KoBERT
Korean BERT pre-trained cased (KoBERT).
Training Environment
- Architecture
predefined_args = {
'attention_cell': 'multi_head',
'num_layers': 12,
'units': 768,
'hidden_size': 3072,
'max_length': 512,
'num_heads': 12,
'scaled': True,
'dropout': 0.1,
'use_residual': True,
'embed_size': 768,
'embed_dropout': 0.1,
'token_type_vocab_size': 2,
'word_embed': None,
}
- 학습셋
| 데이터 | 문장 | 단어 |
|---|---|---|
| 한국어 위키 | 5M | 54M |
| 한국어 뉴스 | 20M | 270M |
- 학습 환경
- V100 GPU x 32, Horovod(with InfiniBand)
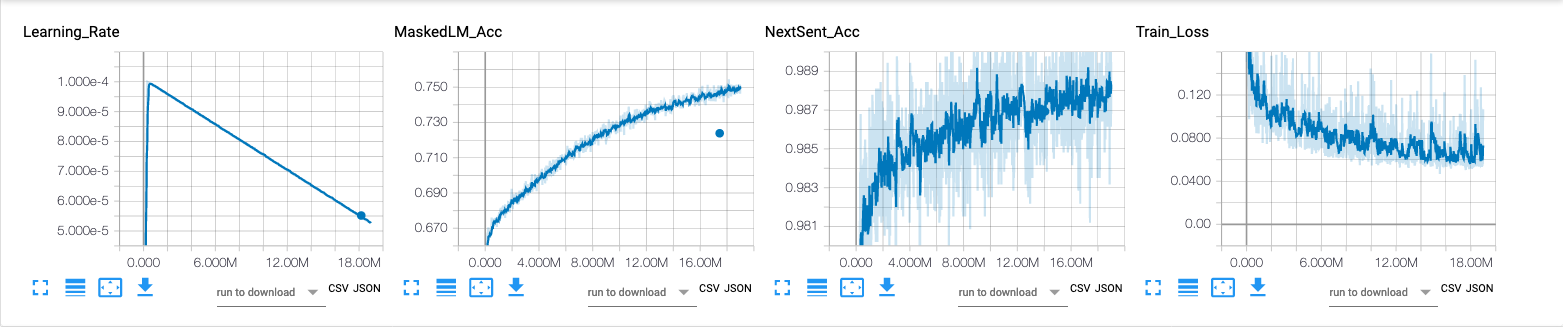
- 사전(Vocabulary)
- 크기 : 8,002
- 한글 위키 + 뉴스 텍스트 기반으로 학습한 토크나이저(SentencePiece)
- Less number of parameters(92M < 110M )
Requirements
- Python >= 3.6
- PyTorch >= 1.1.0
- pytorch_pretrained_bert >= 0.4.0
- MXNet >= 1.4.0
- gluonnlp >= 0.6.0
- sentencepiece >= 0.1.6
- onnxruntime >= 0.3.0
How to install
git clone https://github.com/SKTBrain/KoBERT.git
cd KoBERT
pip install -r requirements.txt
pip install .
Using with PyTorch
>>> import torch
>>> from kobert.pytorch_kobert import get_pytorch_kobert_model
>>> input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
>>> input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
>>> token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
>>> model, vocab = get_pytorch_kobert_model()
>>> all_encoder_layers, pooled_output = model(input_ids, token_type_ids, input_mask)
>>> pooled_output.shape
torch.Size([2, 768])
>>> vocab
Vocab(size=8002, unk="[UNK]", reserved="['[MASK]', '[SEP]', '[CLS]']")
>>> # Last Encoding Layer
>>> all_encoder_layers[-1][0]
tensor([[-0.2461, 0.2428, 0.2590, ..., -0.4861, -0.0731, 0.0756],
[-0.2478, 0.2420, 0.2552, ..., -0.4877, -0.0727, 0.0754],
[-0.2472, 0.2420, 0.2561, ..., -0.4874, -0.0733, 0.0765]],
grad_fn=<SelectBackward>)
model은 디폴트로 eval()모드로 리턴됨, 따라서 학습 용도로 사용시 model.train()명령을 통해 학습 모드로 변경할 필요가 있다.
Using with ONNX
>>> import onnxruntime
>>> import numpy as np
>>> from kobert.utils import get_onnx
>>> onnx_path = get_onnx()
>>> sess = onnxruntime.InferenceSession(onnx_path)
>>> input_ids = [[31, 51, 99], [15, 5, 0]]
>>> input_mask = [[1, 1, 1], [1, 1, 0]]
>>> token_type_ids = [[0, 0, 1], [0, 1, 0]]
>>> len_seq = len(input_ids[0])
>>> pred_onnx = sess.run(None, {'input_ids':np.array(input_ids),
>>> 'token_type_ids':np.array(token_type_ids),
>>> 'input_mask':np.array(input_mask),
>>> 'position_ids':np.array(range(len_seq))})
>>> # Last Encoding Layer
>>> pred_onnx[-2][0]
array([[-0.24610452, 0.24282141, 0.25895312, ..., -0.48613444,
-0.07305173, 0.07560554],
[-0.24783179, 0.24200465, 0.25520486, ..., -0.4877185 ,
-0.0727044 , 0.07536091],
[-0.24721591, 0.24196623, 0.2560626 , ..., -0.48743123,
-0.07326943, 0.07650235]], dtype=float32)
ONNX 컨버팅은 soeque1께서 도움을 주셨습니다.
Using with MXNet-Gluon
>>> import mxnet as mx
>>> from kobert.mxnet_kobert import get_mxnet_kobert_model
>>> input_id = mx.nd.array([[31, 51, 99], [15, 5, 0]])
>>> input_mask = mx.nd.array([[1, 1, 1], [1, 1, 0]])
>>> token_type_ids = mx.nd.array([[0, 0, 1], [0, 1, 0]])
>>> model, vocab = get_mxnet_kobert_model(use_decoder=False, use_classifier=False)
>>> encoder_layer, pooled_output = model(input_id, token_type_ids)
>>> pooled_output.shape
(2, 768)
>>> vocab
Vocab(size=8002, unk="[UNK]", reserved="['[MASK]', '[SEP]', '[CLS]']")
>>> # Last Encoding Layer
>>> encoder_layer[0]
[[-0.24610372 0.24282135 0.2589539 ... -0.48613444 -0.07305248
0.07560539]
[-0.24783105 0.242005 0.25520545 ... -0.48771808 -0.07270523
0.07536077]
[-0.24721491 0.241966 0.25606337 ... -0.48743105 -0.07327032
0.07650219]]
<NDArray 3x768 @cpu(0)>
- Naver Sentiment Analysis Fine-Tuning with MXNet
Tokenizer
- Pretrained Sentencepiece tokenizer
>>> from gluonnlp.data import SentencepieceTokenizer
>>> from kobert.utils import get_tokenizer
>>> tok_path = get_tokenizer()
>>> sp = SentencepieceTokenizer(tok_path)
>>> sp('한국어 모델을 공유합니다.')
['▁한국', '어', '▁모델', '을', '▁공유', '합니다', '.']



