lp-opt-tool
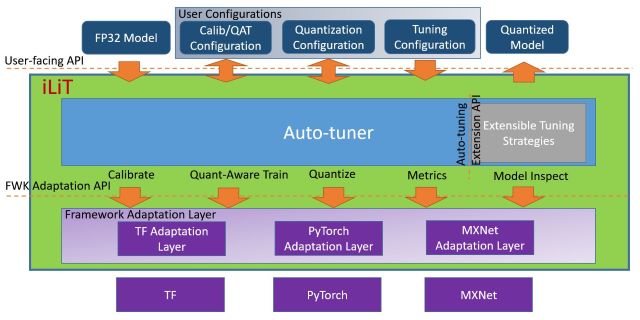
Intel® Low Precision Optimization Tool is an open-source python library which is intended to deliver a unified low-precision inference interface cross multiple Intel optimized DL frameworks on both CPU and GPU. It supports automatic accuracy-driven tuning strategies, along with additional objectives like optimizing for performance, model size and memory footprint. It also provides the easy extension capability for new backends, tuning strategies, metrics and objectives.
Documents
- Introduction explains the API of Intel® Low Precision Optimization Tool.
- Hello World demonstrates the simple steps to utilize Intel® Low Precision Optimization Tool for quanitzation, which can help you quick start with the tool.
- Tutorial provides comprehensive instructions of how to utilize diffrennt features of Intel® Low Precision Optimization Tool. In examples, there are a lot of examples to demonstrate the usage of Intel® Low Precision Optimization Tool in TensorFlow, PyTorch and MxNet for diffrent categories.
- Strategies provides comprehensive explanation on the details of how every tuning strategy works.
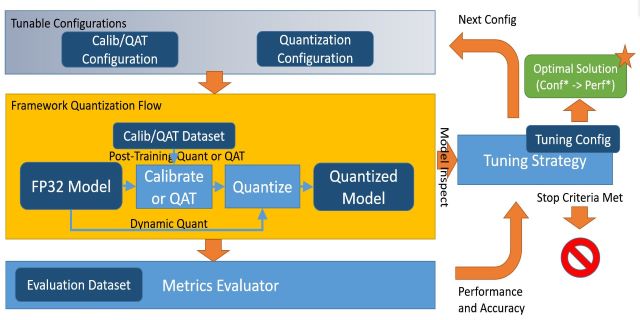
- PTQ and QAT explains how Intel® Low Precision Optimization Tool works with post-training quantization and quantization-ware training.
- Pruning on PyTorch explains how Intel® Low Precision Optimization Tool works with magnitude pruning on PyTorch.
- Tensorboard explains how Intel® Low Precision Optimization Tool helps developer to analyze tensor distribution and the impact to final accuracy during tuning process.
- Quantized Model Deployment on PyTorch explains how Intel® Low Precision Optimization Tool quantizes a FP32 PyTorch model, save and deploy quantized model through ilit utils.
- BF16 Mix-Precision on TensorFlow explains how Intel® Low Precision Optimization Tool supports INT8/BF16/FP32 mix precision model tuning on TensorFlow backend.
- Supported Model Types on TensorFlow explains the TensorFlow model types supported by Intel® Low Precision Optimization Tool.
Install from source
git clone https://github.com/intel/lp-opt-tool.git
cd lp-opt-tool
python setup.py install
Install from binary
# install from pip
pip install ilit
# install from conda
conda install ilit -c intel -c conda-forge
System Requirements
Intel® Low Precision Optimization Tool supports systems based on Intel 64 architecture or compatible processors, specially optimized for the following CPUs:
- Intel Xeon Scalable processor (formerly Skylake, Cascade Lake, and Cooper Lake)
- future Intel Xeon Scalable processor (code name Sapphire Rapids)
Intel® Low Precision Optimization Tool requires to install Intel optimized framework version for TensorFlow, PyTorch, and MXNet.
Validated Hardware/Software Environment
| Platform | OS | Python | Framework | Version |
|---|---|---|---|---|
| Cascade LakeCooper LakeSkylake | CentOS 7.8Ubuntu 18.04 | 3.63.7 | tensorflow | 2.2.0 |
| 1.15UP1 | ||||
| 2.3.0 | ||||
| 2.1.0 | ||||
| 1.15.2 | ||||
| pytorch | 1.5.0+cpu | |||
| mxnet | 1.7.0 | |||
| 1.6.0 |
Model Zoo
Intel® Low Precision Optimization Tool provides a lot of examples to show promising accuracy loss with best performance gain.
| Framework | version | model | dataset | TOP-1 Accuracy | Performance Speedup |
| --- | --- | --- | --- |
| INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio[(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
| tensorflow | 2.2.0 | resnet50v1.0 | ImageNet | 73.80% | 74.30% | -0.67% | 2.25x |
| tensorflow | resnet50v1.5 | ImageNet | 76.80% | 76.50% | 0.39% | 2.32x |
| tensorflow | resnet101 | ImageNet | 77.20% | 76.40% | 1.05% | 2.75x |
| tensorflow | inception_v1 | ImageNet | 70.10% | 69.70% | 0.57% | 1.56x |
| tensorflow | inception_v2 | ImageNet | 74.00% | 74.00% | 0.00% | 1.68x |
| tensorflow | inception_v3 | ImageNet | 77.20% | 76.70% | 0.65% | 2.05x |
| tensorflow | inception_v4 | ImageNet | 80.00% | 80.30% | -0.37% | 2.52x |
| tensorflow | inception_resnet_v2 | ImageNet | 80.20% | 80.40% | -0.25% | 1.75x |
| tensorflow | mobilenetv1 | ImageNet | 71.10% | 71.00% | 0.14% | 1.88x |
| tensorflow | ssd_resnet50_v1 | Coco | 37.72% | 38.01% | -0.76% | 2.88x |
| tensorflow | mask_rcnn_inception_v2 | Coco | 28.75% | 29.13% | -1.30% | 4.14x |
| tensorflow | wide_deep_large_ds | criteo-kaggle | 77.61% | 77.67% | -0.08% | 1.41x |
| tensorflow | vgg16 | ImageNet | 72.10% | 70.90% | 1.69% | 3.71x |
| tensorflow | vgg19 | ImageNet | 72.30% | 71.00% | 1.83% | 3.78x |
| tensorflow | resnetv2_50 | ImageNet | 70.20% | 69.60% | 0.86% | 1.52x |
| tensorflow | resnetv2_101 | ImageNet | 72.50% | 71.90% | 0.83% | 1.59x |
| tensorflow | resnetv2_152 | ImageNet | 72.70% | 72.40% | 0.41% | 1.62x |
| tensorflow | densenet121 | ImageNet | 72.60% | 72.90% | -0.41% | 1.84x |
| tensorflow | densenet161 | ImageNet | 76.10% | 76.30% | -0.26% | 1.44x |
| tensorflow | densenet169 | ImageNet | 74.40% | 74.60% | -0.27% | 1.22x |
| Framework | Version | Model | Dataset | TOP-1 Accuracy | Performance Speedup |
| --- | --- | --- | --- |
| INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio[(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
| mxnet | 1.7.0 | resnet50v1 | ImageNet | 76.03% | 76.33% | -0.39% | 3.18x |
| mxnet | inceptionv3 | ImageNet | 77.80% | 77.64% | 0.21% | 2.65x |
| mxnet | mobilenet1.0 | ImageNet | 71.72% | 72.22% | -0.69% | 2.62x |
| mxnet | mobilenetv2_1.0 | ImageNet | 70.77% | 70.87% | -0.14% | 2.89x |
| mxnet | resnet18_v1 | ImageNet | 69.99% | 70.14% | -0.21% | 3.08x |
| mxnet | squeezenet1.0 | ImageNet | 56.88% | 56.96% | -0.14% | 2.55x |
| mxnet | ssd-resnet50_v1 | VOC | 80.21% | 80.23% | -0.02% | 4.16x |
| mxnet | ssd-mobilenet1.0 | VOC | 74.94% | 75.54% | -0.79% | 3.31x |
| mxnet | resnet152_v1 | ImageNet | 78.32% | 78.54% | -0.28% | 3.16x |
Known Issues
- MSE tuning strategy doesn't work with PyTorch adaptor layer MSE tuning strategy requires to compare FP32 tensor and INT8 tensor to decide which op has impact on final quantization accuracy. PyTorch adaptor layer doesn't implement this inspect tensor interface. So if the model to tune is a PyTorch model, please do not choose MSE tuning strategy.




