FedFormer: Contextual Federation with Attention in Reinforcement Learning
 This repository contains for the code for the NeurIPS 22′ pre-print FedFormer: Contextual Federation with Attention in Reinforcement Learning.
This repository contains for the code for the NeurIPS 22′ pre-print FedFormer: Contextual Federation with Attention in Reinforcement Learning.
Abstract: A core issue in federated reinforcement learning is defining how to aggregate insights from multiple agents into one. This is commonly done by taking the average of each participating agent’s model weights into one common model (FedAvg). We instead propose FedFormer, a novel federation strategy that utilizes Transformer Attention to contextually aggregate embeddings from models originating from different learner agents. In so doing, we attentively weigh contributions of other agents with respect to the current agent’s environment and learned relationships, thus providing more effective and efficient federation. We evaluate our methods on the Meta-World environment and find that our approach yields significant improvements over FedAvg and non-federated Soft Actor Critique single agent methods. Our results compared to Soft Actor Critique show that FedFormer performs better while still abiding by the privacy constraints of federated learning. In addition, we demonstrate nearly linear improvements in effectiveness with increased agent pools in certain tasks. This is contrasted by FedAvg, which fails to make noticeable improvements when scaled.

In these graphs, Soft Actor Critique (SAC) results are trained on all environments (representative of not preserving privacy) wheras FedFormer and FedAvg are trained using a set of 5 agents each with distinct subsets of environments (representative of multiple agents preserving privacy). Our results show that we match or exceed the performance of SAC and vastly outperform other federated methods such as FedAvg.
To install:
We provide conda env files at ‘environment.yml’ which contains all of our python dependencies. You can create the environment as
conda env create --prefix <env-location> -f environment.yml
in addition to MuJoCo 2.10 via mujoco-py. As part of our source code, we borrow modules from RLKit and Garage.
To run:
The main entry point to run our code is ‘main.py’. Inside that file, you can find a dict containing tunable hyperparameters such as:
variant = dict(
algorithm="FedFormer",
task=task,
overlap=False, # whether enviroments should overlap
fedFormer=True, # Whether to use FedFormer Q-Functions or not
run_name="FedFormer", # For logging purposes
version="normal",
from_saved=0, # How many encoder networks to load from saved
layer_size=400, # Hidden layer size
replay_buffer_size=int(1E6),
transformer_num_layers=2, # number of transformer encoder layers to use
num_agents=5, # number of federation agents to initialize
transformer_layer_kwargs=dict(
d_model=400, # hidden size for each transformer layer
nhead=4 # number of attention heads to initialize
),
algorithm_kwargs=dict(
num_epochs=250,
num_eval_steps_per_epoch=5000,
num_trains_per_train_loop=600,
num_expl_steps_per_train_loop=400,
min_num_steps_before_training=400,
max_path_length=500,
batch_size=1200,
),
trainer_kwargs=dict(
discount=0.99,
soft_target_tau=5e-3,
target_update_period=1,
policy_lr=3E-4,
qf_lr=3E-4,
reward_scale=1,
use_automatic_entropy_tuning=True,
),
)
Once modified, run as
python main.py --task=<task> --seed=<seed>
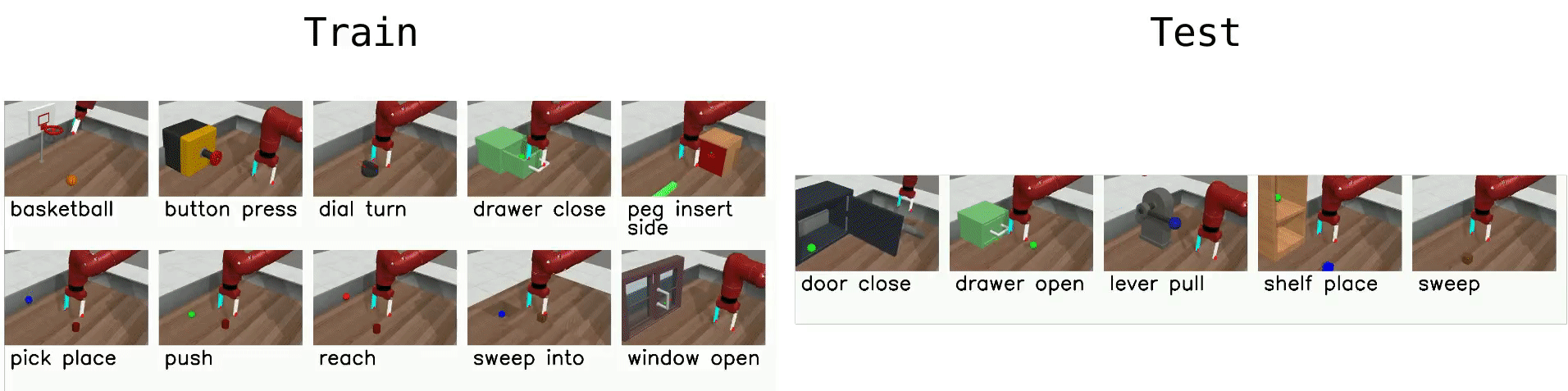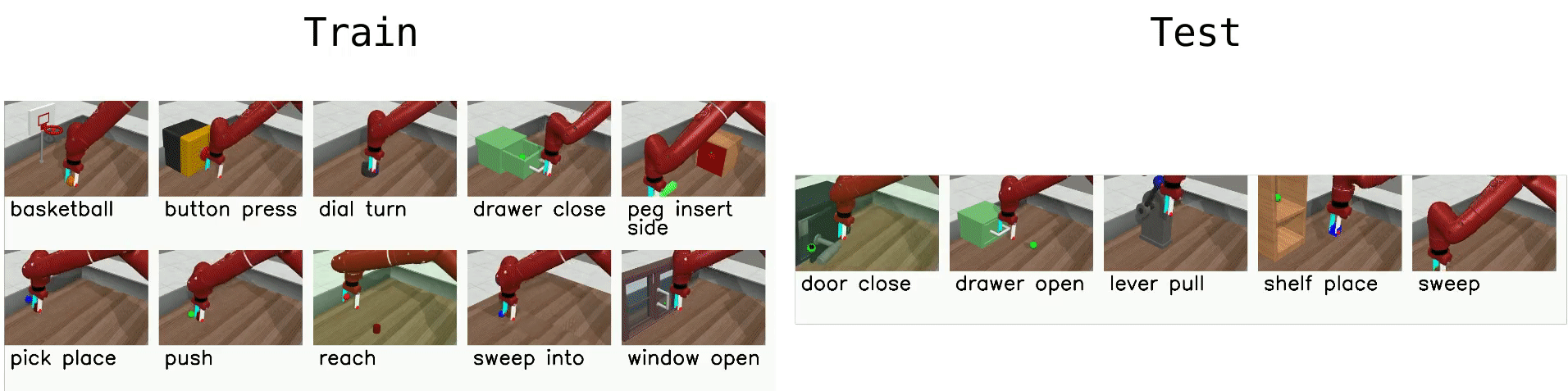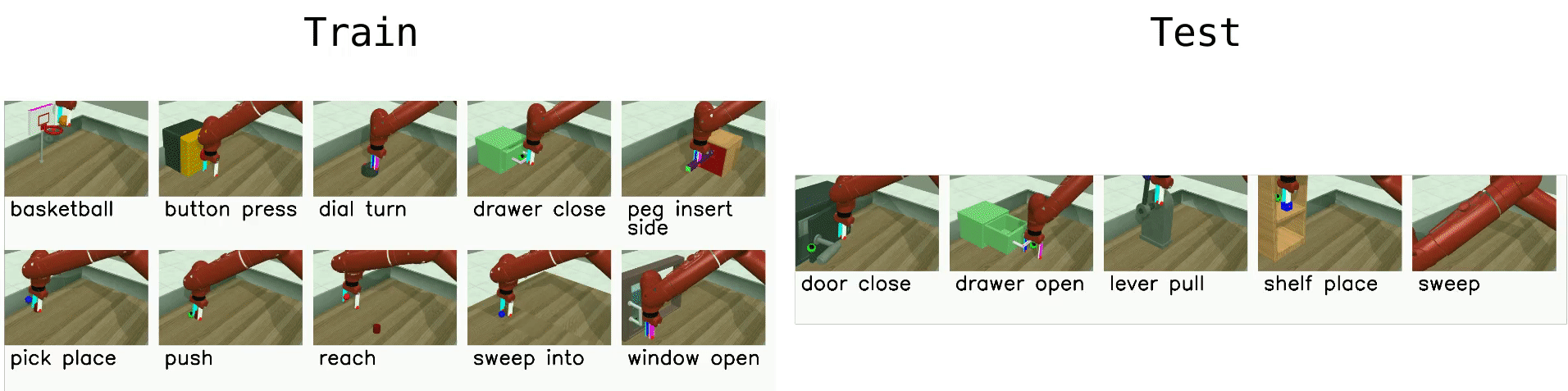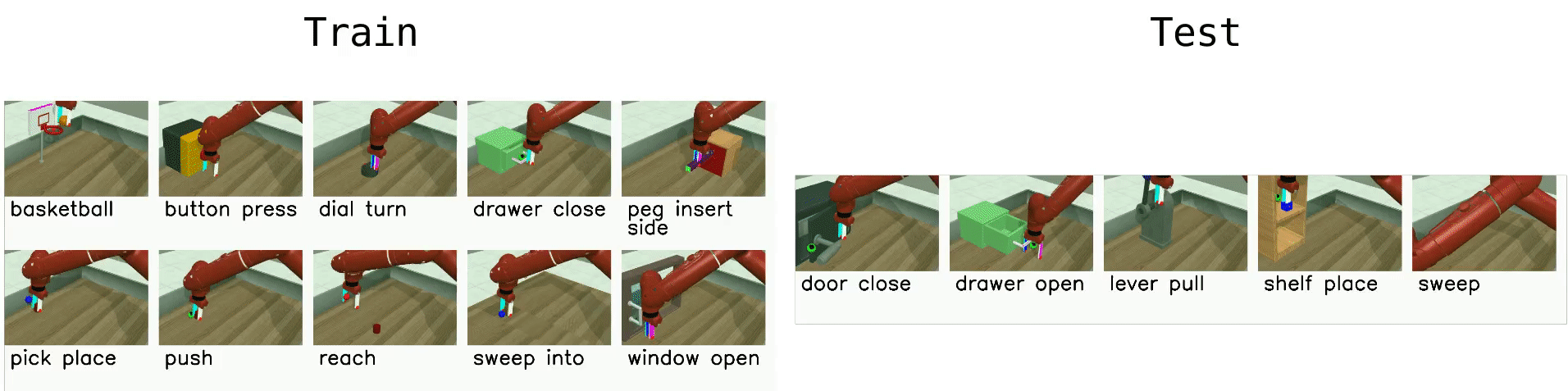
where “task” is once of the 10 MT10 MetaWorld Tasks, such as reach-v2 and window-close-v2, and “seed” is a numerical random seed to set environment distribution.
Once the experiment has finished running, all results can be seen by running
tensorboard --logdir=runs
It is important to note that the results reported in the paper are the average performance of all agents, whereas the tensorboard results will report the performance of each individual agent. That is, for Federated Methods with 5 agents, each run will generate 5 reward curves corresponding to each method.



{kind=link}