Minkowski Engine
The Minkowski Engine is an auto-differentiation library for sparse tensors. It supports all standard neural network layers such as convolution, pooling, unpooling, and broadcasting operations for sparse tensors.
Example Networks
The Minkowski Engine supports various functions that can be built on a sparse tensor. We list a few popular network architectures and applications here. To run the examples, please install the package and run the command in the package root directory.
| Examples | Networks and Commands |
|---|---|
| Semantic Segmentation |   python -m examples.indoor |
| Classification | 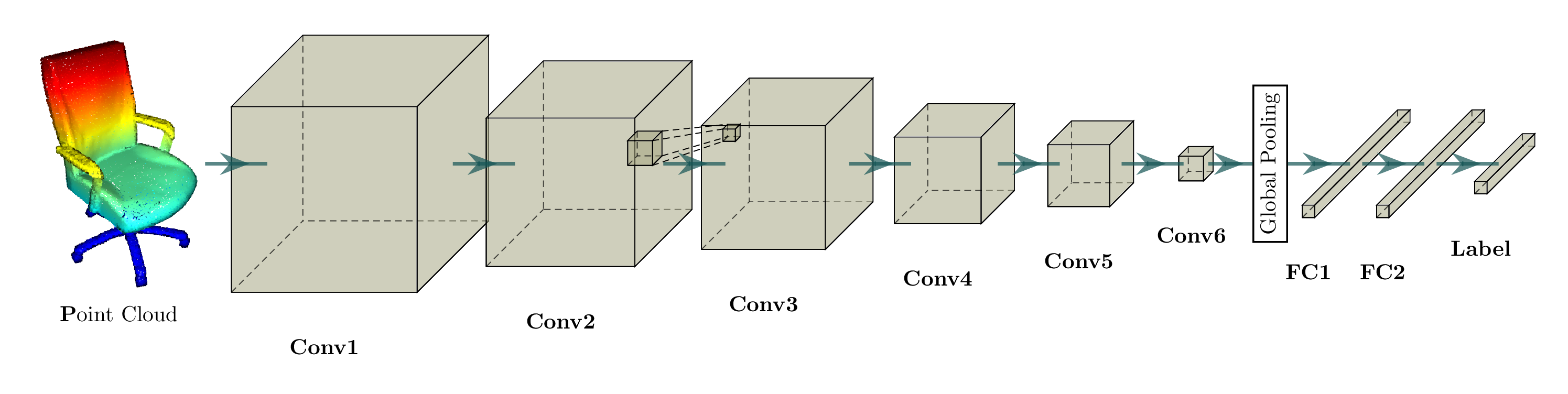 python -m examples.modelnet40 |
| Reconstruction |  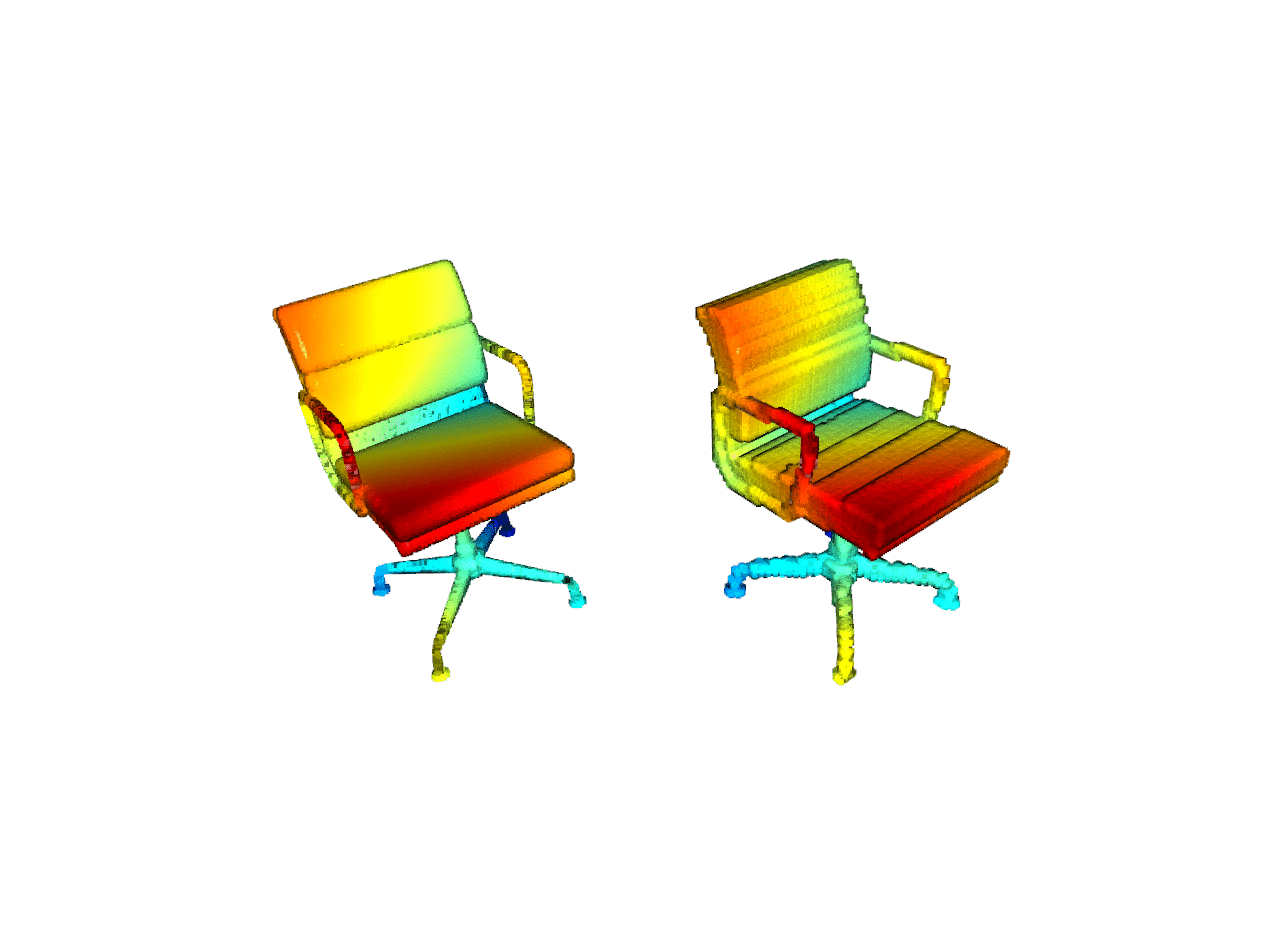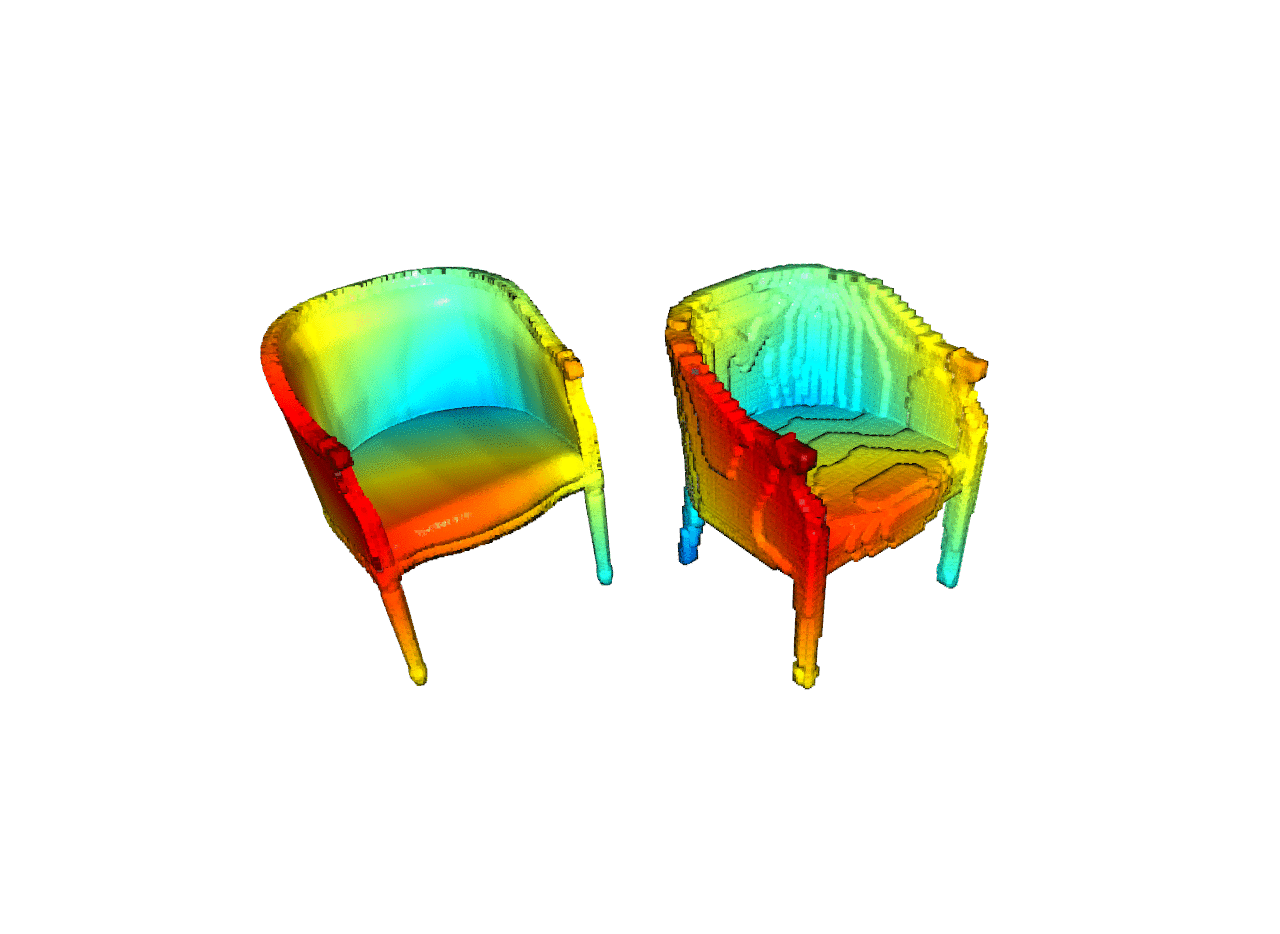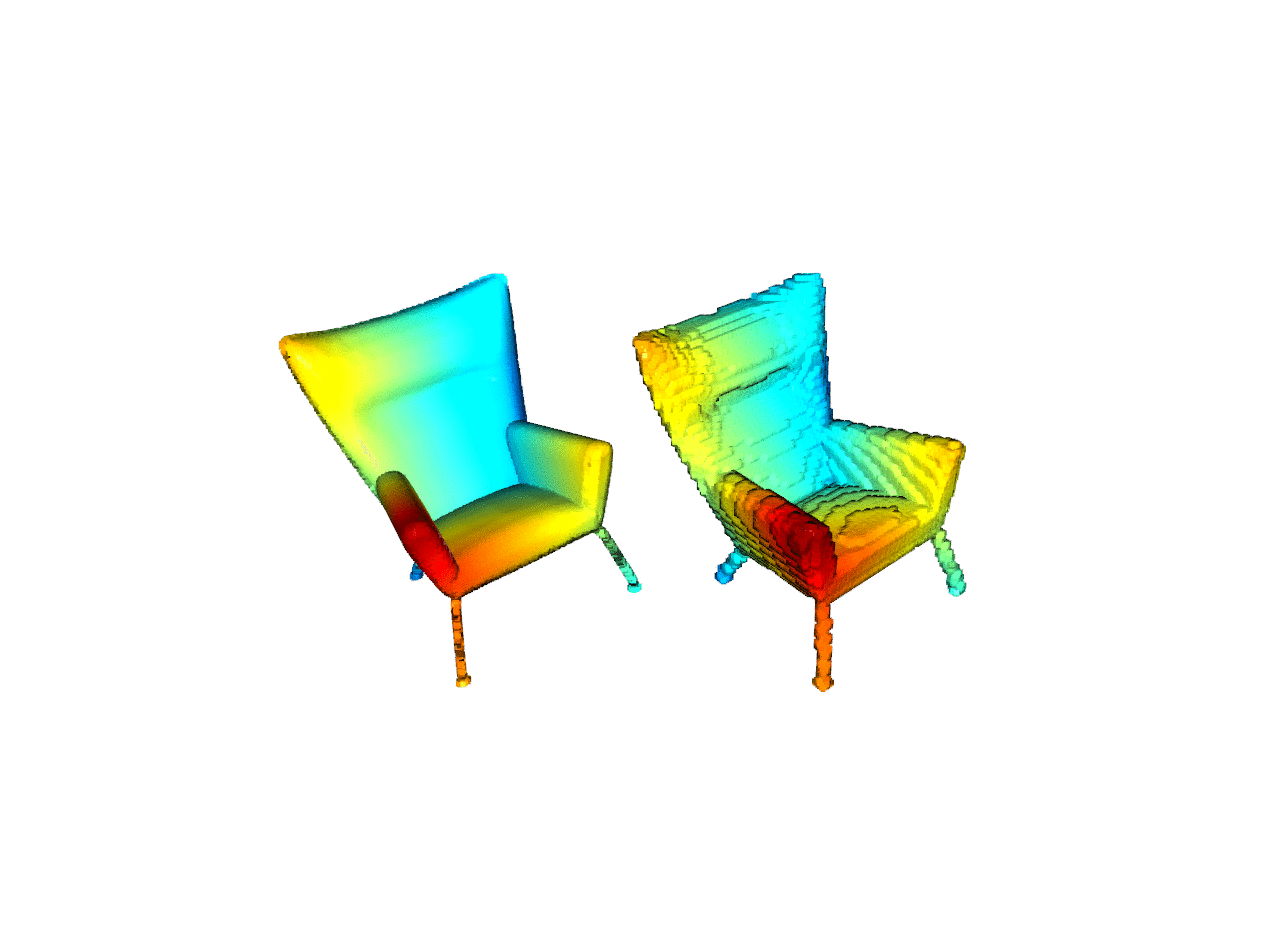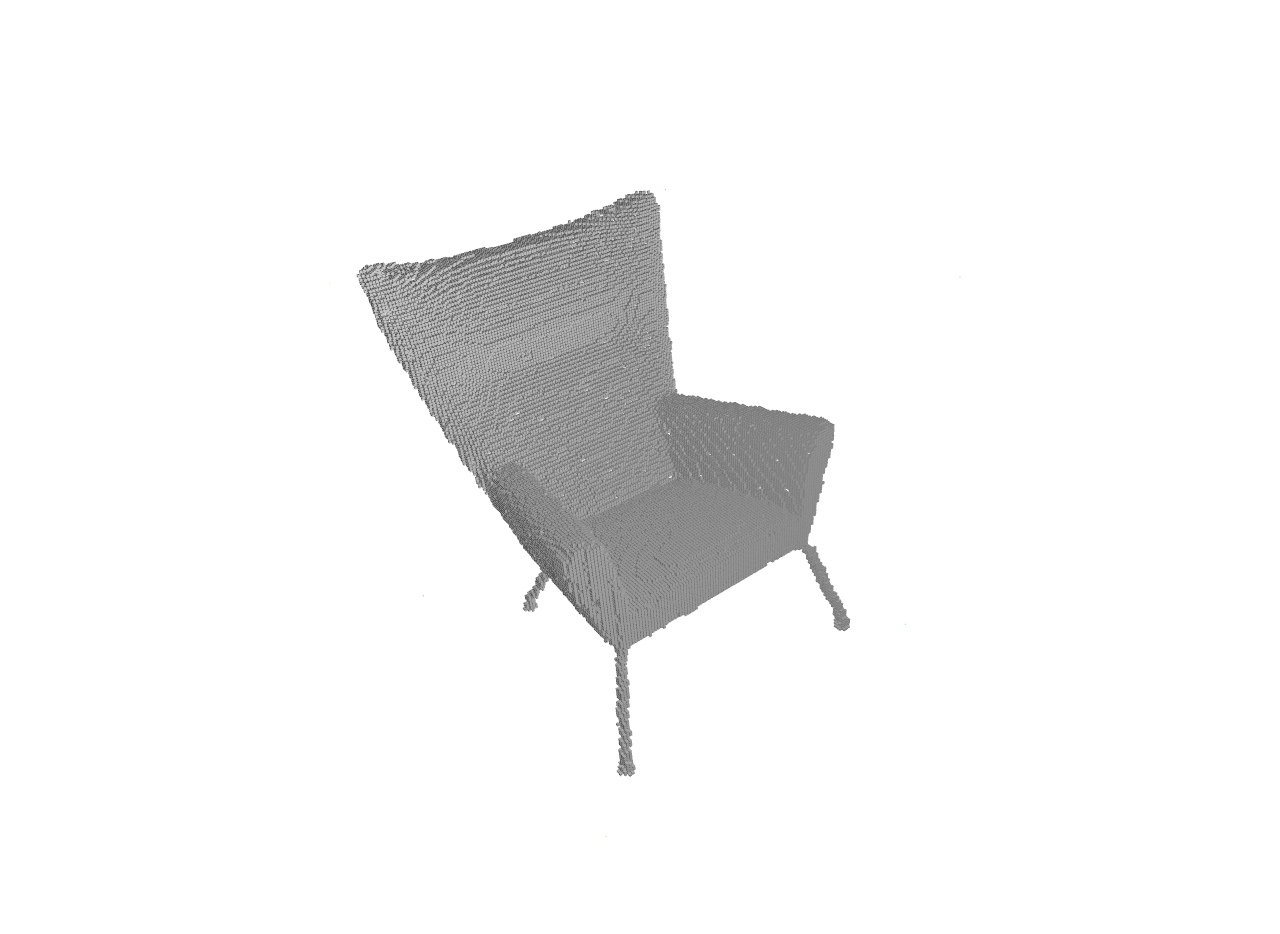 python -m examples.reconstruction |
| Completion |  python -m examples.completion |
| Detection | 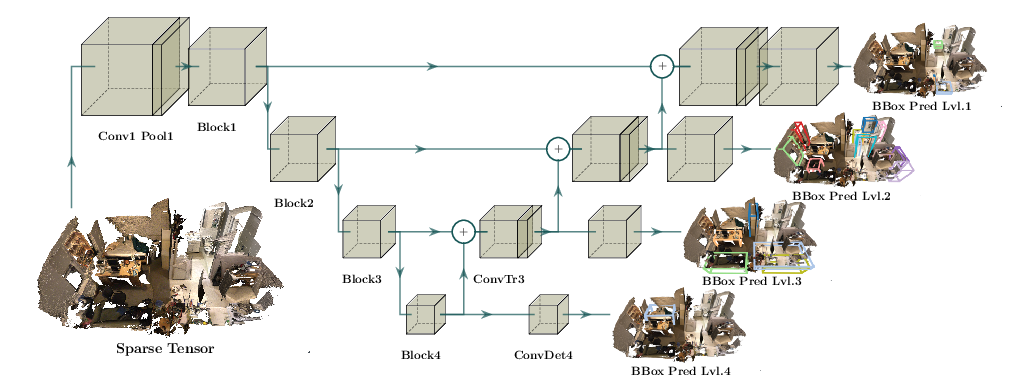 |
Sparse Tensor Networks: Neural Networks for Spatially Sparse Tensors
Compressing a neural network to speedup inference and minimize memory footprint has been studied widely. One of the popular techniques for model compression is pruning the weights in convnets, is also known as sparse convolutional networks. Such parameter-space sparsity used for model compression compresses networks that operate on dense tensors and all intermediate activations of these networks are also dense tensors.
However, in this work, we focus on spatially sparse data, in particular, spatially sparse high-dimensional inputs. We can also represent these data as sparse tensors, and these sparse tensors are commonplace in high-dimensional problems such as 3D perception, registration, and statistical data. We define neural networks specialized for these inputs as sparse tensor networks and these sparse tensor networks process and generate sparse tensors as outputs. To construct a sparse tensor network, we build all standard neural network layers such as MLPs, non-linearities, convolution, normalizations, pooling operations as the same way we define them on a dense tensor and implemented in the Minkowski Engine.
We visualized a sparse tensor network operation on a sparse tensor, convolution, below. The convolution layer on a sparse tensor works similarly to that on a dense tensor. However, on a sparse tensor, we compute convolution outputs on a few specified points which we can control in the generalized convolution. For more information, please visit the documentation page on sparse tensor networks and the terminology page.
| Dense Tensor | Sparse Tensor |
|---|---|
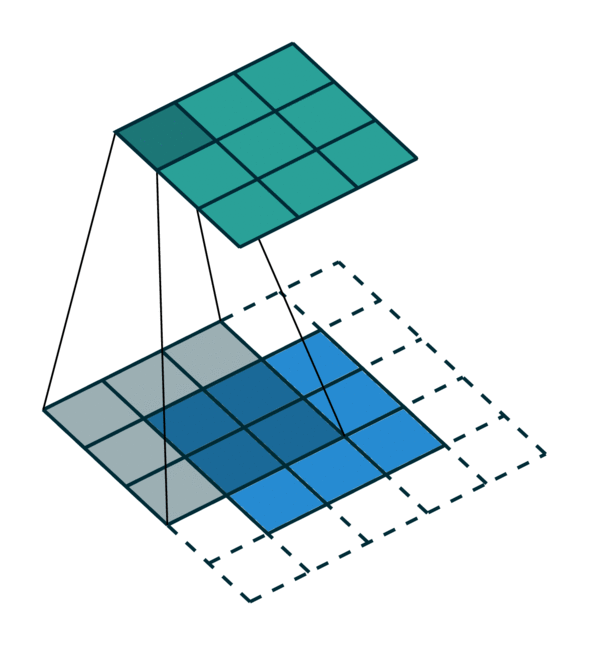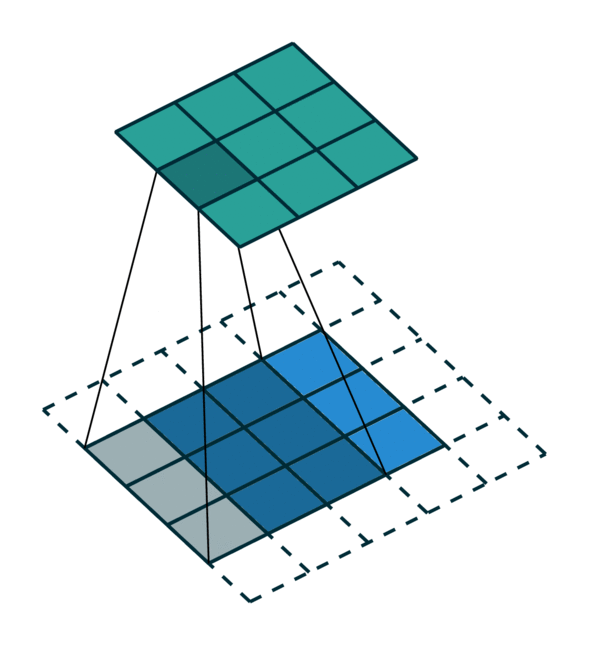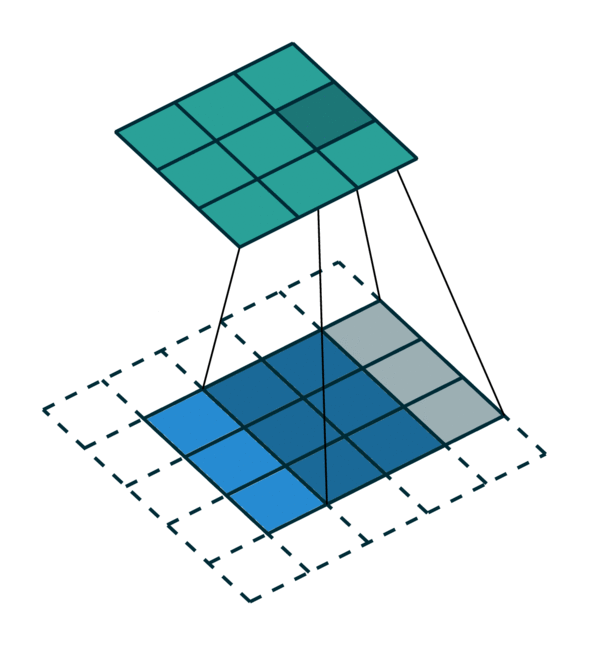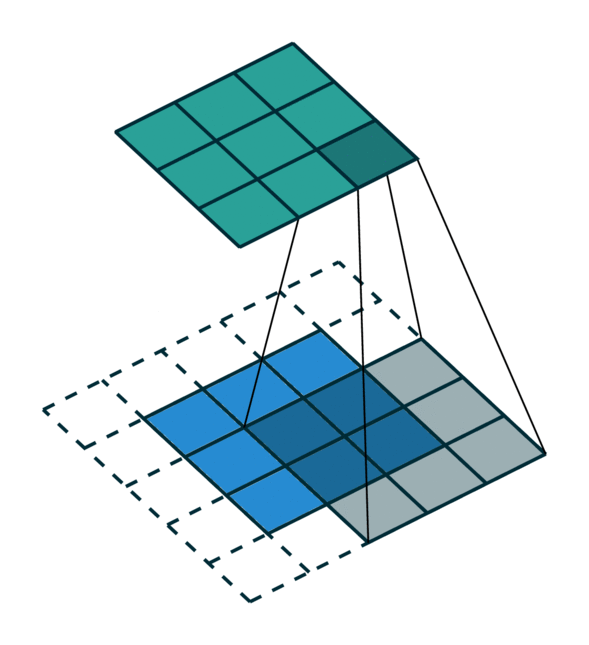 |
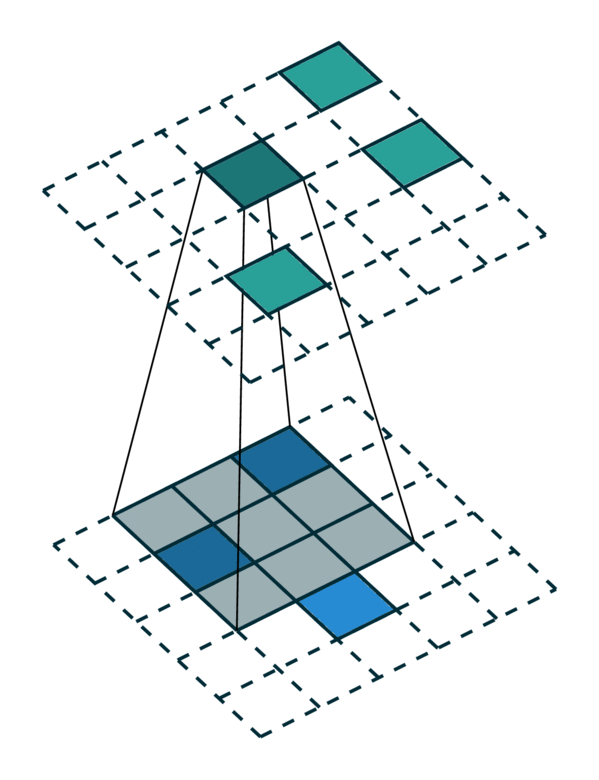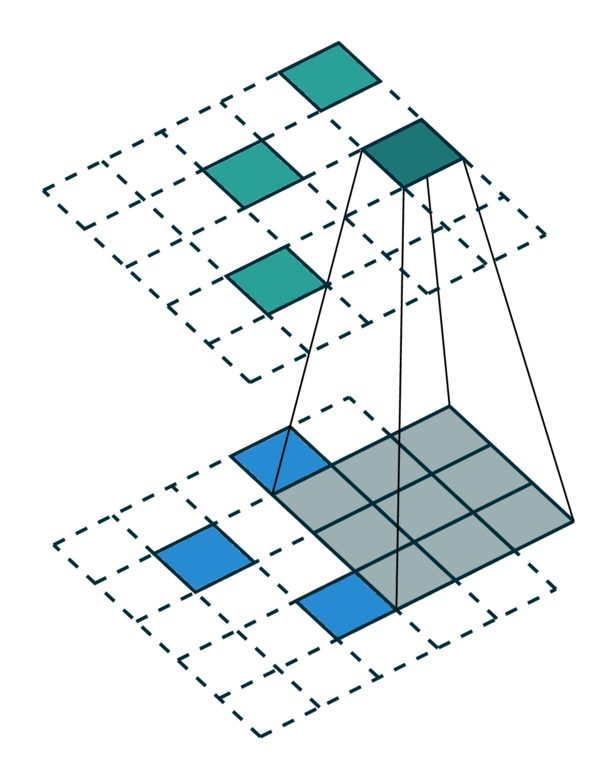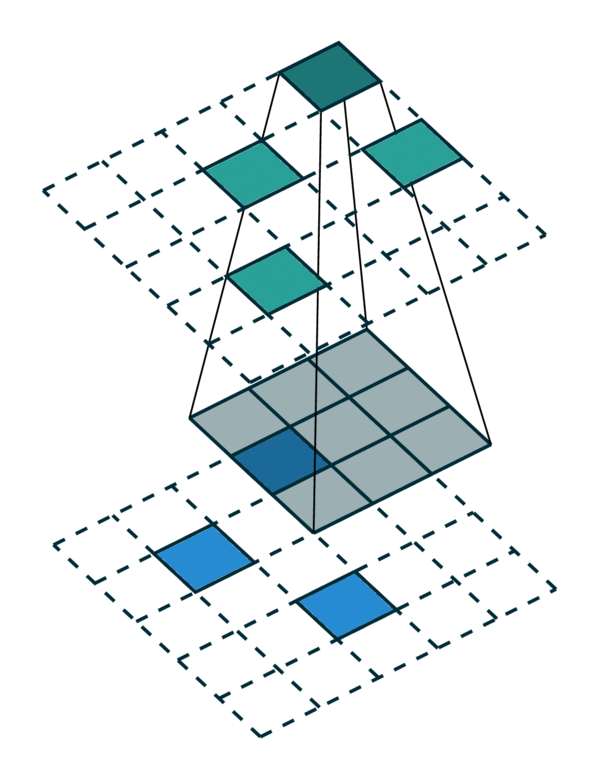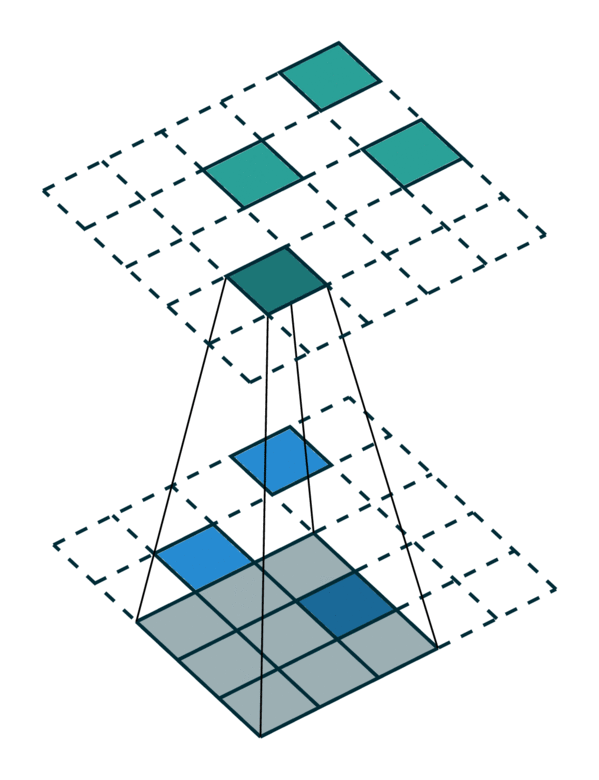 |
Features
- Unlimited high-dimensional sparse tensor support
- All standard neural network layers (Convolution, Pooling, Broadcast, etc.)
- Dynamic computation graph
- Custom kernel shapes
- Multi-GPU training
- Multi-threaded kernel map
- Multi-threaded compilation
- Highly-optimized GPU kernels
Requirements
- Ubuntu >= 14.04
- 11.1 > CUDA >= 10.1.243
- pytorch >= 1.5
- python >= 3.6
- GCC >= 7
Installation
You can install the Minkowski Engine with pip, with anaconda, or on the system directly. If you experience issues installing the package, please checkout the the installation wiki page.
If you cannot find a relevant problem, please report the issue on the github issue page.
Pip
The MinkowskiEngine is distributed via [PyPI MinkowskiEngine][pypi-url] which can be installed simply with pip.
First, install pytorch following the instruction. Next, install openblas.
sudo apt install libopenblas-dev
pip install torch
pip install -U MinkowskiEngine --install-option="--blas=openblas" -v
# For pip installation from the latest source
# pip install -U git+https://github.com/NVIDIA/MinkowskiEngine
If you want to specify arguments for the setup script, please refer to the following command.
# Uncomment some options if things don't work
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine \
# \ # uncomment the following line if you want to force cuda installation
# --install-option="--force_cuda" \
# \ # uncomment the following line if you want to force no cuda installation. force_cuda supercedes cpu_only
# --install-option="--cpu_only" \
# \ # uncomment the following line when torch fails to find cuda_home.
# --install-option="--cuda_home=/usr/local/cuda" \
# \ # uncomment the following line to override to openblas, atlas, mkl, blas
# --install-option="--blas=openblas" \
Anaconda
We recommend python>=3.6 for installation.
First, follow the anaconda documentation to install anaconda on your computer.
sudo apt install libopenblas-dev
conda create -n py3-mink python=3.8
conda activate py3-mink
conda install numpy mkl-include pytorch cudatoolkit=11.0 -c pytorch
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine
System Python
Like the anaconda installation, make sure that you install pytorch with the same CUDA version that nvcc uses.
# install system requirements
sudo apt install python3-dev libopenblas-dev
# Skip if you already have pip installed on your python3
curl https://bootstrap.pypa.io/get-pip.py | python3
# Get pip and install python requirements
python3 -m pip install torch numpy
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
python setup.py install
# To specify blas, CUDA_HOME and force CUDA installation, use the following command
# python setup.py install --blas=openblas --cuda_home=/usr/local/cuda --force_cuda
CPU only build and BLAS configuration (MKL)
The Minkowski Engine supports CPU only build on other platforms that do not have NVidia GPUs. Please refer to quick start for more details.
Quick Start
To use the Minkowski Engine, you first would need to import the engine.
Then, you would need to define the network. If the data you have is not
quantized, you would need to voxelize or quantize the (spatial) data into a
sparse tensor. Fortunately, the Minkowski Engine provides the quantization
function (MinkowskiEngine.utils.sparse_quantize).
Creating a Network
import torch.nn as nn
import MinkowskiEngine as ME
class ExampleNetwork(ME.MinkowskiNetwork):
def __init__(self, in_feat, out_feat, D):
super(ExampleNetwork, self).__init__(D)
self.conv1 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=in_feat,
out_channels=64,
kernel_size=3,
stride=2,
dilation=1,
has_bias=False,
dimension=D),
ME.MinkowskiBatchNorm(64),
ME.MinkowskiReLU())
self.conv2 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=2,
dimension=D),
ME.MinkowskiBatchNorm(128),
ME.MinkowskiReLU())
self.pooling = ME.MinkowskiGlobalPooling()
self.linear = ME.MinkowskiLinear(128, out_feat)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.pooling(out)
return self.linear(out)
Forward and backward using the custom network
# loss and network
criterion = nn.CrossEntropyLoss()
net = ExampleNetwork(in_feat=3, out_feat=5, D=2)
print(net)
# a data loader must return a tuple of coords, features, and labels.
coords, feat, label = data_loader()
input = ME.SparseTensor(feat, coords=coords)
# Forward
output = net(input)
# Loss
loss = criterion(output.F, label)
Discussion and Documentation
For discussion and questions, please use [email protected].
For API and general usage, please refer to the MinkowskiEngine documentation
page for more detail.
For issues not listed on the API and feature requests, feel free to submit
an issue on the github issue
page.
Known Issues
Too much GPU memory usage or Frequent Out of Memory
MinkowskiEngine is a specialized library that can handle different number of points or different number of non-zero elements at every iteration during training, which is common in point cloud data.
However, pytorch is implemented assuming that the number of point, or size of the activations do not change at every iteration. Thus, the GPU memory caching used by pytorch can result in unnecessarily large memory consumption.
Specifically, pytorch caches chunks of memory spaces to speed up allocation used in every tensor creation. If it fails to find the memory space, it splits an existing cached memory or allocate new space if there's no cached memory large enough for the requested size. Thus, every time we use different number of point (number of non-zero elements) with pytorch, it either split existing cache or reserve new memory. If the cache is too fragmented and allocated all GPU space, it will raise out of memory error.
To prevent this, you must clear the cache at regular interval with torch.cuda.empty_cache().
Running the MinkowskiEngine on nodes with a large number of CPUs
The MinkowskiEngine uses OpenMP to parallelize the kernel map generation. However, when the number of threads used for parallelization is too large (e.g. OMP_NUM_THREADS=80), the efficiency drops rapidly as all threads simply wait for multithread locks to be released.
In such cases, set the number of threads used for OpenMP. Usually, any number below 24 would be fine, but search for the optimal setup on your system.
export OMP_NUM_THREADS=<number of threads to use>; python <your_program.py>
Citing Minkowski Engine
If you use the Minkowski Engine, please cite:
@inproceedings{choy20194d,
title={4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks},
author={Choy, Christopher and Gwak, JunYoung and Savarese, Silvio},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={3075--3084},
year={2019}
}
For multi-threaded kernel map generation, please cite:
@inproceedings{choy2019fully,
title={Fully Convolutional Geometric Features},
author={Choy, Christopher and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={8958--8966},
year={2019}
}
For strided pooling layers for high-dimensional convolutions, please cite:
@inproceedings{choy2020high,
title={High-dimensional Convolutional Networks for Geometric Pattern Recognition},
author={Choy, Christopher and Lee, Junha and Ranftl, Rene and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
For generative transposed convolution, please cite:
@inproceedings{gwak2020gsdn,
title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
booktitle={European conference on computer vision},
year={2020}
}
Unittest
For unittests and gradcheck, use torch >= 1.7



