Distiller is an open-source Python package for neural network compression research.
Network compression can reduce the memory footprint of a neural network, increase its inference speed and save energy. Distiller provides a PyTorch environment for prototyping and analyzing compression algorithms, such as sparsity-inducing methods and low-precision arithmetic.
Highlighted features
- Automatic Compression
- Automated Model Compression (AMC)
- Weight pruning
- Element-wise pruning using magnitude thresholding, sensitivity thresholding, target sparsity level, and activation statistics
- Structured pruning
- Convolution: 2D (kernel-wise), 3D (filter-wise), 4D (layer-wise), and channel-wise structured pruning.
- Fully-connected: column-wise and row-wise structured pruning.
- Structure groups (e.g. structures of 4 filters).
- Structure-ranking with using weights or activations criteria (Lp-norm, APoZ, gradients, random, etc.).
- Support for new structures (e.g. block pruning)
- Control
- Soft (mask on forward-pass only) and hard pruning (permanently disconnect neurons)
- Dual weight copies (compute loss on masked weights, but update unmasked weights)
- Model thinning (AKA "network garbage removal") to permanently remove pruned neurons and connections.
- Schedule
- Flexible scheduling of pruning, regularization, and learning rate decay (compression scheduling)
- One-shot and iterative pruning (and fine-tuning) are supported.
- Easily control what is performed each training step (e.g. greedy layer by layer pruning to full model pruning).
- Automatic gradual schedule (AGP) for pruning individual connections and complete structures.
- The compression schedule is expressed in a YAML file so that a single file captures the details of experiments. This dependency injection design decouples the Distiller scheduler and library from future extensions of algorithms.
- Element-wise and filter-wise pruning sensitivity analysis (using L1-norm thresholding). Examine the data from some of the networks we analyzed, using this notebook.
- Regularization
- L1-norm element-wise regularization
- Group Lasso an group variance regularization
- Quantization
- Automatic mechanism to transform existing models to quantized versions, with customizable bit-width configuration for different layers. No need to re-write the model for different quantization methods.
- Post-training quantization of trained full-precision models, dynamic and static (statistics-based)
- Support for quantization-aware training in the loop
- Knowledge distillation
- Training with knowledge distillation, in conjunction with the other available pruning / regularization / quantization methods.
- Conditional computation
- Sample implementation of Early Exit
- Low rank decomposition
- Sample implementation of truncated SVD
- Lottery Ticket Hypothesis training
- Export statistics summaries using Pandas dataframes, which makes it easy to slice, query, display and graph the data.
- A set of Jupyter notebooks to plan experiments and analyze compression results. The graphs and visualizations you see on this page originate from the included Jupyter notebooks.
- Take a look at this notebook, which compares visual aspects of dense and sparse Alexnet models.
- This notebook creates performance indicator graphs from model data.
- Sample implementations of published research papers, using library-provided building blocks. See the research papers discussions in our model-zoo.
- Logging to the console, text file and TensorBoard-formatted file.
- Export to ONNX (export of quantized models pending ONNX standardization)
Installation
These instructions will help get Distiller up and running on your local machine.
1. Clone Distiller
Clone the Distiller code repository from github:
$ git clone https://github.com/IntelLabs/distiller.git
The rest of the documentation that follows, assumes that you have cloned your repository to a directory called distiller.
2. Create a Python virtual environment
We recommend using a Python virtual environment, but that of course, is up to you.
There's nothing special about using Distiller in a virtual environment, but we provide some instructions, for completeness.
Before creating the virtual environment, make sure you are located in directory distiller. After creating the environment, you should see a directory called distiller/env.
Using virtualenv
If you don't have virtualenv installed, you can find the installation instructions here.
To create the environment, execute:
$ python3 -m virtualenv env
This creates a subdirectory named env where the python virtual environment is stored, and configures the current shell to use it as the default python environment.
Using venv
If you prefer to use venv, then begin by installing it:
$ sudo apt-get install python3-venv
Then create the environment:
$ python3 -m venv env
As with virtualenv, this creates a directory called distiller/env.
Activate the environment
The environment activation and deactivation commands for venv and virtualenv are the same.
!NOTE: Make sure to activate the environment, before proceeding with the installation of the dependency packages:
$ source env/bin/activate
3. Install the Distiller package
Finally, install the Distiller package and its dependencies using pip3:
$ cd distiller
$ pip3 install -e .
This installs Distiller in "development mode", meaning any changes made in the code are reflected in the environment without re-running the install command (so no need to re-install after pulling changes from the Git repository).
Notes:
- Distiller has only been tested on Ubuntu 16.04 LTS, and with Python 3.5.
- If you are not using a GPU, you might need to make small adjustments to the code.
Required PyTorch Version
Distiller is tested using the default installation of PyTorch 1.3.1, which uses CUDA 10.1. We use TorchVision version 0.4.2. These are included in Distiller's requirements.txt and will be automatically installed when installing the Distiller package as listed above.
If you do not use CUDA 10.1 in your environment, please refer to PyTorch website to install the compatible build of PyTorch 1.3.1 and torchvision 0.4.2.
Getting Started
Distiller comes with sample applications and tutorials covering a range of model types:
| Model Type | Sparsity | Post-training quantization | Quantization-aware training | Auto Compression (AMC) | Knowledge Distillation |
|---|---|---|---|---|---|
| Image classification | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| Word-level language model | :white_check_mark: | :white_check_mark: | |||
| Translation (GNMT) | :white_check_mark: | ||||
| Recommendation System (NCF) | :white_check_mark: | ||||
| Object Detection | :white_check_mark: |
Head to the examples directory for more details.
Other resources to refer to, beyond the examples:
- Frequently-asked questions (FAQ)
- Model zoo
- Compression scheduling
- Usage
- Preparing a model for quantization
- Tutorial: Pruning Filters & Channels
Basic Usage Examples
The following are simple examples using Distiller's image classifcation sample, showing some of Distiller's capabilities.
Example: Simple training-only session (no compression)
The following will invoke training-only (no compression) of a network named 'simplenet' on the CIFAR10 dataset. This is roughly based on TorchVision's sample Imagenet training application, so it should look familiar if you've used that application. In this example we don't invoke any compression mechanisms: we just train because for fine-tuning after pruning, training is an essential part.
Note that the first time you execute this command, the CIFAR10 code will be downloaded to your machine, which may take a bit of time - please let the download process proceed to completion.
The path to the CIFAR10 dataset is arbitrary, but in our examples we place the datasets in the same directory level as distiller (i.e. ../../../data.cifar10).
First, change to the sample directory, then invoke the application:
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
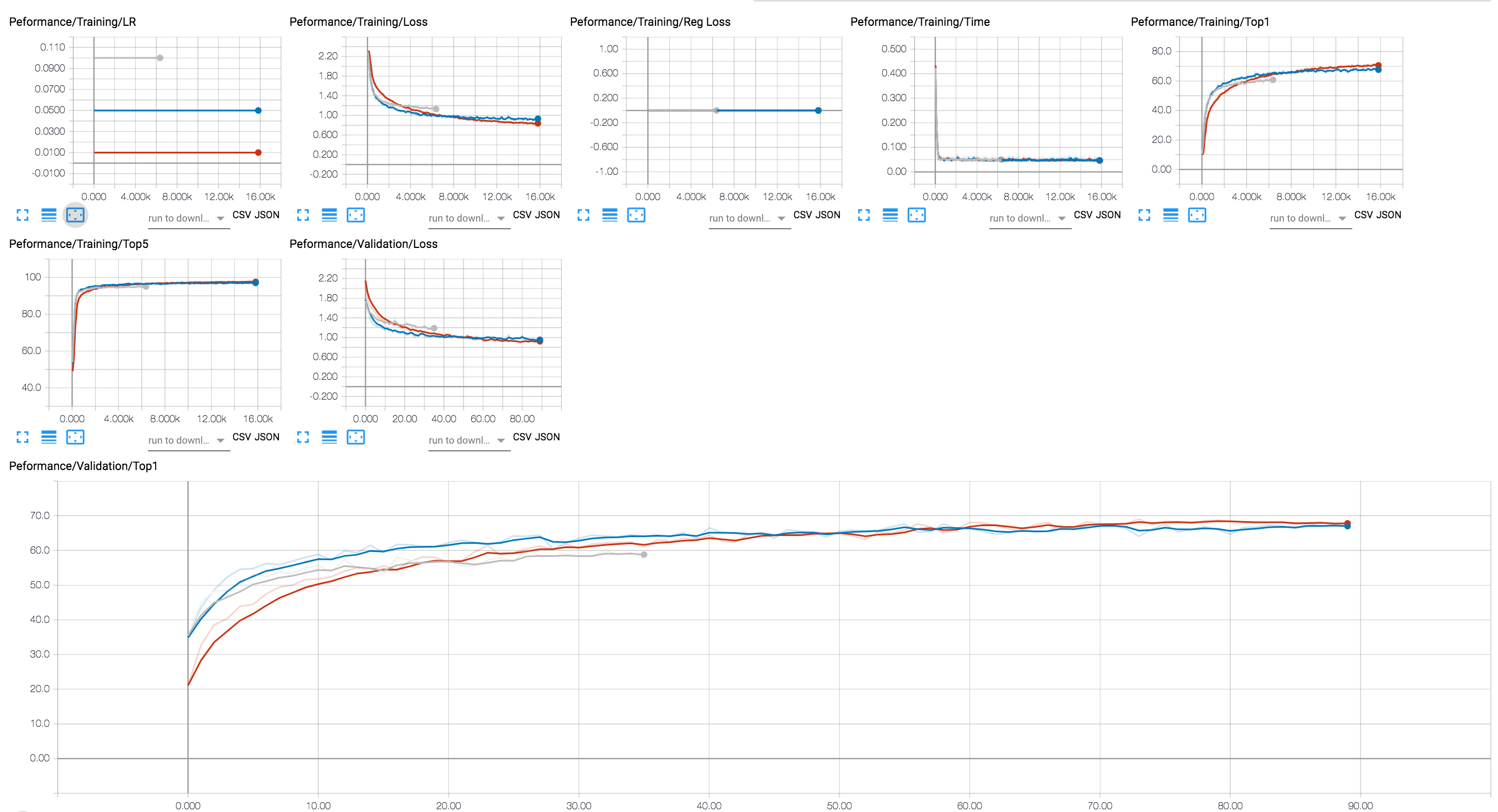
You can use a TensorBoard backend to view the training progress (in the diagram below we show a couple of training sessions with different LR values). For compression sessions, we've added tracing of activation and parameter sparsity levels, and regularization loss.
Example: Getting parameter statistics of a sparsified model
We've included in the git repository a few checkpoints of a ResNet20 model that we've trained with 32-bit floats. Let's load the checkpoint of a model that we've trained with channel-wise Group Lasso regularization.
With the following command-line arguments, the sample application loads the model (--resume) and prints statistics about the model weights (--summary=sparsity). This is useful if you want to load a previously pruned model, to examine the weights sparsity statistics, for example. Note that when you resume a stored checkpoint, you still need to tell the application which network architecture the checkpoint uses (-a=resnet20_cifar):
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
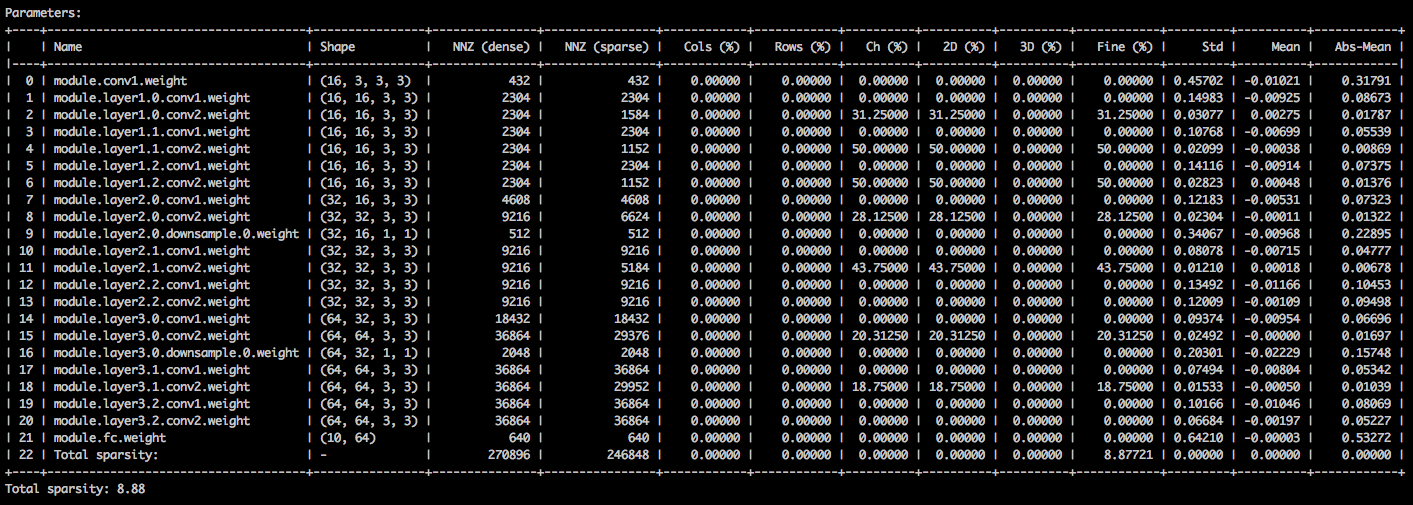
You should see a text table detailing the various sparsities of the parameter tensors. The first column is the parameter name, followed by its shape, the number of non-zero elements (NNZ) in the dense model, and in the sparse model. The next set of columns show the column-wise, row-wise, channel-wise, kernel-wise, filter-wise and element-wise sparsities.
Wrapping it up are the standard-deviation, mean, and mean of absolute values of the elements.
In the Compression Insights notebook we use matplotlib to plot a bar chart of this summary, that indeed show non-impressive footprint compression.
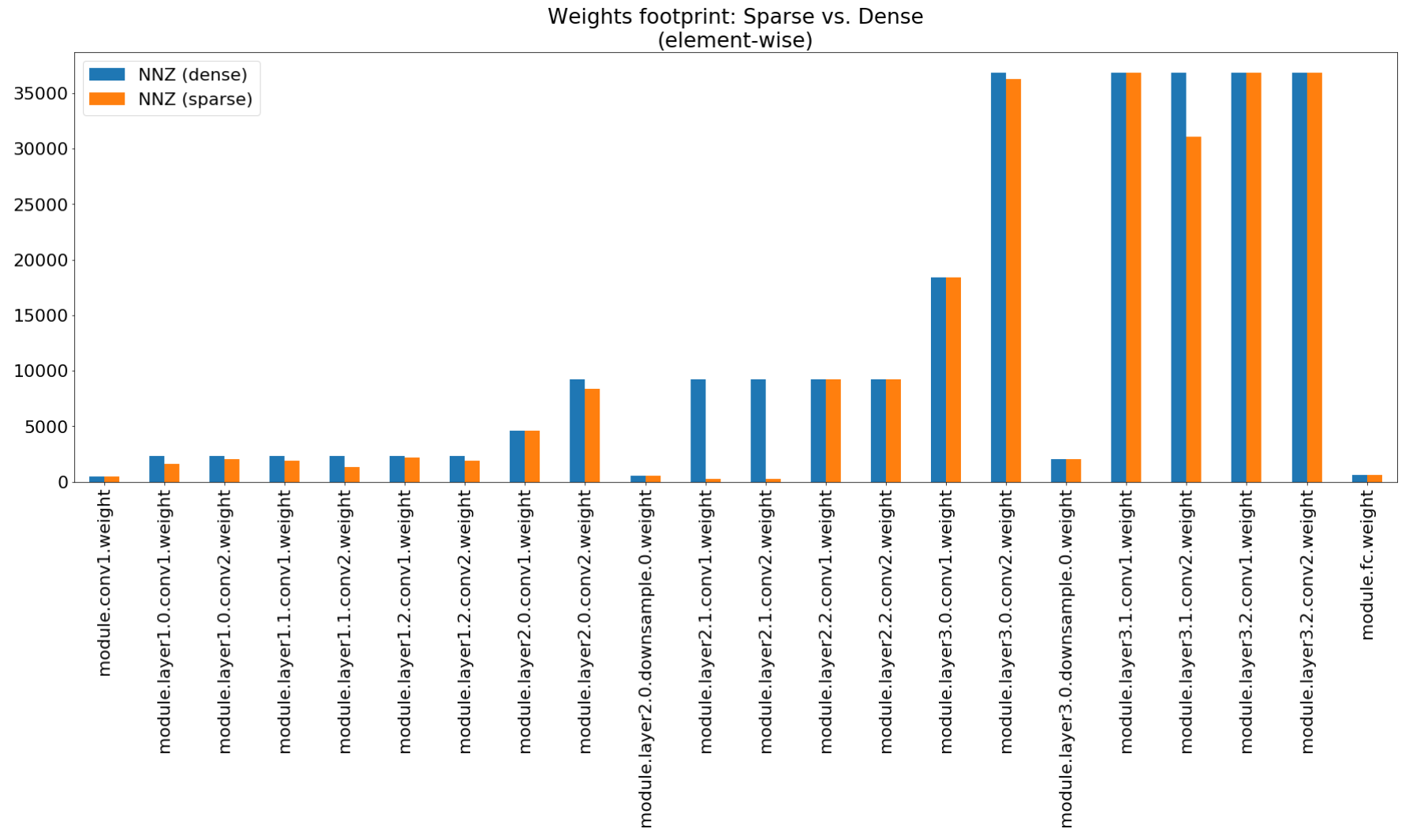
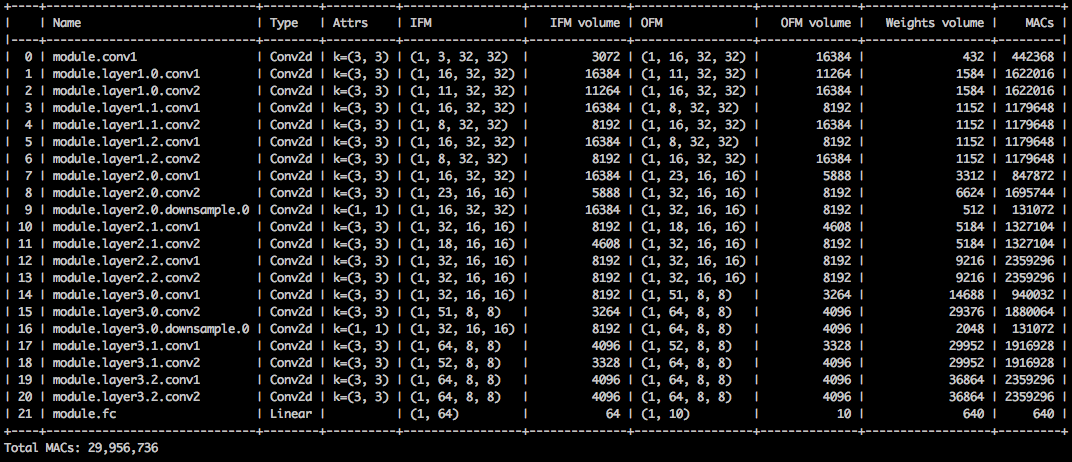
Although the memory footprint compression is very low, this model actually saves 26.6% of the MACs compute.
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
Example: Post-training quantization
This example performs 8-bit quantization of ResNet20 for CIFAR10. We've included in the git repository the checkpoint of a ResNet20 model that we've trained with 32-bit floats, so we'll take this model and quantize it:
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
The command-line above will save a checkpoint named quantized_checkpoint.pth.tar containing the quantized model parameters. See more examples here.
Explore the sample Jupyter notebooks
The set of notebooks that come with Distiller is described here, which also explains the steps to install the Jupyter notebook server.
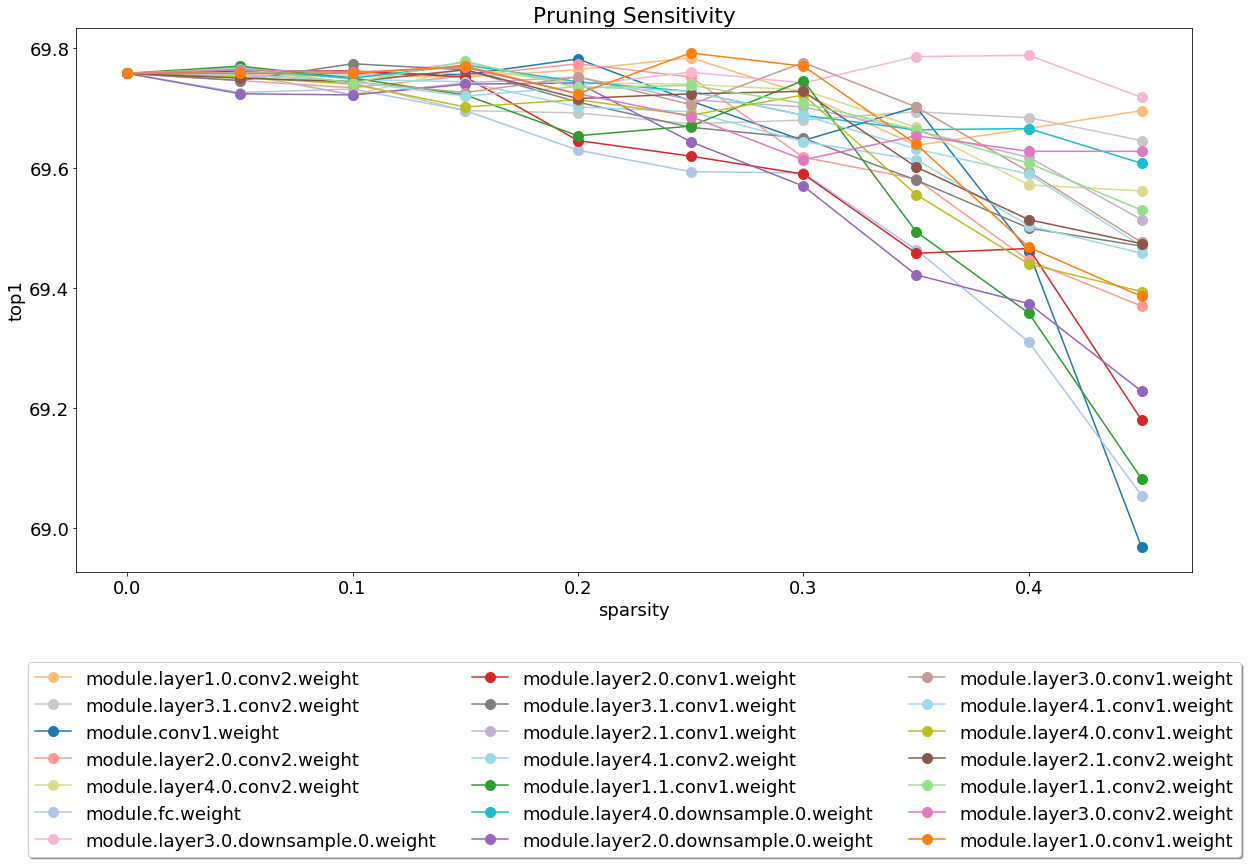
After installing and running the server, take a look at the notebook covering pruning sensitivity analysis.
Sensitivity analysis is a long process and this notebook loads CSV files that are the output of several sessions of sensitivity analysis.
Running the tests
We are currently light-weight on test and this is an area where contributions will be much appreciated.
There are two types of tests: system tests and unit-tests. To invoke the unit tests:
$ cd distiller/tests
$ pytest
We use CIFAR10 for the system tests, because its size makes for quicker tests. To invoke the system tests, you need to provide a path to the CIFAR10 dataset which you've already downloaded. Alternatively, you may invoke full_flow_tests.py without specifying the location of the CIFAR10 dataset and let the test download the dataset (for the first invocation only). Note that --cifar1o-path defaults to the current directory.
The system tests are not short, and are even longer if the test needs to download the dataset.
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
The script exits with status 0 if all tests are successful, or status 1 otherwise.
Generating the HTML documentation site
Install mkdocs and the required packages by executing:
$ pip3 install -r doc-requirements.txt
To build the project documentation run:
$ cd distiller/docs-src
$ mkdocs build --clean
This will create a folder named 'site' which contains the documentation website.
Open distiller/docs/site/index.html to view the documentation home page.
Versioning
We use SemVer for versioning. For the versions available, see the tags on this repository.
License
This project is licensed under the Apache License 2.0 - see the LICENSE.md file for details
Community
Github projects using Distiller
DeGirum Pruned Models - a repository containing pruned models and related information.
TorchFI - TorchFI is a fault injection framework build on top of PyTorch for research purposes.
hsi-toolbox - Hyperspectral CNN compression and band selection
Research papers citing Distiller
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe M. G. Franca.
Reliability Evaluation of Compressed Deep Learning Models,
In IEEE 11th Latin American Symposium on Circuits & Systems (LASCAS), San Jose, Costa Rica, 2020, pp. 1-5.
Pascal Bacchus, Robert Stewart, Ekaterina Komendantskaya.
Accuracy, Training Time and Hardware Efficiency Trade-Offs for Quantized Neural Networks on FPGAs,
In Applied Reconfigurable Computing. Architectures, Tools, and Applications. ARC 2020. Lecture Notes in Computer Science, vol 12083. Springer, Cham
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy.
GENIEx: A Generalized Approach to Emulating Non-Ideality in Memristive Xbars using Neural Networks,
arXiv:2003.06902, 2020.
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban Deledalle, Hadi Esmaeilzadeh.
Gradient-Based Deep Quantization of Neural Networks through Sinusoidal
Adaptive Regularization,
arXiv:2003.00146, 2020.
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu.
TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing,
arXiv:2002.12620, 2020.
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbachev.
Neural Network Compression Framework for fast model inference,
arXiv:2002.08679, 2020.
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser.
Robust Quantization: One Model to Rule Them All,
arXiv:2002.07686, 2020.
Muhammad Abdullah Hanif, Muhammad Shafique.
SalvageDNN: salvaging deep neural network accelerators with permanent faults through saliency-driven fault-aware mapping,
In Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering SciencesVolume 378, Issue 2164, 2019.
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao Mo, Jun Lin, Zhongfeng Wang, Li Du.
DynExit: A Dynamic Early-Exit Strategy for Deep Residual Networks,
In IEEE International Workshop on Signal Processing Systems (SiPS), 2019.
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan.
A Programmable Approach to Model Compression,
arXiv:1911.02497, 2019
code
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-Hwan Lim.
In-Place Zero-Space Memory Protection for CNN,
In Conference on Neural Information Processing Systems (NeurIPS), 2019.
arXiv:1910.14479, 2019
code
Hossein Baktash, Emanuele Natale, Laurent Viennot.
A Comparative Study of Neural Network Compression,
arXiv:1910.11144, 2019.
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov.
512KiB RAM Is Enough! Live Camera Face Recognition DNN on MCU,
In IEEE International Conference on Computer Vision (ICCV), 2019.
Ziheng Wang, Jeremy Wohlwend, Tao Lei.
Structured Pruning of Large Language Models,
arXiv:1910.04732, 2019.
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh.
Mixed-Signal Charge-Domain Acceleration of Deep Neural networks through Interleaved Bit-Partitioned Arithmetic,
arXiv:1906.11915, 2019.
Gil Shomron, Tal Horowitz, Uri Weiser.
SMT-SA: Simultaneous Multithreading in Systolic Arrays,
In IEEE Computer Architecture Letters (CAL), 2019.
Shangqian Gao , Cheng Deng , and Heng Huang.
Cross Domain Model Compression by Structurally Weight Sharing,
In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 8973-8982.
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass.
FAKTA: An Automatic End-to-End Fact Checking System,
In North American Chapter of the Association for Computational Linguistics (NAACL), 2019.
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
SinReQ: Generalized Sinusoidal Regularization for Low-Bitwidth Deep Quantized Training,
arXiv:1905.01416, 2019.
code
Goncharenko A., Denisov A., Alyamkin S., Terentev E.
Trainable Thresholds for Neural Network Quantization,
In: Rojas I., Joya G., Catala A. (eds) Advances in Computational Intelligence Lecture Notes in Computer Science, vol 11507. Springer, Cham. International Work-Conference on Artificial Neural Networks (IWANN 2019).
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Divide and Conquer: Leveraging Intermediate Feature Representations for Quantized Training of Neural Networks,
arXiv:1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher De Sa, Zhiru Zhang.
Improving Neural Network Quantization without Retraining using Outlier Channel Splitting,
arXiv:1901.09504, 2019
Code
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Gray.
Analog/Mixed-Signal Hardware Error Modeling for Deep Learning Inference,
Nvidia Research, 2019.
Norio Nakata.
Recent Technical Development of Artificial Intelligence for Diagnostic Medical Imaging,
In Japanese Journal of Radiology, February 2019, Volume 37, Issue 2, pp 103–108.
Alexander Goncharenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terentev.
Fast Adjustable Threshold For Uniform Neural Network Quantization,
arXiv:1812.07872, 2018
If you used Distiller for your work, please use the following citation:
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
Acknowledgments
Any published work is built on top of the work of many other people, and the credit belongs to too many people to list here.
- The Python and PyTorch developer communities have shared many invaluable insights, examples and ideas on the Web.
- The authors of the research papers implemented in the Distiller model-zoo have shared their research ideas, theoretical background and results.
Built With
- PyTorch - The tensor and neural network framework used by Distiller.
- Jupyter - Notebook serving.
- TensorBoard - Used to view training graphs.
- Cadene - Pretrained PyTorch models.
Disclaimer
Distiller is released as a reference code for research purposes. It is not an official Intel product, and the level of quality and support may not be as expected from an official product. Additional algorithms and features are planned to be added to the library. Feedback and contributions from the open source and research communities are more than welcome.
 IntelLabs
IntelLabs






