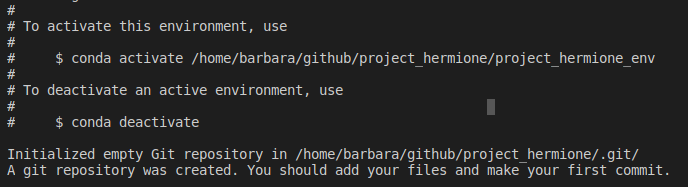
- After activating, you should install some libraries. There are a few suggestions in “requirements.txt” file:

- Now we will train some models from the example, using MLflow ❤. To do so, inside src directory, just type: hermione train. The “hermione train” command will search for a
train.pyfile and execute it. In the example, models and metrics are already controlled via MLflow.
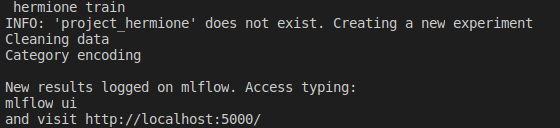
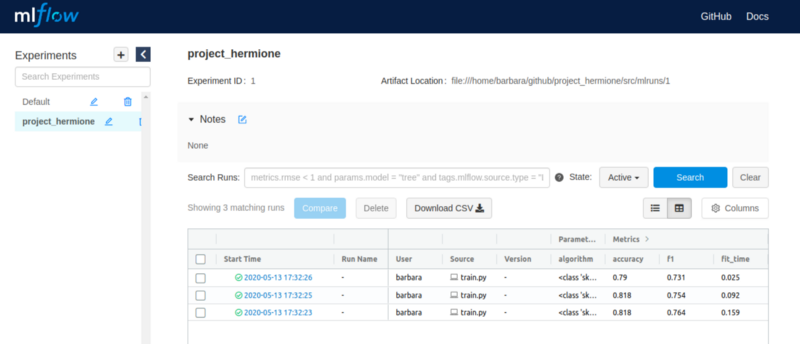
- After that, a mlflow experiment is created. To verify the experiment in mlflow, type: mlflow ui. The application will go up.

- To access the experiment, just enter the path previously provided in your preferred browser. Then it is possible to check the trained models and their metrics.
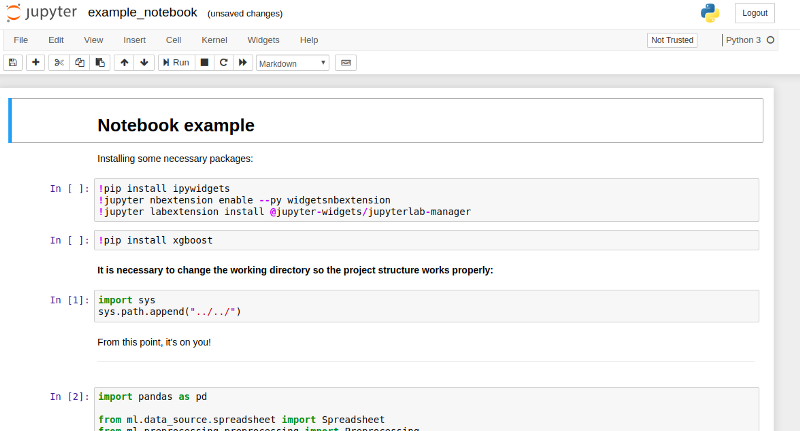
- In the Titanic example, we also provide a step by step notebook. To view it, just type jupyter notebook inside directory
/src/notebooks/.
Do you want to create your project from scratch? There click here to check a tutorial.
Documentation
This is the class structure diagram that Hermione relies on:
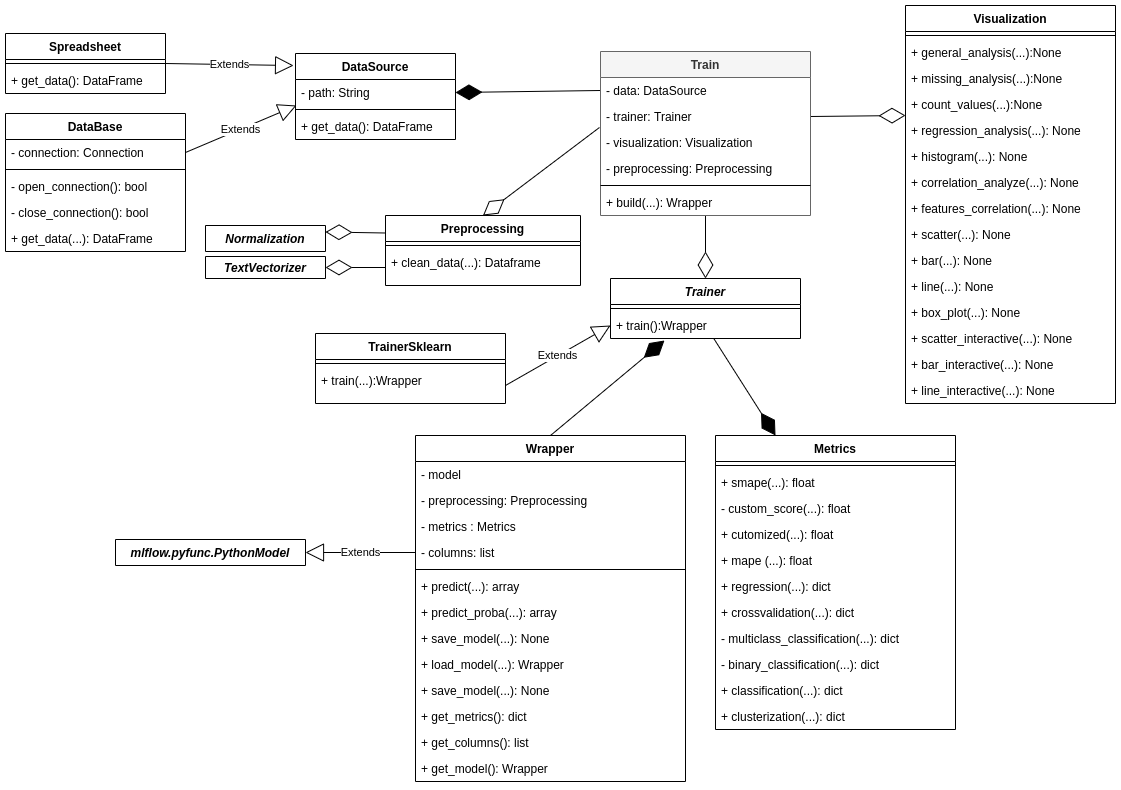
Here we describe briefly what each class is doing:
Data Source
- DataBase - should be used when data recovery requires a connection to a database. Contains methods for opening and closing a connection.
- Spreadsheet - should be used when data recovery is in spreadsheets/text files. All aggregation of the bases to generate a "flat table" should be performed in this class.
- DataSource - abstract class which DataBase and Spreadsheet inherit from.
Preprocessing
- Preprocessing - concentrates all preprocessing steps that must be performed on the data before the model is trained.
- Normalization - applies normalization and denormalization to reported columns. This class contains the following normalization algorithms already implemented: StandardScaler e MinMaxScaler.
- TextVectorizer - transforms text into vector. Implemented methods: Bag of words, TF_IDF, Embedding: mean, median e indexing.
Visualization
- Visualization - methods for data visualization. There are methods to make static and interactive plots.
Model
- Trainer - module that centralizes training algorithms classes. Algorithms from
scikit-learnlibrary, for instance, can be easily used with the TrainerSklearn implemented class. - Wrapper - centralizes the trained model with its metrics. This class has built-in integration with MLFlow.
- Metrics - it contains key metrics that are calculated when models are trained. Classification, regression and clustering metrics are already implemented.
Tests
- test_project - module for unit testing.



