DocFace
Matching ID Document Photos to Selfies.
Update Notes
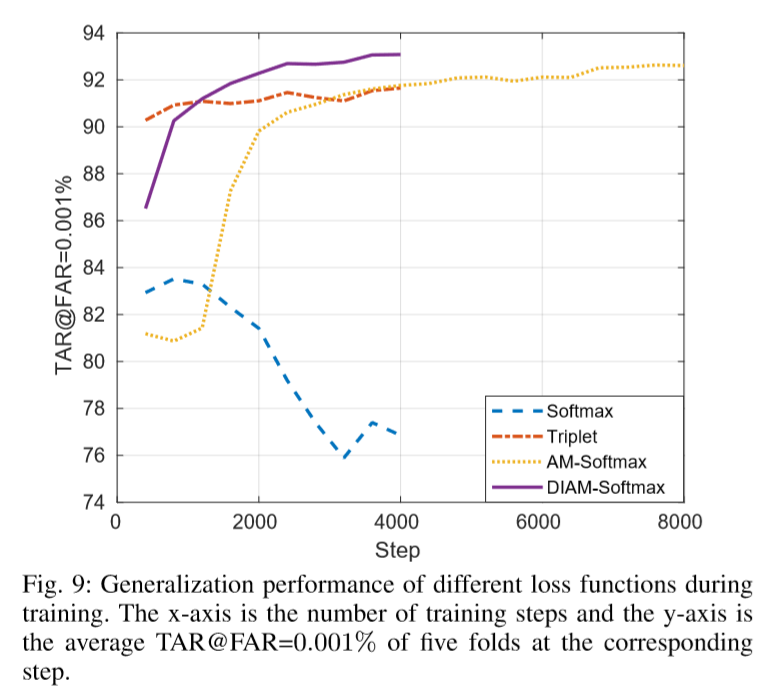
09/20/2018: The content of DocFace+ is added, including DIAM-Softmax, partially shared sibling networks and support for multiple ID/selfie per class.
This repository includes the TensorFlow implementation of DocFace and DocFace+, which is a system proposed for matching ID photos and live face photos. DocFace is shown to significantly outperform general face matchers on the ID-Selfie matching problem. We here give the example training code and pre-trained models in the paper. For the preprocessing part, we follow the repository of SphereFace to align the face images using MTCNN. The user can also use other methods for face alignment. Because the dataset used in the paper is private, we cannot publish it here. One can test the system on their own dataset.
Citation
@article{shi2018docface+,
title = {DocFace+: ID Document to Selfie Matching},
author = {Shi, Yichun and Jain, Anil K.},
booktitle = {arXiv:1809.05620},
year = {2018}
}
@article{shi2018docface,
title = {DocFace: Matching ID Document Photos to Selfies},
author = {Shi, Yichun and Jain, Anil K.},
booktitle = {arXiv:1805.02283},
year = {2018}
}
Requirements
- Requirements for
Python3 - Requirements for
Tensorflow r1.2or newer versions. - Run
pip install -r requirements.txtfor other dependencies.
Usage
Part 1: Preprocessing
1.1 Dataset Structure
Download the Ms-Celeb-1M and LFW dataset for training and testing the base model. Other dataset such as CASIA-Webface can also be used for training. Because Ms-Celeb-1M is known to be a very noisy dataset, we use the clean list provided by Wu et al. Arrange Ms-Celeb-1M dataset and LFW dataset as the following structure, where each subfolder represents a subject:
Aaron_Eckhart
Aaron_Eckhart_0001.jpg
Aaron_Guiel
Aaron_Guiel_0001.jpg
Aaron_Patterson
Aaron_Patterson_0001.jpg
Aaron_Peirsol
Aaron_Peirsol_0001.jpg
Aaron_Peirsol_0002.jpg
Aaron_Peirsol_0003.jpg
Aaron_Peirsol_0004.jpg
...
For the ID-Selfie dataset, make sure all the foldesr in such a structure, where ID images and selfies start with "A" and "B", respectively :
Subject1
A001.jpg
B001.jpg
B002.jpg
Subject2
A001.jpg
B001.jpg
...
1.2 Face Alignment
We align all the face images following the SphereFace. The user is recommended to use their code for face alignment. It is okay to use other face alignment methods, but make sure all the images are resized to 96 x 112. Users can also use an input size of 112 x 112 by changing the "image_size" in the configuration files.
Part 2: Training
Note: In this part, we assume you are in the directory $DOCFACE_ROOT/
2.1 Training the base model
-
Set up the dataset paths in
config/basemodel.py:# Training dataset path train_dataset_path = '/path/to/msceleb1m/dataset/folder' # Testing dataset path test_dataset_path = '/path/to/lfw/dataset/folder' -
Due to the memory cost, the user may need more than one GPUs to use a batch size of
256on Ms-Celeb-1M. In particular, we used four GTX 1080 Ti GPUs. In such cases, change the following entry inconfig/basemodel.py:# Number of GPUs num_gpus = 1 -
Run the following command in the terminal:
python src/train_base.py config/basemodel.pyAfter training, a model folder will appear under
log/faceres_ms/. We will use it for fine-tuning. If the training code is run more than once, multiple folders will appear with time stamps as their names. The user can also skip this part and use the pre-trained base model we provide.
2.2 Fine-tuning on the ID-Selfie datasets
-
Set up the dataset paths and the pre-trained model path in
config/finetune.py# Training dataset path train_dataset_path = '/path/to/training/dataset/folder' # Testing dataset path test_dataset_path = '/path/to/testing/dataset/folder' ... # The model folder from which to retore the parameters restore_model = '/path/to/the/pretrained/model/folder' -
Tune the parameters of loss functions according to your dataset in
config/finetune.py, e.g.# Loss functions and their parameters. losses = { 'diam': {'scale': 'auto', 'm': 5.0, 'alpha':1.0} }In our experiments, we found that there is no necessity to manually choose "scale". But in some cases one may find it helpful to change the "scale" to a fixed value. A smaller "alpha" should be favored when the average number of samples per class is larger.
-
Run the following command in the terminal to start fine-tuning:
python src/train_sibling.py config/finetune.py
Part 3: Feature Extraction
Note: In this part, we assume you are in the directory $DOCFACE_ROOT/
To extract features using a pre-trained model (either base network or sibling network), prepare a .txt file of image list. The images should be aligned in the same way as the training dataset. Then run the following command in terminal:
python src/extract_features.py \
--model_dir /path/to/pretrained/model/dir \
--image_list /path/to/imagelist.txt \
--output /path/to/output.npy
Notice that the images in the image list follow the same naming convention of the training dataset. That is, ID images should start with "A**" and selfie images should start with "B**". An example imagelist.txt is given in the repo.
Models
-
BaseModel (unconstraind face matching): Google Drive | Baidu Yun
-
Fine-tuned DocFace model: (contact the author)
Results
-
Using our pre-trained base model, one should be able to achieve 99.67% on the standard LFW verification protocol and 99.60% on the BLUFR protocol. Similar results should be achieved by using our code to train the Face-ResNet on Ms-Celeb-1M.
-
Using the proposed Max-margin Pairwise Score loss and sibling network, DocFace acheives a significant improvement compared with Base Model on our private ID-Selfie dataset after transfer learning:
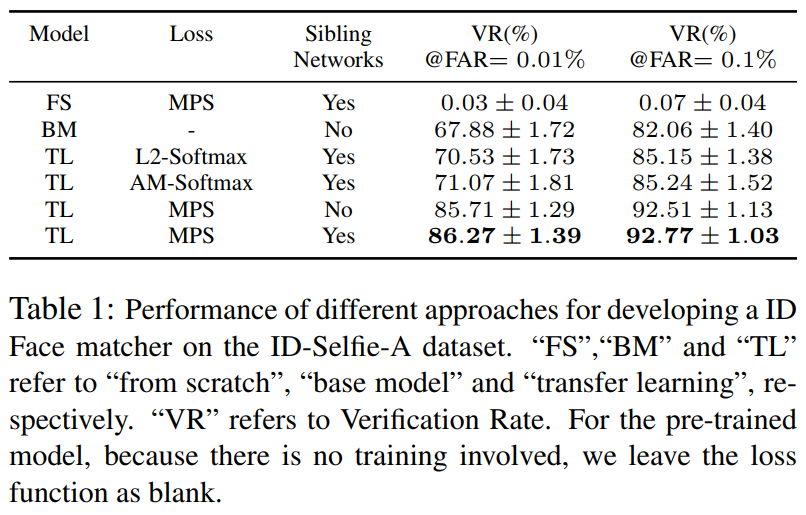
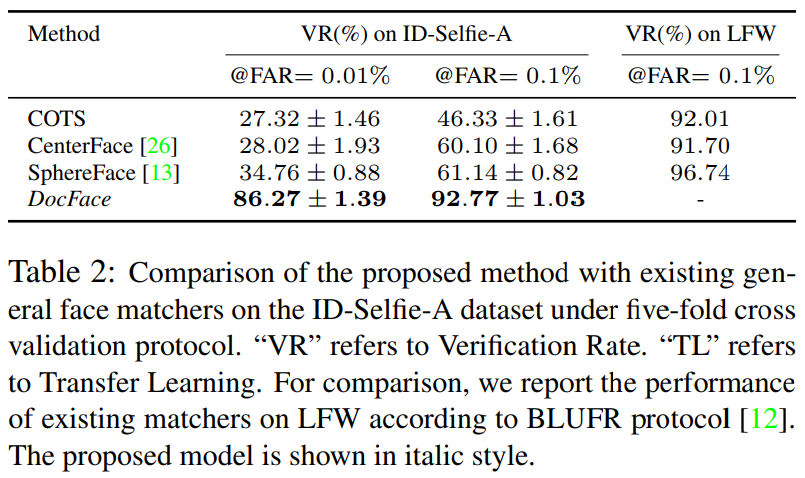
-
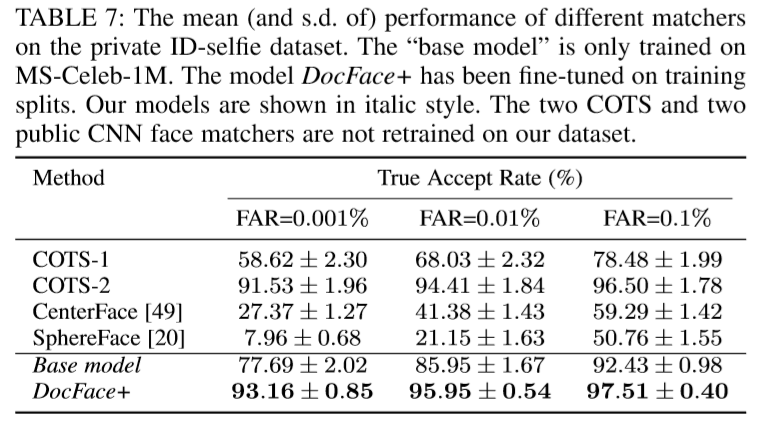
Results of DIAM-Softmax and DocFace+ on a combination of ID-Selfie-A, ID-Selifie-B and another larger dataset, most of whose classes have only two images (a pair of ID and selfie):