pytorch-dnc
Neural Turing Machine (NTM) & Differentiable Neural Computer (DNC) with pytorch & visdom
- Sample on-line plotting while training(avg loss)/testing(write/read weights & memory)
NTM on the copy task (top 2 rows, 1st row converges to sequentially write to lower locations, 2nd row converges to sequentially write to upper locations) and
DNC on the repeat-copy task (3rd row) (the write/read weights here are after location focus so are no longer necessarily normalized within each head by design):
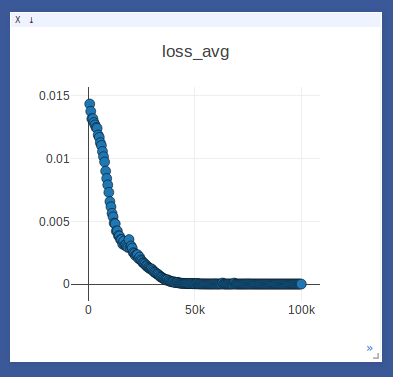
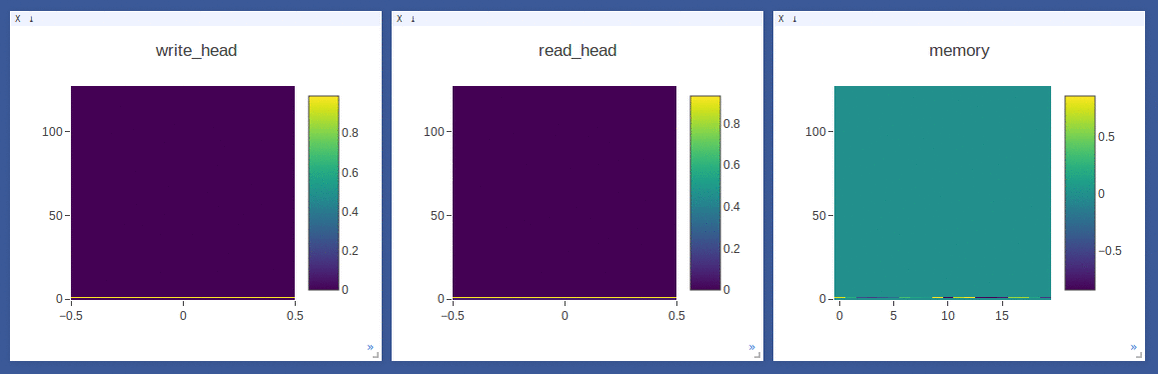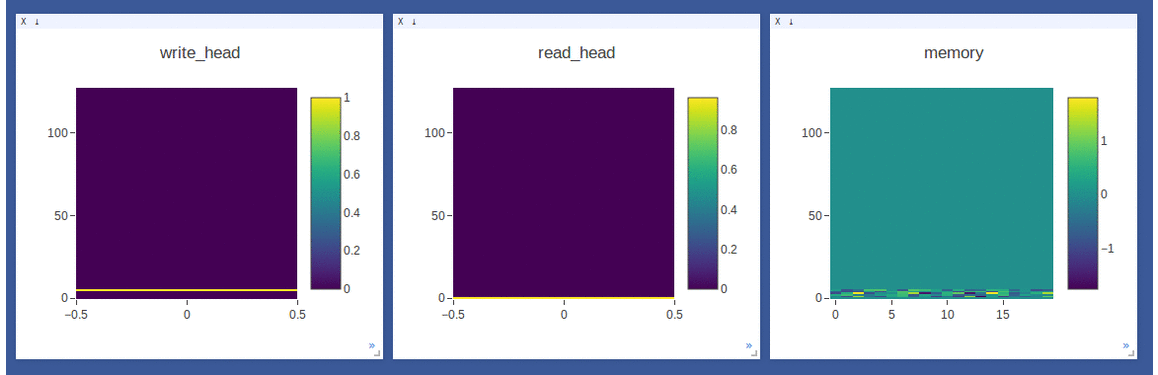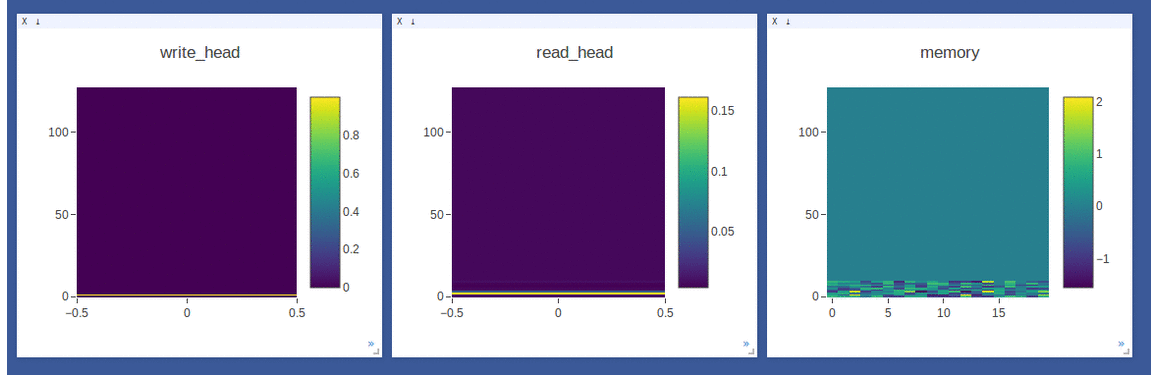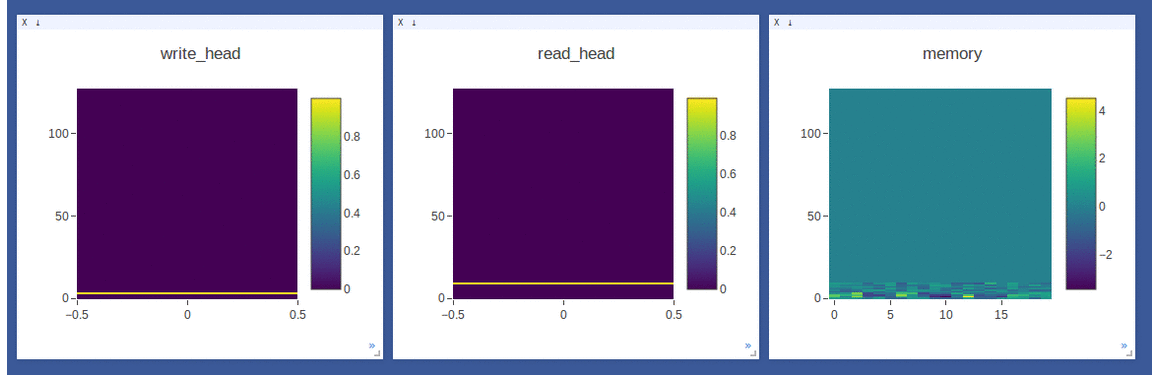
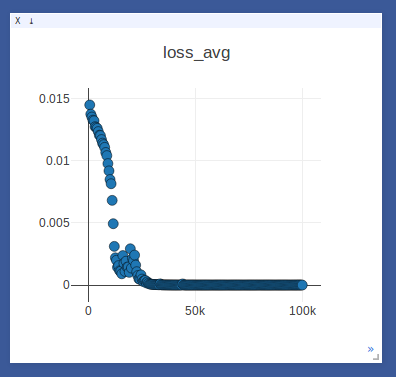
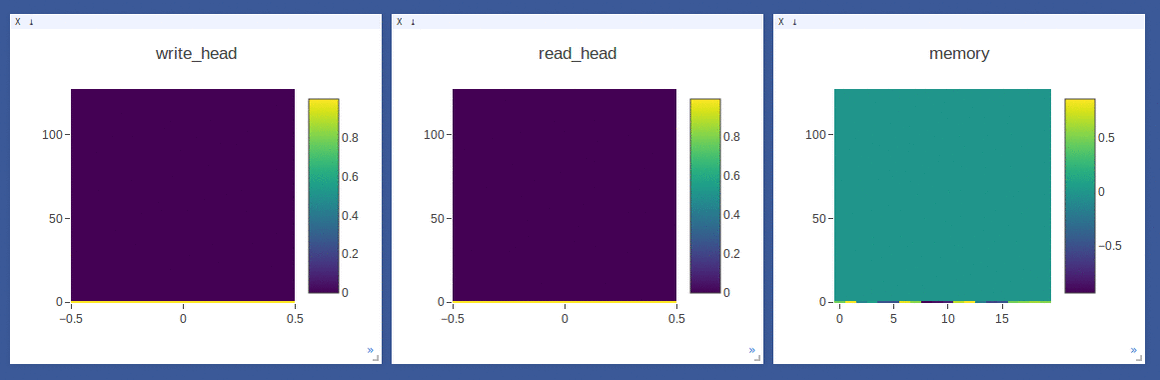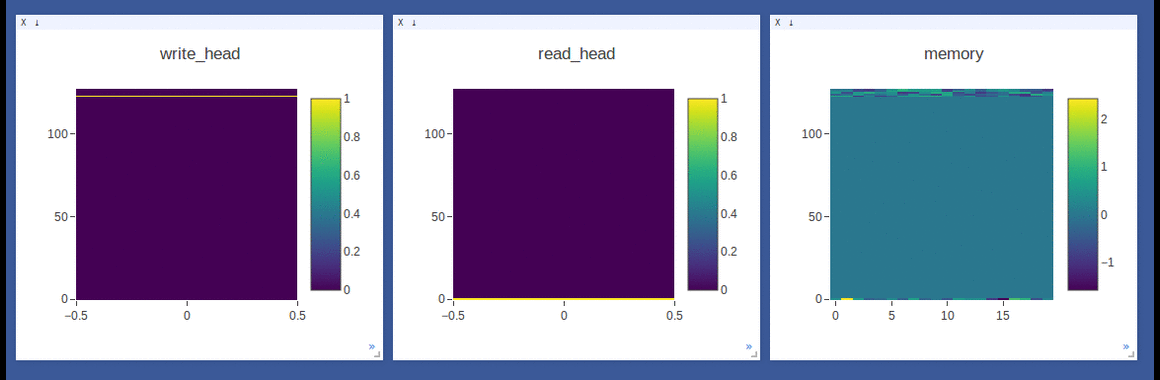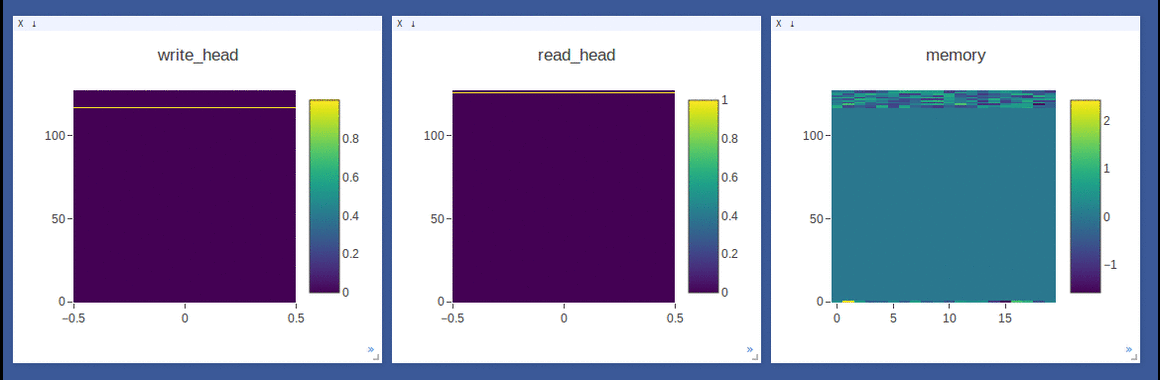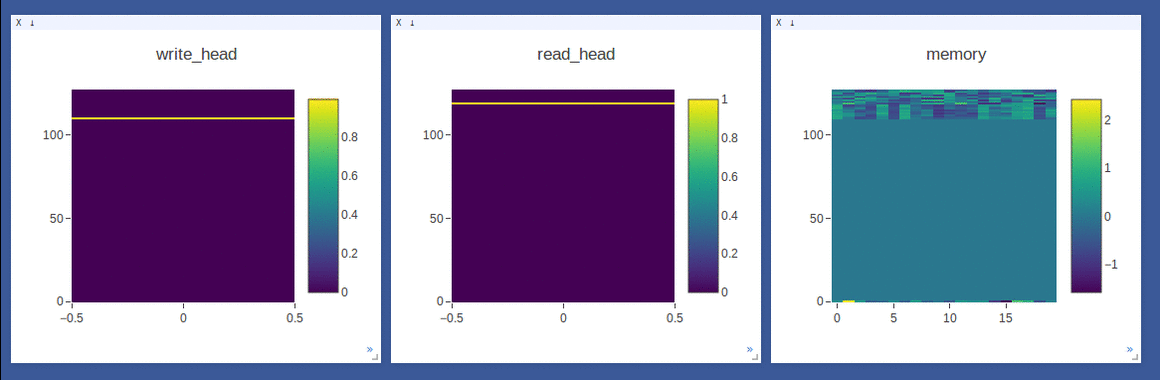
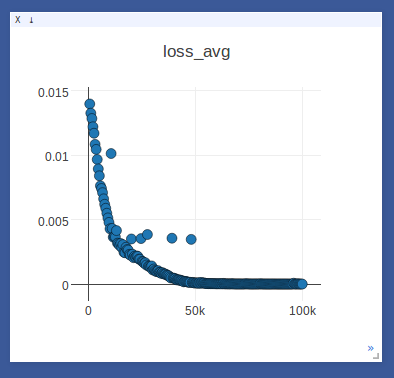
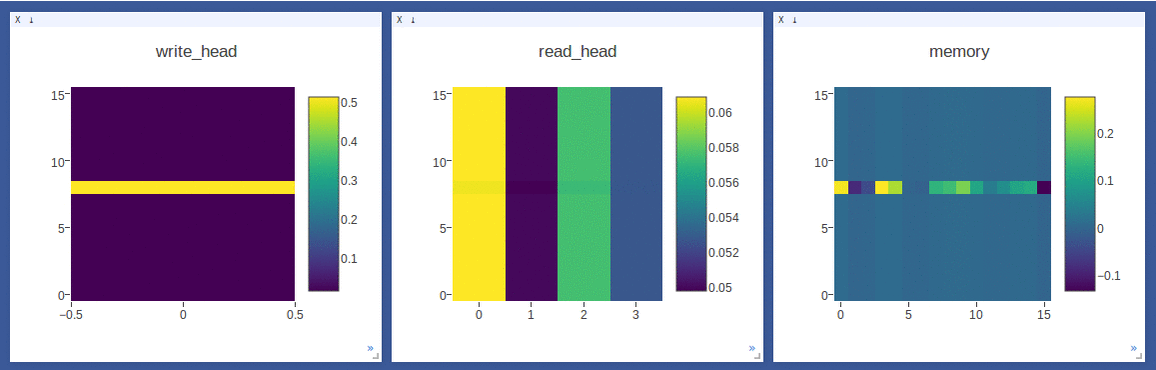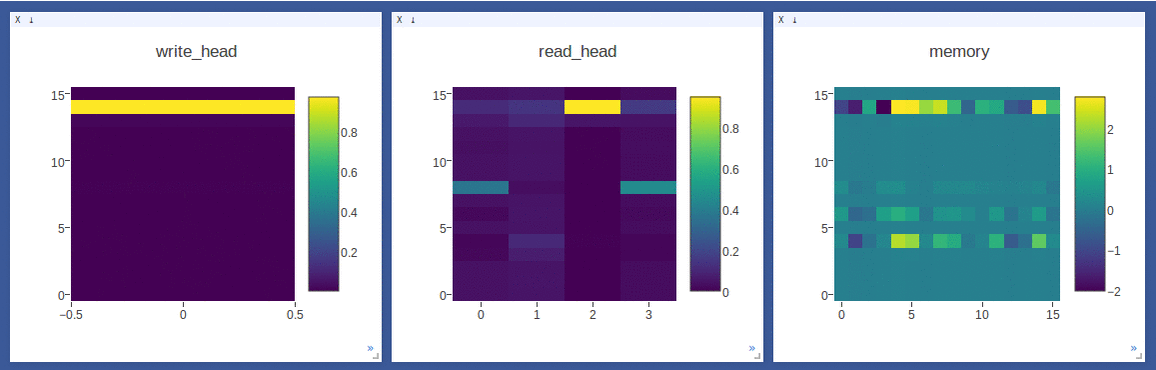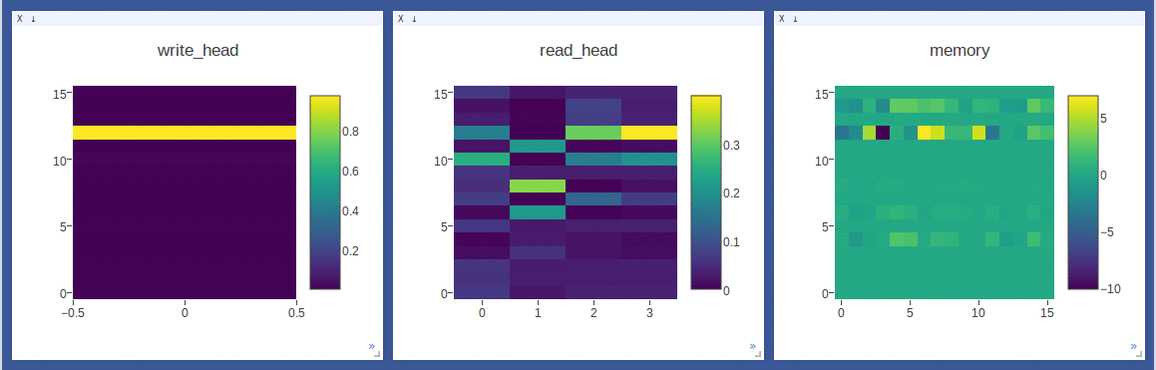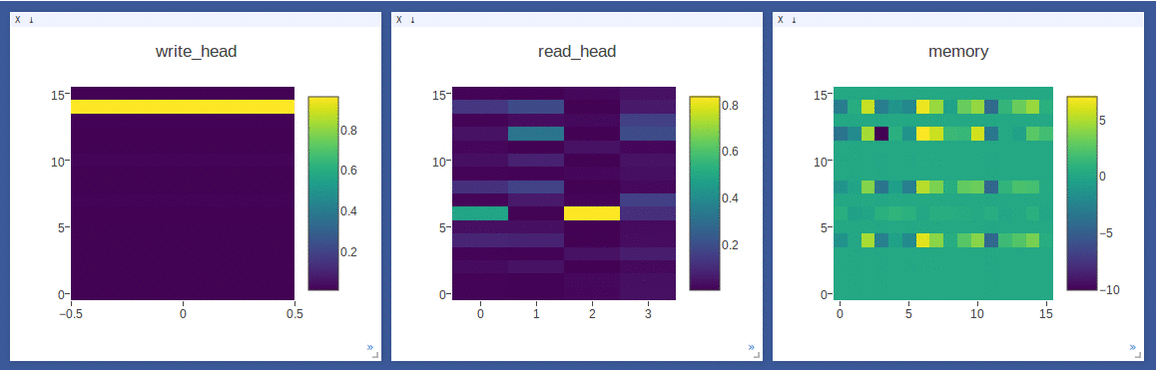
- Sample loggings while training DNC on the repeat-copy task (we use
WARNINGas the logging level currently to get rid of theINFOprintouts from visdom):
[WARNING ] (MainProcess) <===================================>
[WARNING ] (MainProcess) bash$: python -m visdom.server
[WARNING ] (MainProcess) http://localhost:8097/env/daim_17051000
[WARNING ] (MainProcess) <===================================> Agent:
[WARNING ] (MainProcess) <-----------------------------======> Env:
[WARNING ] (MainProcess) Creating {repeat-copy | } w/ Seed: 123
[WARNING ] (MainProcess) Word {length}: {4}
[WARNING ] (MainProcess) Words # {min, max}: {1, 2}
[WARNING ] (MainProcess) Repeats {min, max}: {1, 2}
[WARNING ] (MainProcess) <-----------------------------======> Circuit: {Controller, Accessor}
[WARNING ] (MainProcess) <--------------------------------===> Controller:
[WARNING ] (MainProcess) LSTMController (
(in_2_hid): LSTMCell(70, 64, bias=1)
)
[WARNING ] (MainProcess) <--------------------------------===> Accessor: {WriteHead, ReadHead, Memory}
[WARNING ] (MainProcess) <-----------------------------------> WriteHeads: {1 heads}
[WARNING ] (MainProcess) DynamicWriteHead (
(hid_2_key): Linear (64 -> 16)
(hid_2_beta): Linear (64 -> 1)
(hid_2_alloc_gate): Linear (64 -> 1)
(hid_2_write_gate): Linear (64 -> 1)
(hid_2_erase): Linear (64 -> 16)
(hid_2_add): Linear (64 -> 16)
)
[WARNING ] (MainProcess) <-----------------------------------> ReadHeads: {4 heads}
[WARNING ] (MainProcess) DynamicReadHead (
(hid_2_key): Linear (64 -> 64)
(hid_2_beta): Linear (64 -> 4)
(hid_2_free_gate): Linear (64 -> 4)
(hid_2_read_mode): Linear (64 -> 12)
)
[WARNING ] (MainProcess) <-----------------------------------> Memory: {16(batch_size) x 16(mem_hei) x 16(mem_wid)}
[WARNING ] (MainProcess) <-----------------------------======> Circuit: {Overall Architecture}
[WARNING ] (MainProcess) DNCCircuit (
(controller): LSTMController (
(in_2_hid): LSTMCell(70, 64, bias=1)
)
(accessor): DynamicAccessor (
(write_heads): DynamicWriteHead (
(hid_2_key): Linear (64 -> 16)
(hid_2_beta): Linear (64 -> 1)
(hid_2_alloc_gate): Linear (64 -> 1)
(hid_2_write_gate): Linear (64 -> 1)
(hid_2_erase): Linear (64 -> 16)
(hid_2_add): Linear (64 -> 16)
)
(read_heads): DynamicReadHead (
(hid_2_key): Linear (64 -> 64)
(hid_2_beta): Linear (64 -> 4)
(hid_2_free_gate): Linear (64 -> 4)
(hid_2_read_mode): Linear (64 -> 12)
)
)
(hid_to_out): Linear (128 -> 5)
)
[WARNING ] (MainProcess) No Pretrained Model. Will Train From Scratch.
[WARNING ] (MainProcess) <===================================> Training ...
[WARNING ] (MainProcess) Reporting @ Step: 500 | Elapsed Time: 30.609361887
[WARNING ] (MainProcess) Training Stats: avg_loss: 0.014866309287
[WARNING ] (MainProcess) Evaluating @ Step: 500
[WARNING ] (MainProcess) Evaluation Took: 1.6457400322
[WARNING ] (MainProcess) Iteration: 500; loss_avg: 0.0140423600748
[WARNING ] (MainProcess) Saving Model @ Step: 500: /home/zhang/ws/17_ws/pytorch-dnc/models/daim_17051000.pth ...
[WARNING ] (MainProcess) Saved Model @ Step: 500: /home/zhang/ws/17_ws/pytorch-dnc/models/daim_17051000.pth.
[WARNING ] (MainProcess) Resume Training @ Step: 500
...
What is included?
This repo currently contains the following algorithms:
Tasks:
- copy
- repeat-copy
Code structure & Naming conventions
NOTE: we follow the exact code structure as pytorch-rl so as to make the code easily transplantable.
./utils/factory.py
We suggest the users refer to
./utils/factory.py,
where we list all the integratedEnv,Circuit,AgentintoDict's.
All of the core classes are implemented in./core/.
The factory pattern in./utils/factory.pymakes the code super clean,
as no matter what type ofCircuityou want to train,
or which type ofEnvyou want to train on,
all you need to do is to simply modify some parameters in./utils/options.py,
then the./main.pywill do it all (NOTE: this./main.pyfile never needs to be modified).
- namings
To make the code more clean and readable, we name the variables using the following pattern:
*_vb:torch.autograd.Variable's or a list of such objects*_ts:torch.Tensor's or a list of such objects- otherwise: normal python datatypes
Dependencies
- Python 2.7
- PyTorch >=v0.2.0
- Visdom
How to run:
You only need to modify some parameters in ./utils/options.py to train a new configuration.
- Configure your training in
./utils/options.py:
line 12: add an entry intoCONFIGSto define your training (agent_type,env_type,game,circuit_type)line 28: choose the entry you just addedline 24-25: fill in your machine/cluster ID (MACHINE) and timestamp (TIMESTAMP) to define your training signature (MACHINE_TIMESTAMP),
the corresponding model file and the log file of this training will be saved under this signature (./models/MACHINE_TIMESTAMP.pth&./logs/MACHINE_TIMESTAMP.logrespectively).
Also the visdom visualization will be displayed under this signature (first activate the visdom server by type in bash:python -m visdom.server &, then open this address in your browser:http://localhost:8097/env/MACHINE_TIMESTAMP)line 28: to train a model, setmode=1(training visualization will be underhttp://localhost:8097/env/MACHINE_TIMESTAMP); to test the model of this current training, all you need to do is to setmode=2(testing visualization will be underhttp://localhost:8097/env/MACHINE_TIMESTAMP_test).
- Run:
python main.py
Implementation Notes:
The difference between NTM & DNC is stated as follows in the
DNC[2] paper:
Comparison with the neural Turing machine. The neural Turing machine (NTM) was
the predecessor to the DNC described in this work. It used a similar
architecture of neural network controller with read–write access to a memory
matrix, but differed in the access mechanism used to interface with the memory.
In the NTM, content-based addressing was combined with location-based addressing
to allow the network to iterate through memory locations in order of their
indices (for example, location n followed by n+1 and so on). This allowed the
network to store and retrieve temporal sequences in contiguous blocks of memory.
However, there were several drawbacks. First, the NTM has no mechanism to ensure
that blocks of allocated memory do not overlap and interfere—a basic problem of
computer memory management. Interference is not an issue for the dynamic memory
allocation used by DNCs, which provides single free locations at a time,
irrespective of index, and therefore does not require contiguous blocks. Second,
the NTM has no way of freeing locations that have already been written to and,
hence, no way of reusing memory when processing long sequences. This problem is
addressed in DNCs by the free gates used for de-allocation. Third, sequential
information is preserved only as long as the NTM continues to iterate through
consecutive locations; as soon as the write head jumps to a different part of
the memory (using content-based addressing) the order of writes before and after
the jump cannot be recovered by the read head. The temporal link matrix used by
DNCs does not suffer from this problem because it tracks the order in which
writes were made.
We thus make some effort to put those two together in a combined codebase.
The classes implemented have the following hierarchy:
- Agent
- Env
- Circuit
- Controller
- Accessor
- WriteHead
- ReadHead
- Memory
The part where NTM & DNC differs is the Accessor, where in the
code NTM uses the StaticAccessor(may not be an appropriate name but
we use this to make the code more consistent) and DNC uses the
DynamicAccessor. Both Accessor classes use _content_focus()
and _location_focus()(may not be an appropriate name for DNC but we
use this to make the code more consistent). The _content_focus() is the
same for both classes, but the _location_focus() for DNC is much
more complicated as it uses dynamic allocation additionally for write and
temporal link additionally for read. Those focus (or attention) mechanisms
are implemented in Head classes, and those focuses output a weight
vector for each head (write/read). Those weight vectors are then used in
_access() to interact with the external memory.
A side note:
The sturcture for Env might look strange as this class was originally
designed for reinforcement learning settings as in
pytorch-rl; here we use it for
providing datasets for supervised learning, so the reward,
action and terminal are always left blank in this repo.
Repos we referred to during the development of this repo:
- deepmind/dnc
- ypxie/pytorch-NeuCom
- bzcheeseman/pytorch-EMM
- DoctorTeeth/diffmem
- kaishengtai/torch-ntm
- Mostafa-Samir/DNC-tensorflow
The following paper might be interesting to take a look:)
Neural SLAM: We present an approach for agents to learn representations of a global map from sensor data, to aid their exploration in new environments. To achieve this, we embed procedures mimicking that of traditional Simultaneous Localization and Mapping (SLAM) into the soft attention based addressing of external memory architectures, in which the external memory acts as an internal representation of the environment. This structure encourages the evolution of SLAM-like behaviors inside a completely differentiable deep neural network. We show that this approach can help reinforcement learning agents to successfully explore new environments where long-term memory is essential. We validate our approach in both challenging grid-world environments and preliminary Gazebo experiments. A video of our experiments can be found at: \url{https://goo.gl/RfiSxo}.
@article{zhang2017neural,
title={Neural SLAM},
author={Zhang, Jingwei and Tai, Lei and Boedecker, Joschka and Burgard, Wolfram and Liu, Ming},
journal={arXiv preprint arXiv:1706.09520},
year={2017}
}
Citation
If you find this library useful and would like to cite it, the following would be appropriate:
@misc{pytorch-dnc,
author = {Zhang, Jingwei},
title = {jingweiz/pytorch-dnc},
url = {https://github.com/jingweiz/pytorch-dnc},
year = {2017}
}






