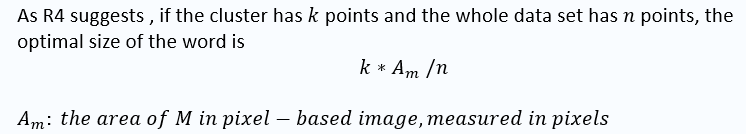使用 C++ 中的 random_device 随机数引擎生成服从正态分布的随机数据: RandomData.cpp
<div class="highlight highlight-source-c++ position-relative overflow-auto" data-snippet-clipboard-copy-content="#include
using namespace std;
//Geo Info
struct Region{
int min_x,max_x,min_y,max_y,area;
void Output(){
cout<<min_x<<" "<<max_x<<" "<<min_y<<" "<<max_y<<" "<<area<<endl; } }geo[20]; tags info struct tags{ string name; int num,sz; idx[10]; void output(){ cout<<num<<" "<<name<<" "; for(int i="1;i<=sz;i++){" cout<<idx[i]<<" cout<
>city; in>>Geo[i].min_x>>Geo[i].max_x>>Geo[i].min_y>>Geo[i].max_y>>Geo[i].area; } in.close(); /* for(int i=1;i<=17;i++){ Geo[i].Output(); } */ freopen(“TagsInfoVer2.txt”,”r”,stdin); freopen(“CityTags3.txt”,”w”,stdout); // Total Points int Count=0; //Input Tags Region vector
a; string str; stringstream ss; bool flag=false; for(int i=1;i<=60;i++){ str=””; getline(cin,str); ss.clear(); ss<
>tags[i].num; ss>>tags[i].name; while(ss){ int t; ss>>t; a.push_back(t); } a.pop_back(); tags[i].sz=a.size(); for(int j=0;j
<a.size();j++){ tags[i].idx[j+1]="a[j];" } a.clear(); count+="tags[i].num*tags[i].sz;" tags[i].output(); generate data for(int i="1;i<=60;i++){" j="1;j<=tags[i].sz;j++){" frequency int num="((double)tags[i].num/(double)Count)*10000;" cout<<num<<endl; random_device rd; mt19937_64 eng(rd()); coordinate uniform_int_distribution
distrx(Geo[tags[i].idx[j]].min_x, Geo[tags[i].idx[j]].max_x); uniform_int_distribution
distry(Geo[tags[i].idx[j]].min_y, Geo[tags[i].idx[j]].max_y); // Tags x y frequency for(int k=0;k
<num;k++){ cout<<tags[i].name<<" "<<distrx(eng)<<" "<<distry(eng)<<" "<<tags[i].idx[j]<
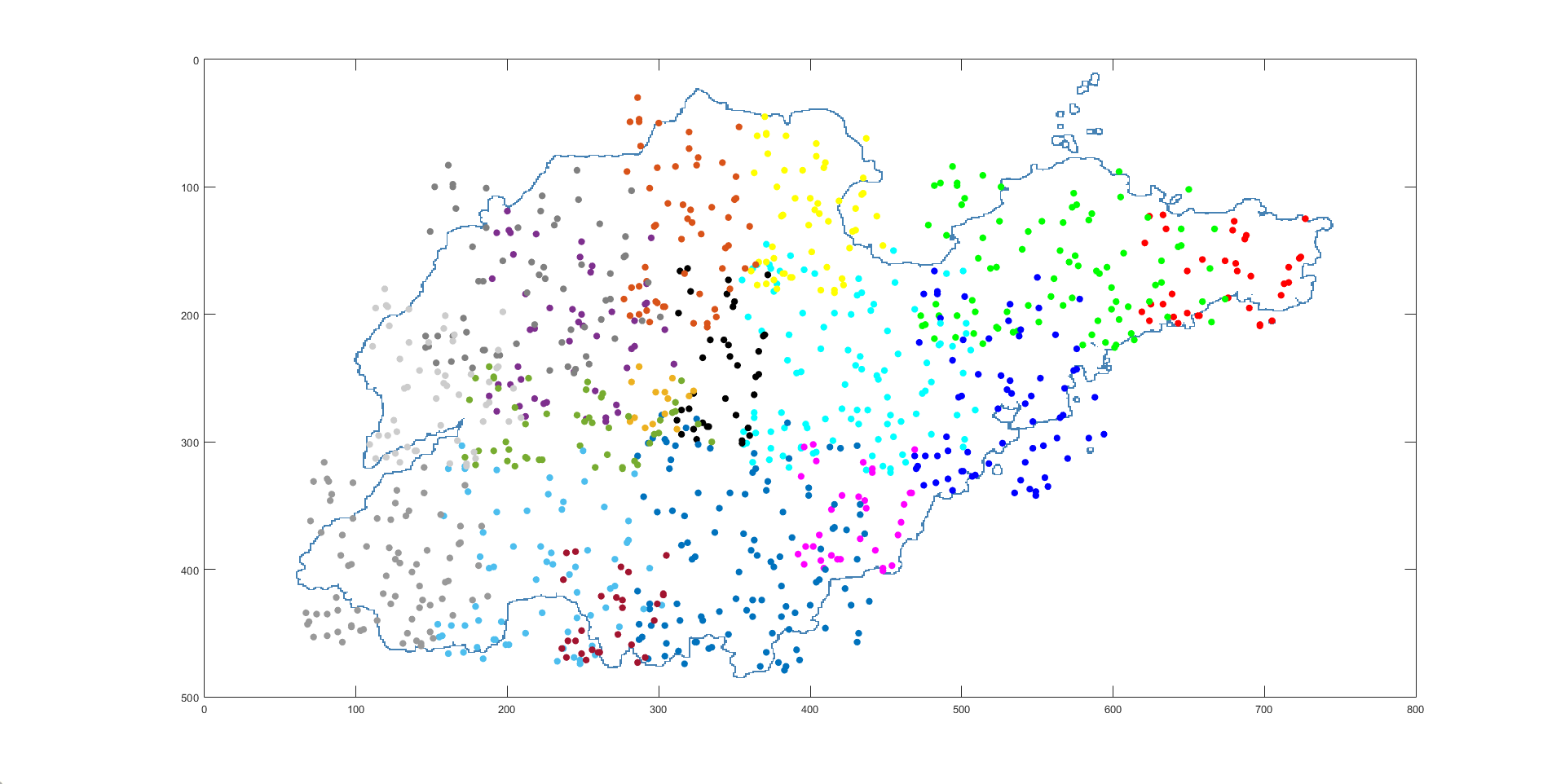
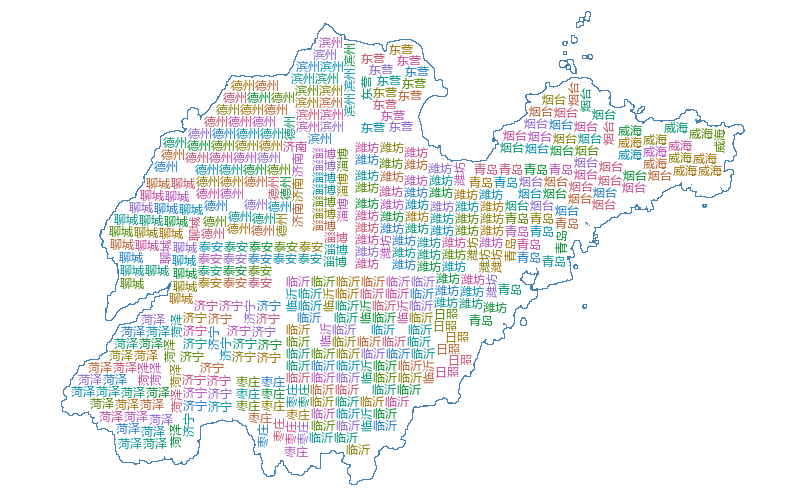
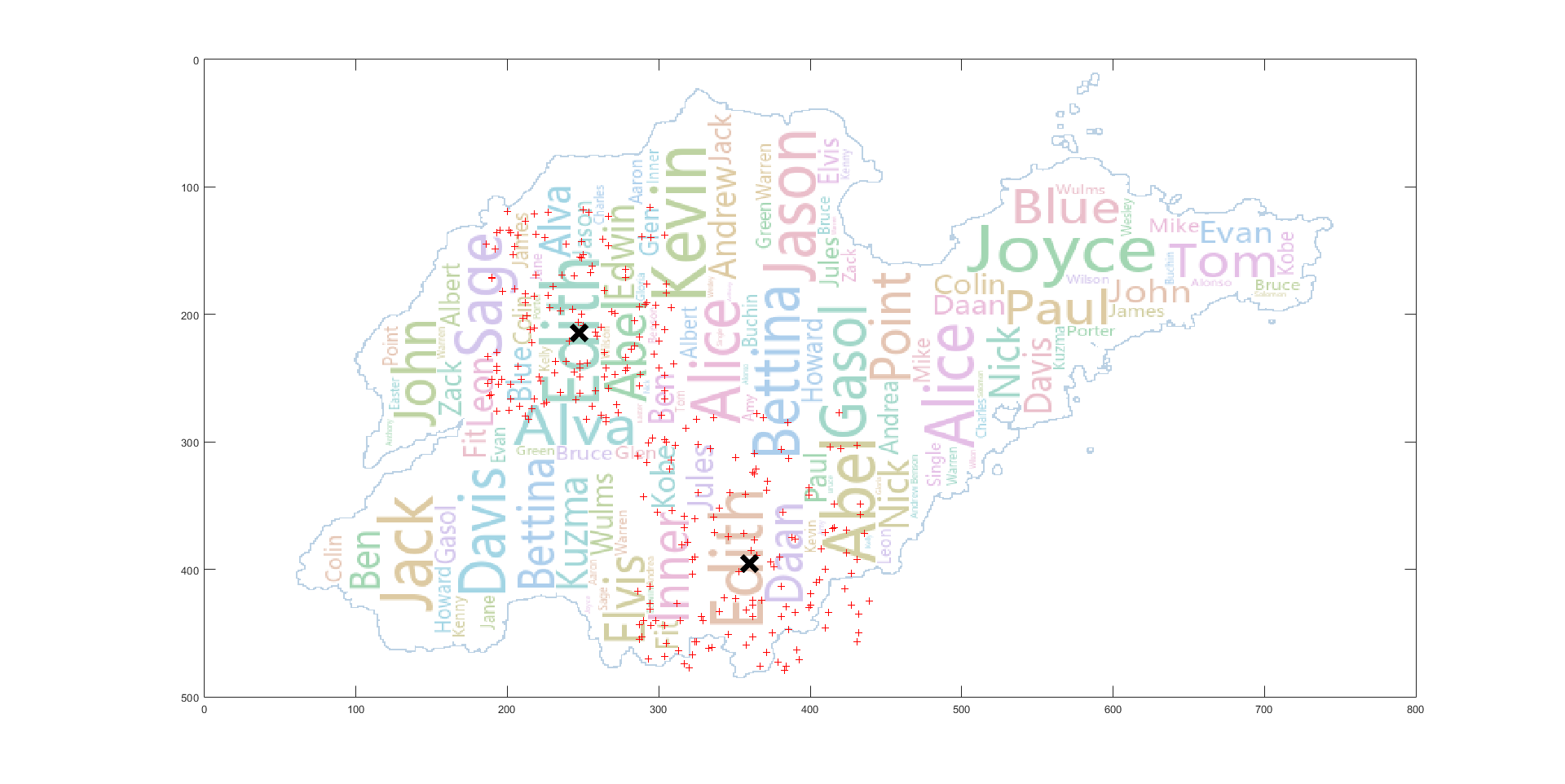
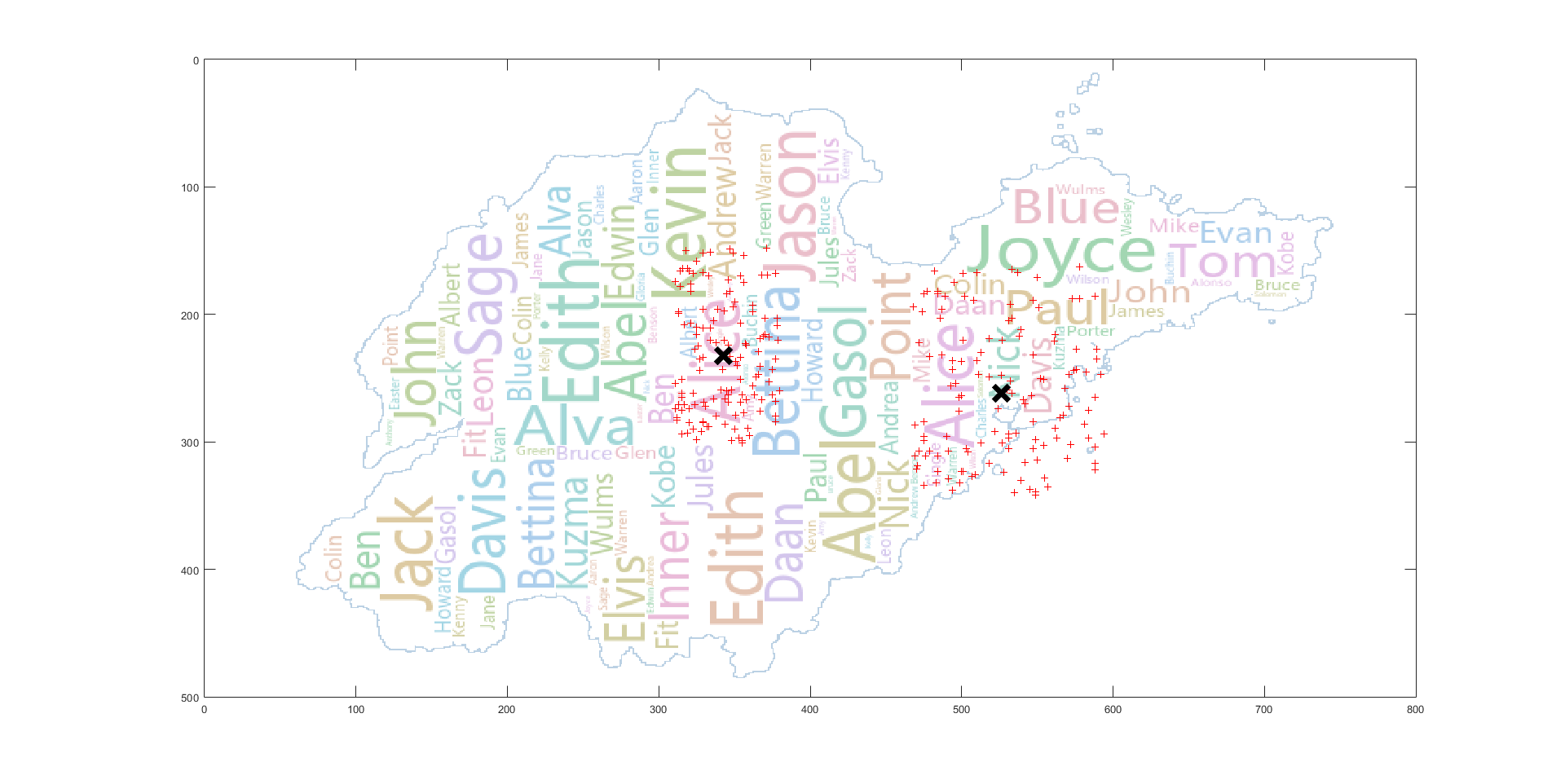
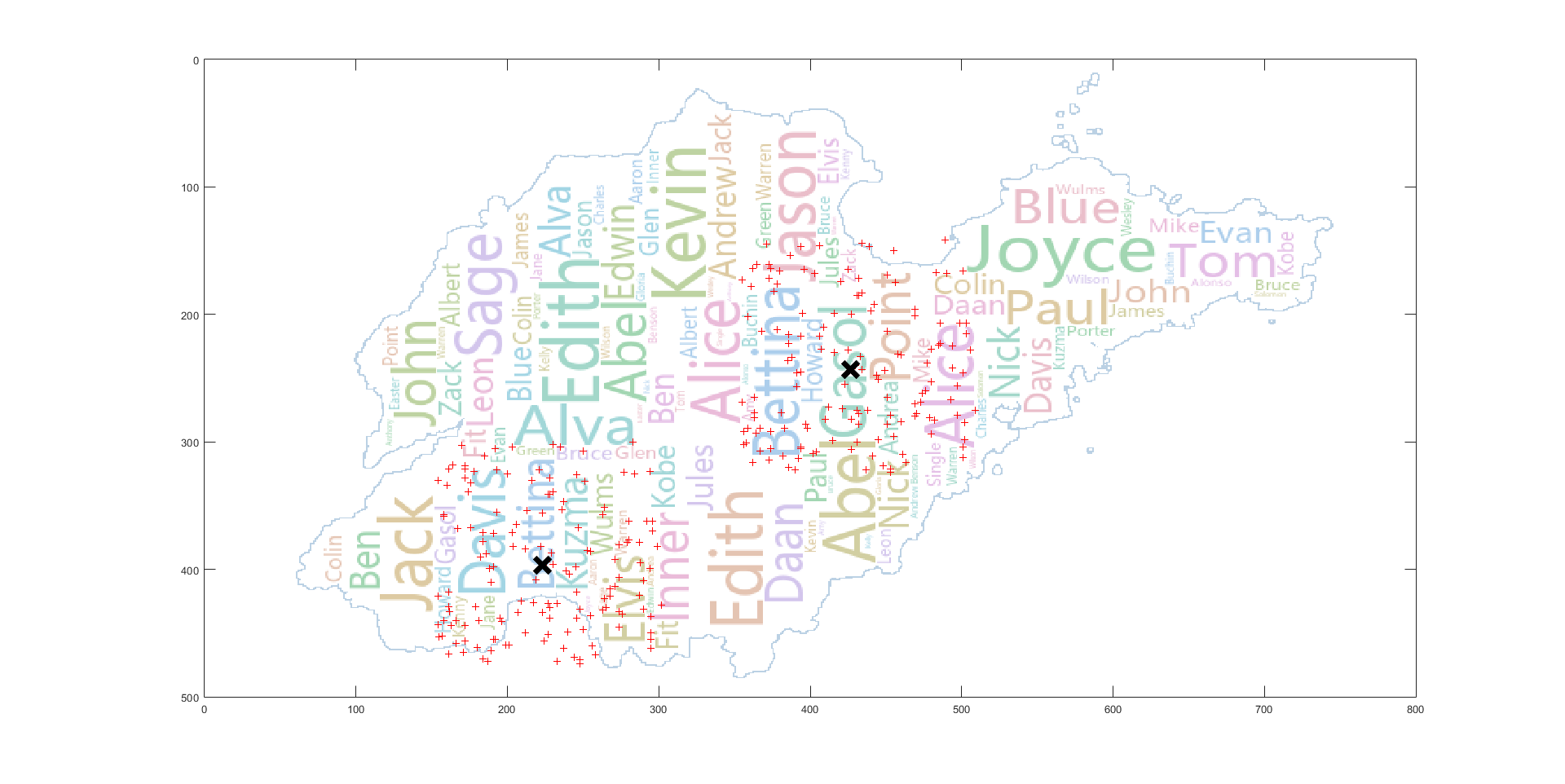
原文中只简单的提及了使用 K-means 算法对标签进行聚类,但没有具体说明实现的细节,而 K 值的选取对最后的聚类结果有着较大的影响。由于我们要在程序中对每一个标签都要执行 K-means 算法,所以,利用肘部法则,根据变化趋势选取 K 值是不可行的,或者通过不同 K 值轮廓系数的对比来选取合适的 K 值,但这样的话要对同一标签进行多次聚类后,再根据结果进行比较,时间开销偏大,这里选择的是根据地理位置进行聚类。即根据标签点所落在的区域来确定 K 值,比如某一标签落在了(威海,济南)那么我们选取 K 值为 2 即可,但节省时间的同时,这样也存在一些问题,比如某一标签落在了(济南,泰安),由于这两个区域距离很近,其实聚为一类结果可能是最佳的,现在解决这个问题的想法是:如果是做成交互式的自动可视化的应用的话,可以在绘制词云前,首先展示我们的聚类结果,然后用户可以根据聚类结果对某一标签进行调整。
K_means_Region_Cluster.m
45
Dir = [Dir;0];
else
Dir = [Dir;1];
end
sz = sum(idx==cluster);
tmpX = sort(X(idx==cluster,:));
min_x = tmpX(ceil(0.05*sz),1);
max_x = tmpX(ceil(0.95*sz),1);
min_y = tmpX(ceil(0.05*sz),2);
max_y = tmpX(ceil(0.95*sz),2);
Range = [Range;min_x,max_x,min_y,max_y];
C = [C;D(cluster,1) D(cluster,2) sz cnt];
cnt = cnt + 1;
x = [];
y = [];
Tags = [Tags;string(pre)];
end
end
x = [x A(i,1)];
y = [y A(i,2)];
Region = [Region A(i,3)];
pre=cur;
end
X = [x’ y’];
Region = unique(Region);
Rsz = size(Region);
K = Rsz(2);
[idx,D] = kmeans(X,K);
for cluster = 1:K
CurCluster = [X(idx==cluster,1) X(idx==cluster,2)];
CurCluster_Size = size(CurCluster);
tmp = zeros(CurCluster_Size(1),1);
tmp = tmp + cnt;
cluster_points = [cluster_points;X(idx==cluster,1) X(idx==cluster,2) tmp];
direction = abs(PCA_Rotation(CurCluster’));
if direction > 45
Dir = [Dir;0];
else
Dir = [Dir;1];
end
sz = sum(idx==cluster);
Range = [Range;min(X(idx==cluster,1)),max(X(idx==cluster,1)),min(X(idx==cluster,2)),max(X(idx==cluster,2))];
C = [C;D(cluster,1) D(cluster,2) sz cnt];
cnt = cnt + 1;
x = [];
y = [];
Tags = [Tags;string(cur)];
end
Map = [];
GeoSize = size(Geo);
InfoSize = size(C);
for i = 1:InfoSize(1)
for j = 1:GeoSize(1)
cx = C(i,1);
cy = C(i,2);
if cx >= Geo(j,1) && cx = Geo(j,3) && cy
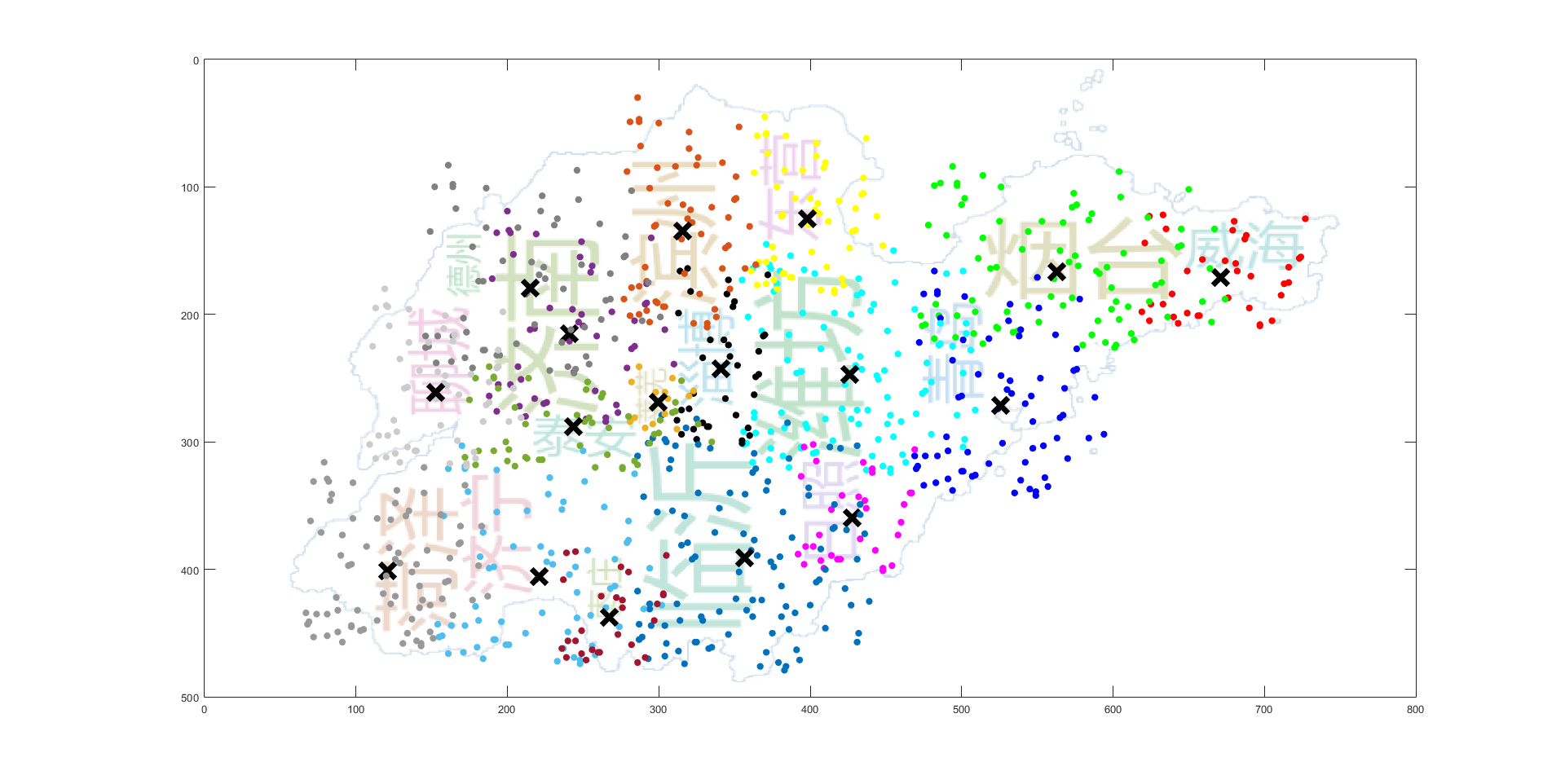
PCA 确定聚类主方向 论文中 Placement Algorithm 的第三步需要确定单词的初始方向,方法如下所示 这里采用PCA算法来确定聚类的主方向: 参考 对协方差矩阵进行特征分解,按照特征值从大到小的顺序,有特征矩阵 V,其每一行对应一个特征向量,解方程 V * T = (1 0)’ 向量 T 经过 V 的投影之后,在主方向上为 1,在垂直主方向上为 0。故 T 即指示了主方向。
# the number of the cluster
CountWord = que.qsize()
”’
#users can diy the fill word to complete the shape of the map
if que.qsize() < self.max_words:
for i in range(0, self.max_words – que.qsize(), 1):
# users can diy fill words
que.put(WordCluster('fill', self.width//2, self.height//2, (int)(min_freq * 0.5) , 1))
'''
frequencies = list()
if self.random_state is not None:
random_state = self.random_state
else:
random_state = Random()
# set the mask
if self.mask is not None:
boolean_mask = self._get_bolean_mask(self.mask)
width = self.mask.shape[1]
height = self.mask.shape[0]
else:
boolean_mask = None
height, width = self.height, self.width
# create image
img_grey = Image.new(" l", (width, height)) draw="ImageDraw.Draw(img_grey)" img_array="np.asarray(img_grey)" font_sizes, positions, orientations, colors="[]," [], [] last_freq="1." if max_font_size is none: # not provided use default font_size curidx="0" start drawing grey image while que.empty(): curword="que.get()" freq="curword.num" word="curword.word" curregion="curword.region" the cluster center center_x="(int)(curword.x)" center_y="(int)(curword.y)" range min_x="(int)(curword.min_x)" max_x="(int)(curword.max_x)" min_y="(int)(curword.min_y)" max_y="(int)(curword.max_y)" select font size rs="self.relative_scaling" !="0:" * am) n).real)) rotation curword.direction="=" 1: orientation="None" else: tried_other_orientation="False" #origin_orientation="orientation" true: try to find a position font_size) transpose optionally transposed_font="ImageFont.TransposedFont(" font, get of resulting text box_size="draw.textsize(word," possible places using integral image: '''
defGeoGenerate(self, words, A , Am ,geomap, cluster_points, PointsNum, max_font_size=None):
''' :param words: Preprocessed data sets :param A: the area of the rectangle bounding region M :param Am: the area of M in pixel :param geomap : the region coordinate :param cluster_points : the points that labeled with the cluster index :param max_font_size: Max Font Size :return: Geo Word Cloud '''# Coverage errorMeasure1=0.0# Words not representMeasure2=0.0# difference between M and M'Measure3=0.0MM=np.zeros((800,500))
# the total frequencyn=0que=Q.PriorityQueue()
min_freq=999999999foriinrange(0, words.shape[0], 1):
que.put(WordCluster(words[i][0], words[i][1], words[i][2], words[i][3], words[i][4], words[i][5],words[i][6],words[i][7],words[i][8],words[i][9], i+1))
n=n+words[i][3]
ifmin_freq>words[i][3]:
min_freq=words[i][3]
# the number of the clusterCountWord=que.qsize()
''' #users can diy the fill word to complete the shape of the map if que.qsize() < self.max_words: for i in range(0, self.max_words - que.qsize(), 1): # users can diy fill words que.put(WordCluster('fill', self.width//2, self.height//2, (int)(min_freq * 0.5) , 1)) '''frequencies=list()
ifself.random_stateisnotNone:
random_state=self.random_stateelse:
random_state=Random()
# set the maskifself.maskisnotNone:
boolean_mask=self._get_bolean_mask(self.mask)
width=self.mask.shape[1]
height=self.mask.shape[0]
else:
boolean_mask=Noneheight, width=self.height, self.widthoccupancy=IntegralOccupancyMap(height, width, boolean_mask)
# create imageimg_grey=Image.new("L", (width, height))
draw=ImageDraw.Draw(img_grey)
img_array=np.asarray(img_grey)
font_sizes, positions, orientations, colors= [], [], [], []
last_freq=1.ifmax_font_sizeisNone:
# if not provided use default font_sizemax_font_size=self.max_font_sizecuridx=0# start drawing grey imagewhilenotque.empty():
curword=que.get()
freq=curword.numword=curword.wordCurRegion=curword.region# the cluster centercenter_x= (int)(curword.x)
center_y= (int)(curword.y)
# the cluster rangemin_x= (int)(curword.min_x)
max_x= (int)(curword.max_x)
min_y= (int)(curword.min_y)
max_y= (int)(curword.max_y)
# select the font sizers=self.relative_scalingifrs!=0:
font_size=int((cmath.sqrt((freq*Am)/n).real))
# select the rotationifcurword.direction==1:
orientation=Noneelse:
orientation=Image.ROTATE_90tried_other_orientation=False#Origin_orientation = orientationwhileTrue:
# try to find a positionfont=ImageFont.truetype(self.font_path, font_size)
# transpose font optionallytransposed_font=ImageFont.TransposedFont(
font, orientation=orientation)
# get size of resulting textbox_size=draw.textsize(word, font=transposed_font)
# find possible places using integral image:''' if freq < min_freq: result = occupancy.sample_position_v2(box_size[0] + self.margin, box_size[1] + self.margin, 1, 1,self.width ,self.height ) else: '''''' b_x = geomap[CurRegion][0] b_y = geomap[CurRegion][2] e_x = geomap[CurRegion][1] e_y = geomap[CurRegion][3] '''result=occupancy.sample_position_v2(box_size[0] +self.margin, box_size[1] +self.margin,
min_x, min_y, max_x, max_y,center_x,center_y)
ifresultisnotNoneorfont_size<self.min_font_size:
# either we found a place or font-size went too smallbreak# if we didn't find a place, make font smaller# but first try to rotateifnottried_other_orientation :
orientation= (Image.ROTATE_90iforientationisNoneelseImage.ROTATE_270)
tried_other_orientation=Truecontinue# scale the word downelse:
weight_aver=0.5penalty=9999999999.9scaling_factor=1.0# find the best placementb_x=center_x- (box_size[0] +self.margin) //2b_y=center_y- (box_size[1] +self.margin) //2fors_finnp.arange(0.05,1.00,0.05):
tmp_penalty=weight_aver* (1-s_f)
new_x= (int)(center_x-box_size[0] *s_f/2)
new_y= (int)(center_y-box_size[1] *s_f/2)
distance_error=cmath.sqrt((b_x-new_x ) * (b_x-new_x ) + (b_y-new_y) * (b_y-new_y))
tmp_penalty=tmp_penalty+ (1-weight_aver) *distance_error/cmath.sqrt(A)
iftmp_penalty<=penalty:
scaling_factor=s_fpenalty=tmp_penaltyfreq= (int)(freq*scaling_factor)
que.put(WordCluster(word, center_x, center_y , freq, curword.direction, CurRegion, min_x, max_x, min_y, max_y, curword.idx))
break# can placeifresultisnotNone:
x, y=np.array(result) +self.margin//2# actually draw the textdraw.text((y, x), word, fill="white", font=transposed_font)
tmpmeasure=Hausdorff_Distance(y,x,box_size[0] +self.margin,box_size[1] +self.margin,curword.idx,cluster_points)
tmp1, tmp2=np.array(tmpmeasure)
Measure1=Measure1+tmp1Measure2=Measure2+tmp2Fill_Map(MM, y, x,box_size[0] +self.margin, box_size[1] +self.margin)
# append attributesfrequencies.append((word, freq))
positions.append((x, y))
orientations.append(orientation)
font_sizes.append(font_size)
''' colors.append(self.color_func(word, font_size=font_size, position=(x, y), orientation=orientation, random_state=random_state, font_path=self.font_path)) '''colors.append(self.Color_Distribution(curidx))
curidx=curidx+1# print(colors)# recompute integral imageifself.maskisNone:
img_array=np.asarray(img_grey)
else:
img_array=np.asarray(img_grey) +boolean_mask# recompute bottom right# the order of the cumsum's is important for speed ?!occupancy.update(img_array, x, y)
last_freq=freq# layoutself.layout_=list(zip(frequencies, font_sizes, positions,
orientations, colors))
# Three MeasuresMeasure1= (Measure1/PointsNum).realMeasure2= (PointsNum-Measure2)/PointsNumMeasure3= (162384-len(MM[MM==1]))/162384print ("Measure1:")
print (Measure1)
print ("Measure2:")
print (Measure2)
print("Measure3:")
print(Measure3)
returnself
衡量指标
Measure 1 论文中有这么一句话,我没有理解好 ” the coverage error is measured as the total sum of distances and we divide this error by the diagonal of the map ” the diagonal of the map 指的是?直接除以对角线的长度还是? (我在实现时只除以了点的总数)
Measure 2
Measure 3
= min_x and cur_x = min_y and cur_y tmpdis:
mindis = tmpdis
for y2 in range(min_y, max_y + 1):
tmpdis1 = Euclidean_distance(cur_x, min_x, cur_y, y2).real
tmpdis2 = Euclidean_distance(cur_x, max_x, cur_y, y2).real
tmpdis = min(tmpdis1, tmpdis2)
if mindis > tmpdis:
mindis = tmpdis
dis = dis + mindis
print((dis,num))
return dis,num
def Fill_Map(MM, x, y, size_x, size_y):
for i in range(x – 1, x+size_x):
for j in range(y – 1, y+size_y):
MM[i][j] = 1
.
.
.
# After placing one word
tmpmeasure = Hausdorff_Distance(y,x,box_size[0] + self.margin,box_size[1] + self.margin,curword.idx,cluster_points)
tmp1, tmp2 = np.array(tmpmeasure)
Measure1 = Measure1 + tmp1
Measure2 = Measure2 + tmp2
Fill_Map(MM, y, x,box_size[0] + self.margin, box_size[1] + self.margin)
.
.
.
# At the end of the algorithm
Measure1 = (Measure1/PointsNum).real
Measure2 = (PointsNum – Measure2)/PointsNum
Measure3 = (162384 – len(MM[MM == 1]))/162384
“>
defEuclidean_distance(x1, x2, y1, y2):
returncmath.sqrt((x2-x1) * (x2-x1) + (y2-y1) * (y2-y1))
defHausdorff_Distance(x, y, w, h, idx, cluster_points):
sz=len(cluster_points[idx])
min_x=xmax_x=x+wmin_y=ymax_y=y+hdis=0num=0foriinrange(0, sz):
cur_x=cluster_points[idx][i][0]
cur_y=cluster_points[idx][i][1]
ifcur_x>=min_xandcur_x<=max_xandcur_y>=min_yandcur_y<=max_y:
num=num+1continuemindis=99999999forx2inrange(min_x,max_x+1):
tmpdis1=Euclidean_distance(cur_x, x2, cur_y, min_y).realtmpdis2=Euclidean_distance(cur_x, x2, cur_y, max_y).realtmpdis=min(tmpdis1, tmpdis2)
ifmindis>tmpdis:
mindis=tmpdisfory2inrange(min_y, max_y+1):
tmpdis1=Euclidean_distance(cur_x, min_x, cur_y, y2).realtmpdis2=Euclidean_distance(cur_x, max_x, cur_y, y2).realtmpdis=min(tmpdis1, tmpdis2)
ifmindis>tmpdis:
mindis=tmpdisdis=dis+mindisprint((dis,num))
returndis,numdefFill_Map(MM, x, y, size_x, size_y):
foriinrange(x-1, x+size_x):
forjinrange(y-1, y+size_y):
MM[i][j] =1
.
.
.
# After placing one wordtmpmeasure=Hausdorff_Distance(y,x,box_size[0] +self.margin,box_size[1] +self.margin,curword.idx,cluster_points)
tmp1, tmp2=np.array(tmpmeasure)
Measure1=Measure1+tmp1Measure2=Measure2+tmp2Fill_Map(MM, y, x,box_size[0] +self.margin, box_size[1] +self.margin)
.
.
.
# At the end of the algorithm Measure1= (Measure1/PointsNum).realMeasure2= (PointsNum-Measure2)/PointsNumMeasure3= (162384-len(MM[MM==1]))/162384
实验分析
数据集大小:10000 聚类后单词总数:126 与原论文中的法国数据集大小相似
Measure1: 38.479475028111644 Measure2: 0.8894705053352124 Measure3: 0.13974899004828062 Total Time(包含了加载数据、词云可视化、指标衡量计算): 47.89249 s
首先从放置算法来看,它的基础操作对象实际是每个聚类,其 best placement 的计算中放置的误差设置的也是基于聚类的中心点,而指标一的计算是基于聚类中的每一个点,计算聚类中所有点到单词矩形框的豪斯多夫距离然后加和,当数据分布较为集中时,大多数点都在矩形框内,指标一的值很小,而当数据分布距离聚类中心点“比较远”时,那么这个加和后的值是非常大的。在原有算法的基础上,要想使指标一的值减小,可以加大 K-means 的 K 值,但这会使聚类数增多,同时原本高频率的大单词可能会因此被分成几个距离较近的小单词(比如不进行聚类的极端情况),可视化的效果较差。
John was the first writer to have joined pythonawesome.com. He has since then inculcated very effective writing and reviewing culture at pythonawesome which rivals have found impossible to imitate.
Previous Post
A personal toolbox by Qsh.zh Using python
Next Post
A flexible and extensible framework for gait recognition. You can focus on designing your own models and comparing