ViT_OOD_generalization
This repository contains PyTorch evaluation code for Delving Deep into the Generalization of Vision Transformers under Distribution Shifts.
A Quick Glance of Our Work
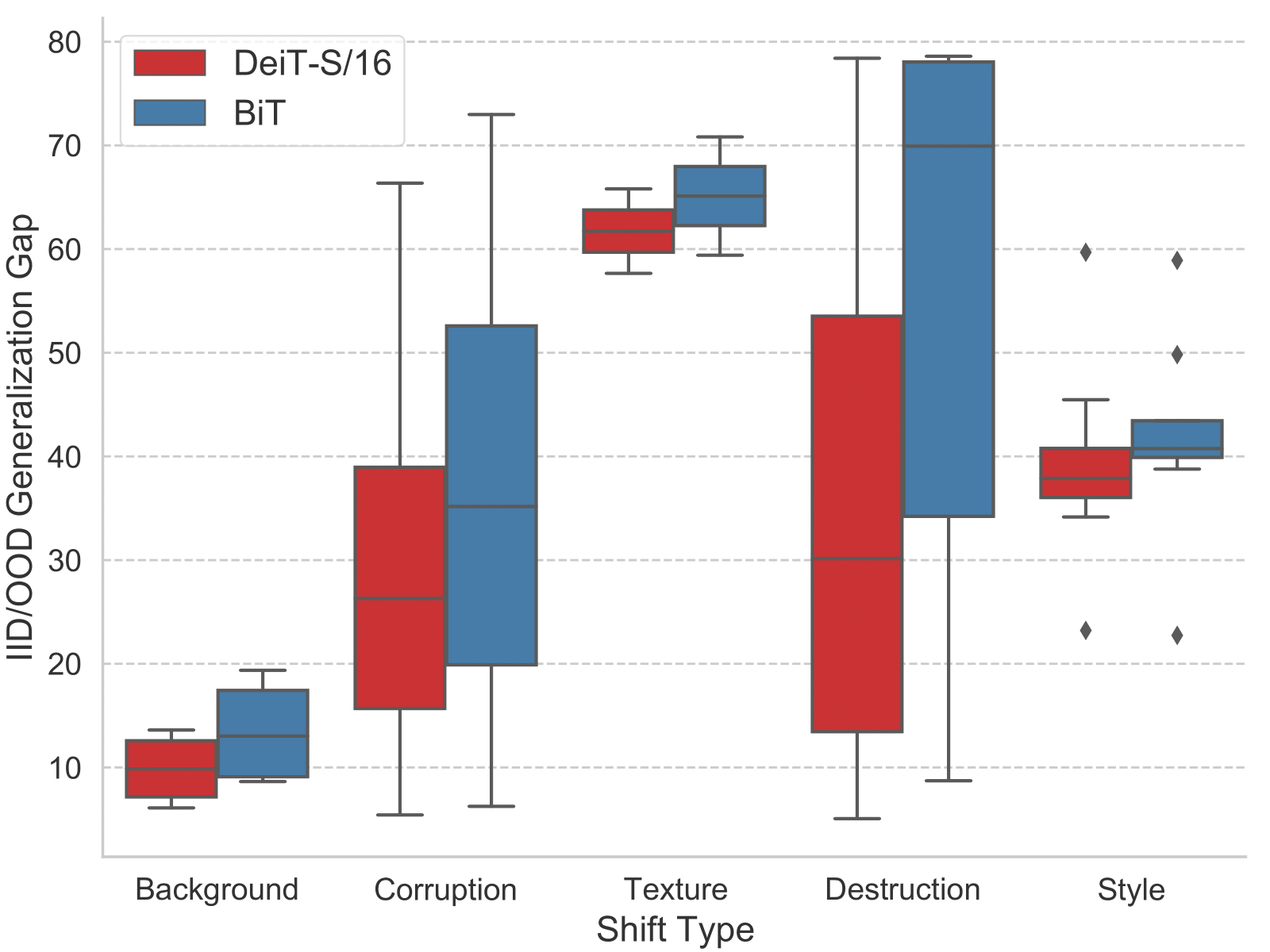
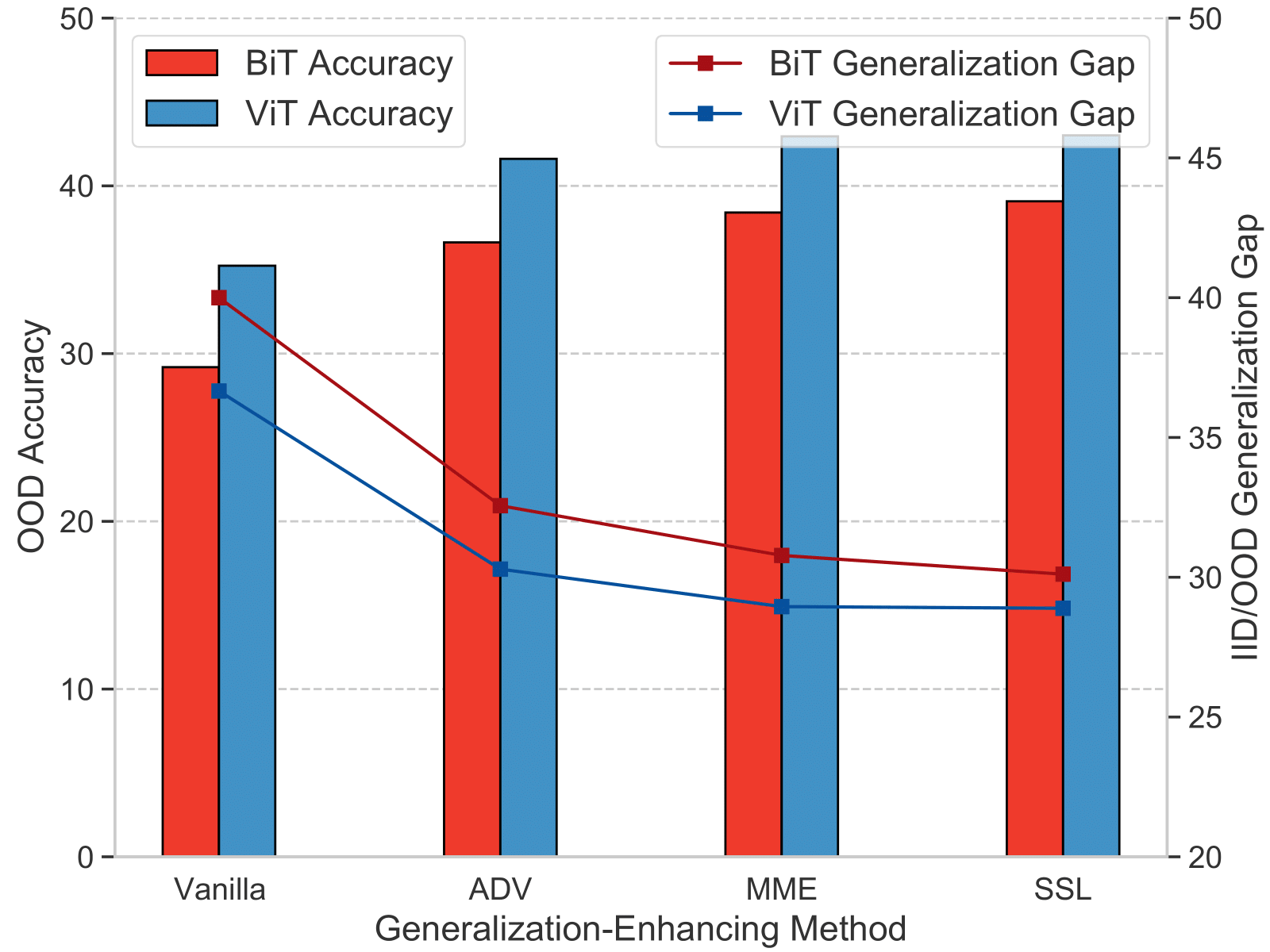
A quick glance of our investigation observations. left: Investigation of IID/OOD Generalization Gap implies that ViTs generalize better than CNNs under most types of distribution shifts. right: Combined with generalization-enhancing methods, we achieve significant performance boosts on the OOD data by 4% compared with vanilla ViTs, and consistently outperform the corresponding CNN models. The enhanced ViTs also have smaller IID/OOD Generalization Gap than the ehhanced BiT models.
Taxonomy of Distribution Shifts
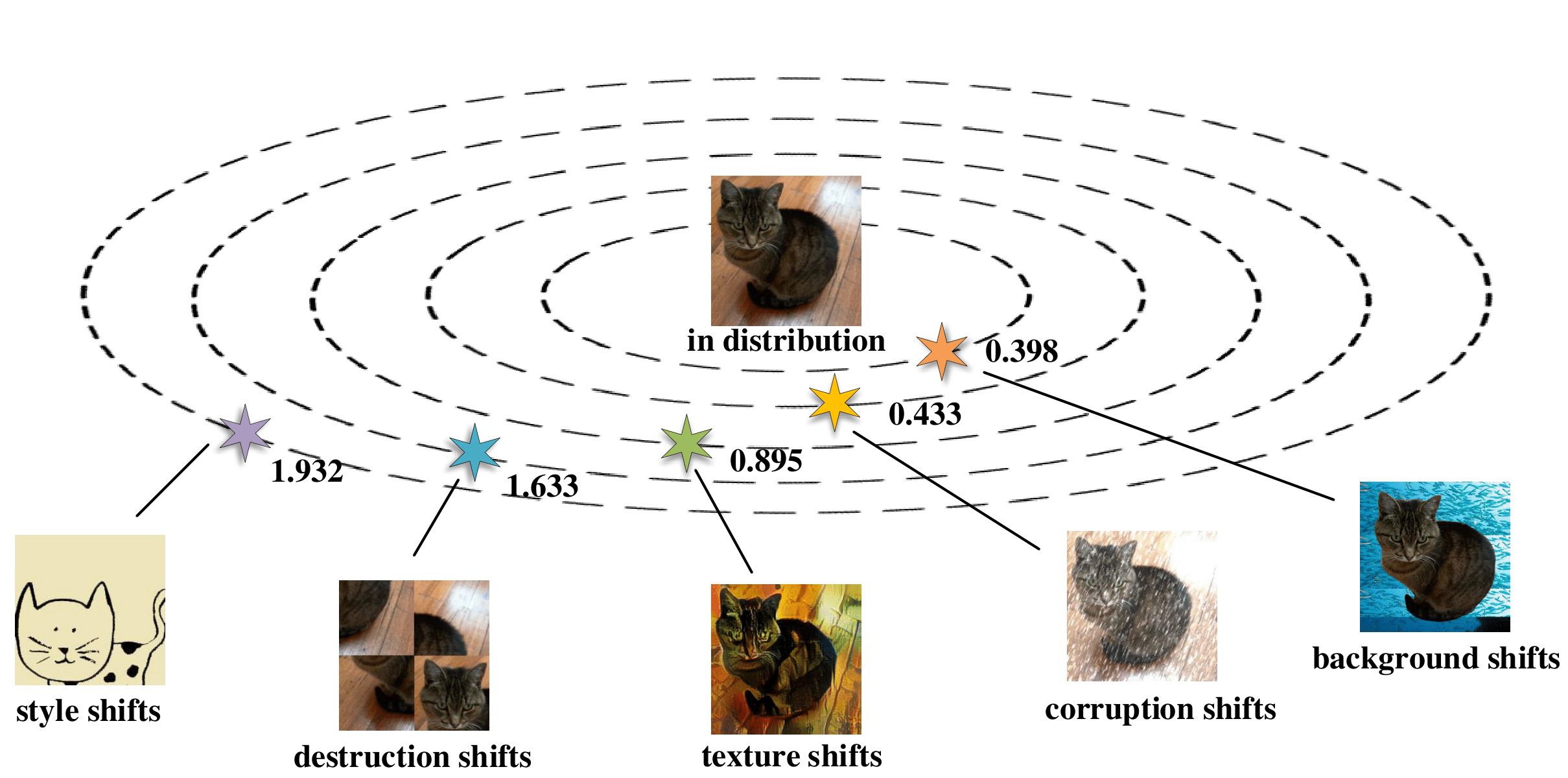
Illustration of our taxonomy of distribution shifts. We build the taxonomy upon what kinds of semantic concepts are modified from the original image. We divide the distribution shifts into five cases: background shifts, corruption shifts, texture shifts, destruction shifts, and style shifts. We apply the proxy -distance (PAD) as an empirical measurement of distribution shifts. We select a representative sample of each distribution shift type and rank them by their PAD values (illustrated nearby the stars), respectively. Please refer to the literature for details.
Datasets Used for Investigation
- Background Shifts. ImageNet-9 is adopted for background shifts. ImageNet-9 is a variety of 9-class datasets with different foreground-background recombination plans, which helps disentangle the impacts of foreground and background signals on classification. In our case, we use the four varieties of generated background with foreground unchanged, including 'Only-FG', 'Mixed-Same', 'Mixed-Rand' and 'Mixed-Next'. The 'Original' data set is used to represent in-distribution data.
- Corruption Shifts. ImageNet-C is used to examine generalization ability under corruption shifts. ImageNet-C includes 15 types of algorithmically generated corruptions, grouped into 4 categories: ‘noise’, ‘blur’, ‘weather’, and ‘digital’. Each corruption type has five levels of severity, resulting in 75 distinct corruptions.
- Texture Shifts. Cue Conflict Stimuli and Stylized-ImageNet are used to investigate generalization under texture shifts. Utilizing style transfer, Geirhos et al. generated Cue Conflict Stimuli benchmark with conflicting shape and texture information, that is, the image texture is replaced by another class with other object semantics preserved. In this case, we respectively report the shape and texture accuracy of classifiers for analysis. Meanwhile, Stylized-ImageNet is also produced in Geirhos et al. by replacing textures with the style of randomly selected paintings through AdaIN style transfer.
- Destruction Shifts. Random patch-shuffling is utilized for destruction shifts to destruct images into random patches. This process can destroy long-range object information and the severity increases as the split numbers grow. In addition, we make a variant by further divide each patch into two right triangles and respectively shuffle two types of triangles. We name the process triangular patch-shuffling.
- Style Shifts. ImageNet-R and DomainNet are used for the case of style shifts. ImageNet-R contains 30000 images with various artistic renditions of 200 classes of the original ImageNet validation data set. The renditions in ImageNet-R are real-world, naturally occurring variations, such as paintings or embroidery, with textures and local image statistics which differ from those of ImageNet images. DomainNet is a recent benchmark dataset for large-scale domain adaptation that consists of 345 classes and 6 domains. As labels of some domains are very noisy, we follow the 7 distribution shift scenarios in Saito et al. with 4 domains (Real, Clipart, Painting, Sketch) picked.
Generalization-Enhanced Vision Transformers
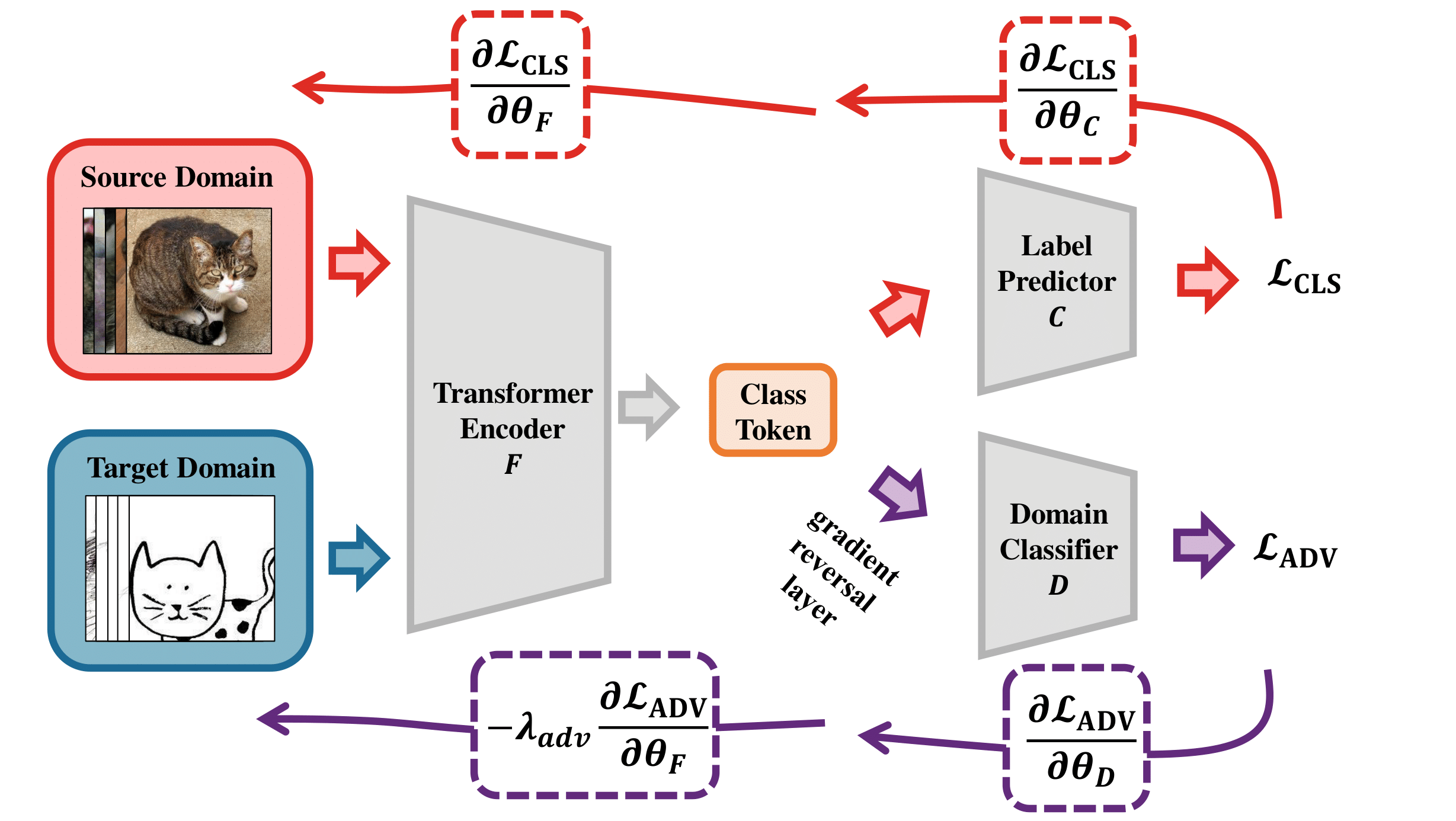
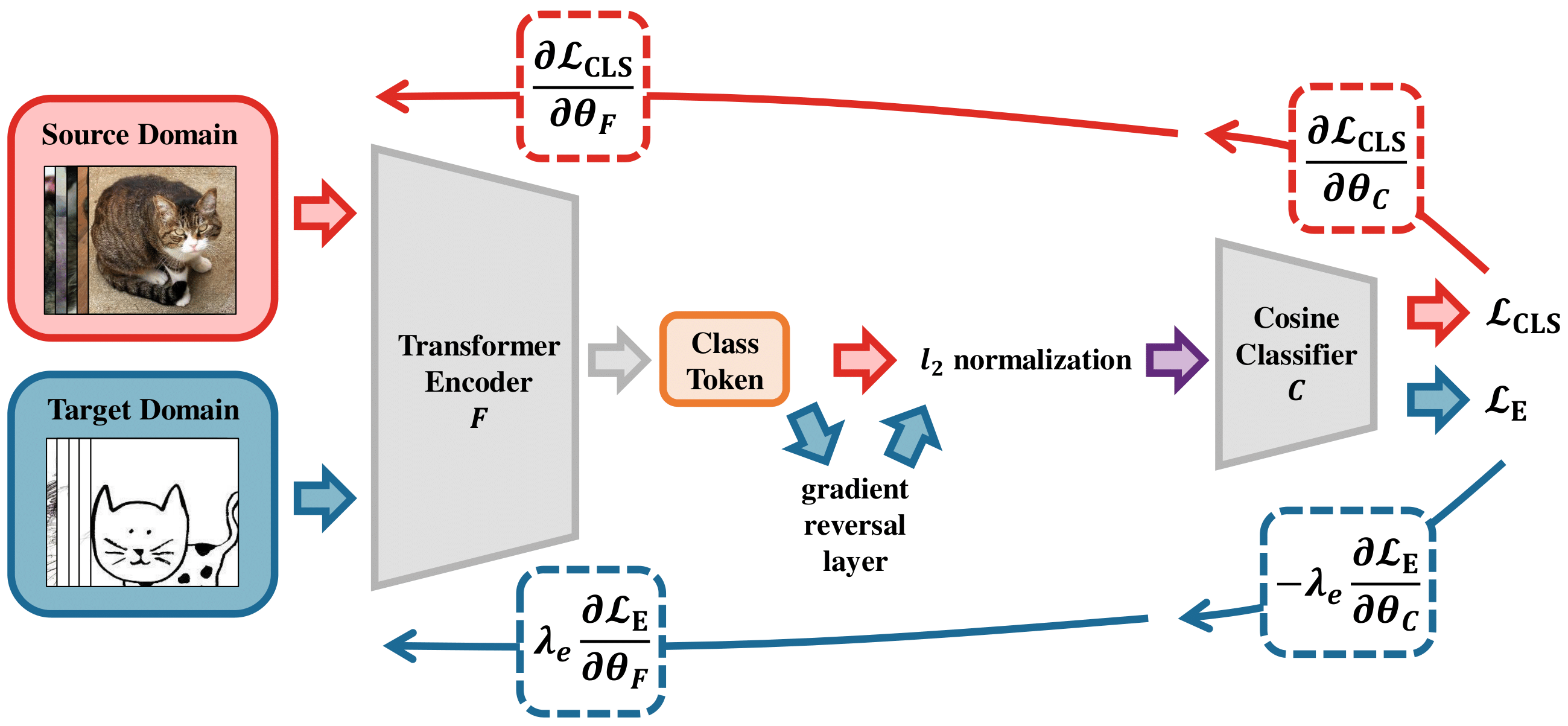
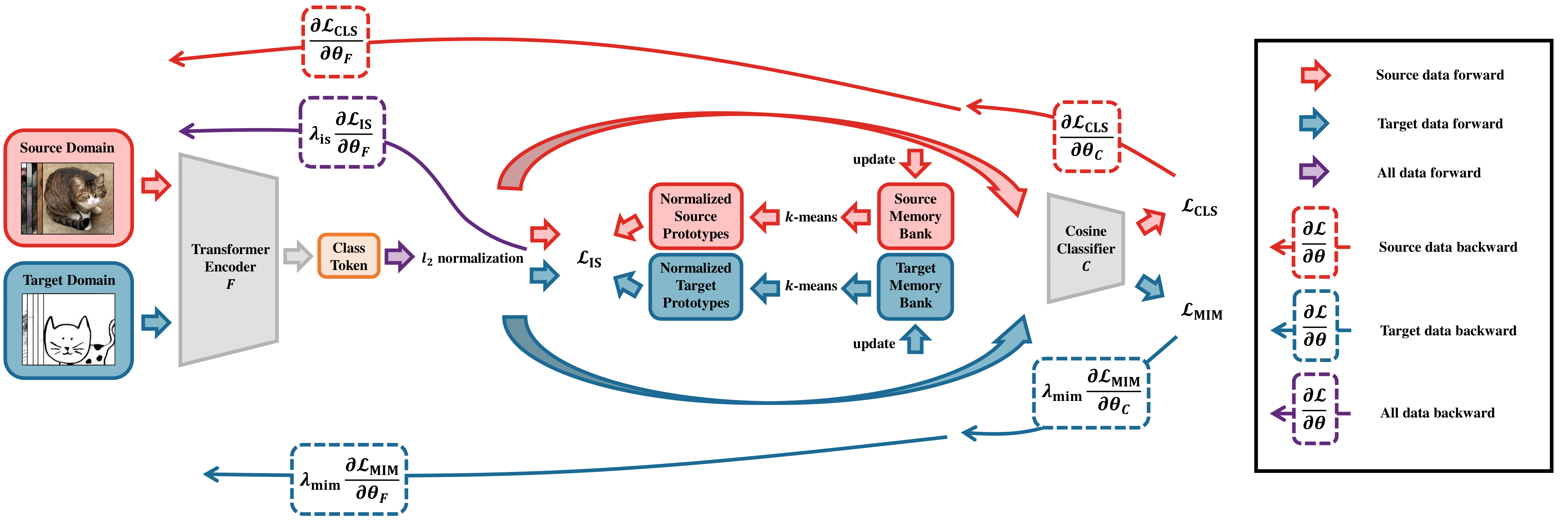
A framework overview of the three designed generalization-enhanced ViTs. All networks use a Vision Transformer as feature encoder and a label prediction head
. Under this setting, the inputs to the models have labeled source examples and unlabeled target examples. top left: T-ADV promotes the network to learn domain-invariant representations by introducing a domain classifier
for domain adversarial training. top right: T-MME leverage the minimax process on the conditional entropy of target data to reduce the distribution gap while learning discriminative features for the task. The network uses a cosine similarity-based classifier architecture
to produce class prototypes. bottom: T-SSL is an end-to-end prototype-based self-supervised learning framework. The architecture uses two memory banks
and
to calculate cluster centroids. A cosine classifier
is used for classification in this framework.
Run Our Code
Environment Installation
conda create -n vit python=3.6 conda activate vit conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.0 -c pytorch
Before Running
conda activate vit PYTHONPATH=$PYTHONPATH:.
Evaluation
CUDA_VISIBLE_DEVICES=0 python main.py \ --model deit_small_b16_384 \ --num-classes 345 \ --checkpoint data/checkpoints/deit_small_b16_384_baseline_real.pth.tar \ --meta-file data/metas/DomainNet/sketch_test.jsonl \ --root-dir data/images/DomainNet/sketch/test
Experimental Results
DomainNet
DeiT_small_b16_384
confusion matrix for the baseline model
| clipart | painting | real | sketch | |
|---|---|---|---|---|
| clipart | 80.25 | 33.75 | 55.26 | 43.43 |
| painting | 36.89 | 75.32 | 52.08 | 31.14 |
| real | 50.59 | 45.81 | 84.78 | 39.31 |
| sketch | 52.16 | 35.27 | 48.19 | 71.92 |
Above used models could be found here.
Remarks
- These results may slightly differ from those in our paper due to differences of the environments.
- We will continuously update this repo.
Citation
If you find these investigations useful in your research, please consider citing:
@misc{zhang2021delving,
title={Delving Deep into the Generalization of Vision Transformers under Distribution Shifts},
author={Chongzhi Zhang and Mingyuan Zhang and Shanghang Zhang and Daisheng Jin and Qiang Zhou and Zhongang Cai and Haiyu Zhao and Shuai Yi and Xianglong Liu and Ziwei Liu},
year={2021},
eprint={2106.07617},
archivePrefix={arXiv},
primaryClass={cs.CV}
}





