QA-GNN
QA-GNN: Question Answering using Language Models and Knowledge Graphs
This repo provides the source code & data of our paper: QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering (NAACL 2021).
@InProceedings{yasunaga2021qagnn,
author = {Michihiro Yasunaga and Hongyu Ren and Antoine Bosselut and Percy Liang and Jure Leskovec},
title = {QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering},
year = {2021},
booktitle = {North American Chapter of the Association for Computational Linguistics (NAACL)},
}
Webpage: https://snap.stanford.edu/qagnn
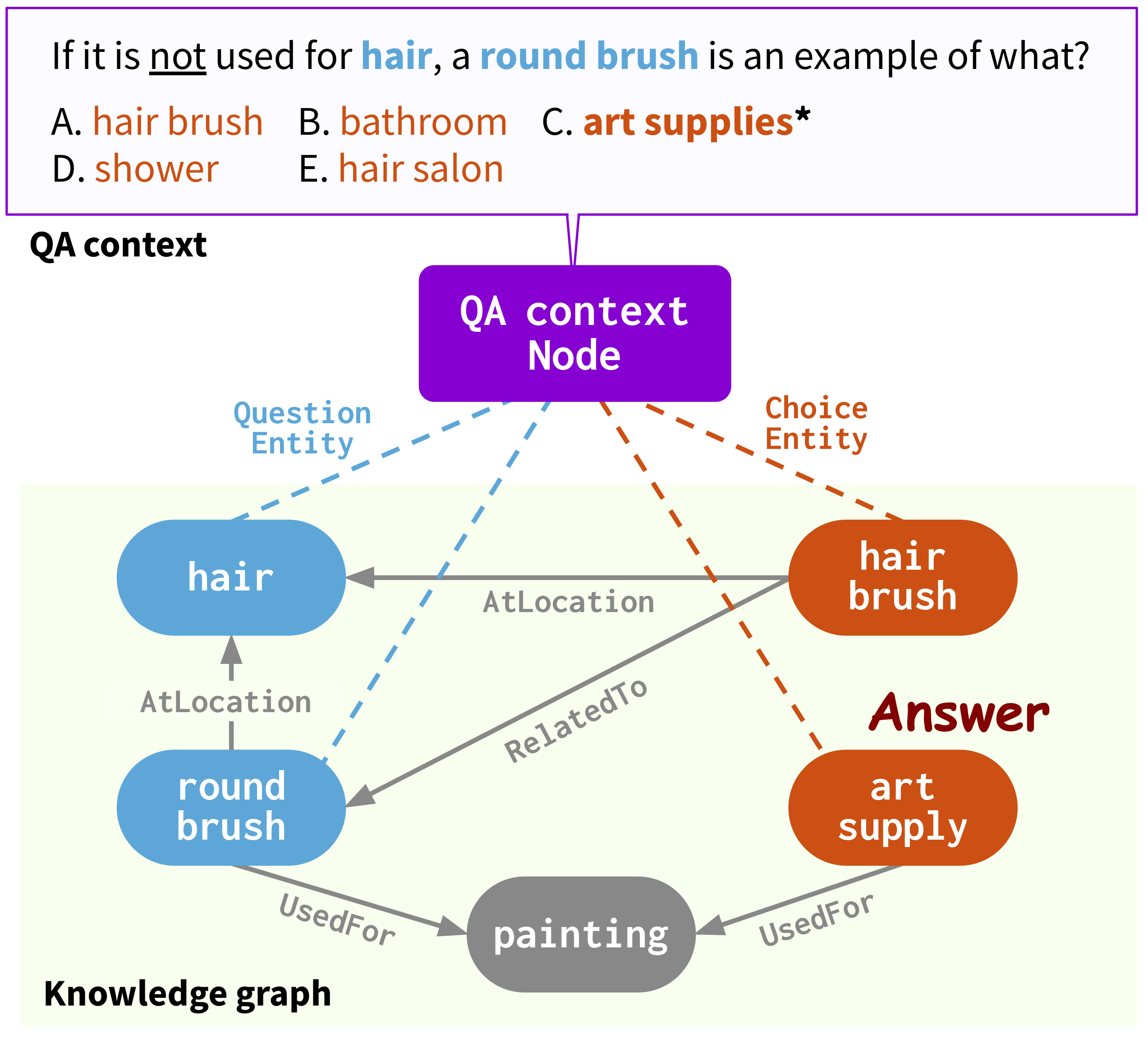
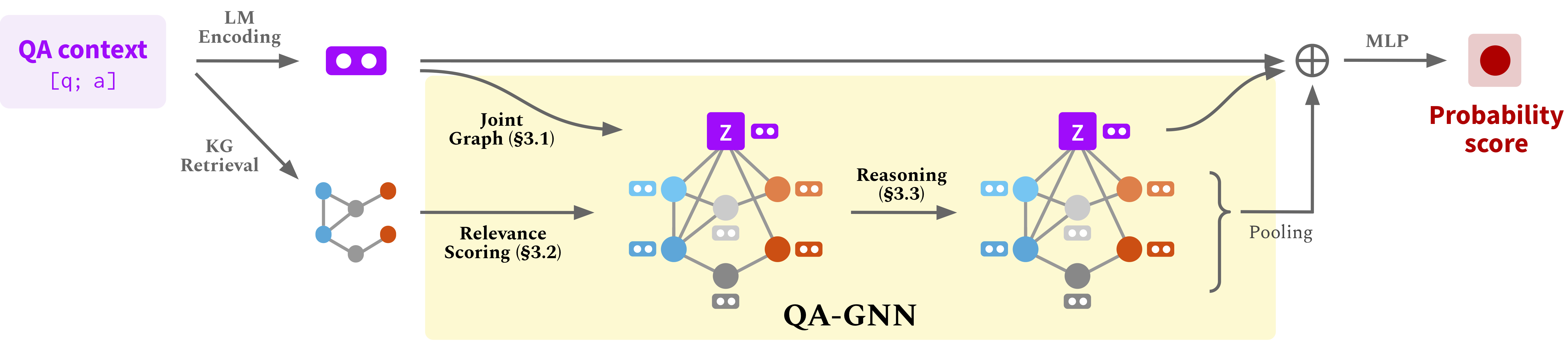
Usage
0. Dependencies
- Python == 3.7
- PyTorch == 1.4.0
- transformers == 2.0.0
- torch-geometric ==1.6.0
Run the following commands to create a conda environment (assuming CUDA10.1):
conda create -n qagnn python=3.7
source activate qagnn
pip install numpy==1.18.3 tqdm
pip install torch==1.4.0 torchvision==0.5.0
pip install transformers==2.0.0 nltk spacy==2.1.6
python -m spacy download en
#for torch-geometric
pip install torch-scatter==2.0.4 -f https://pytorch-geometric.com/whl/torch-1.4.0+cu101.html
pip install torch-cluster==1.5.4 -f https://pytorch-geometric.com/whl/torch-1.4.0+cu101.html
pip install torch-sparse==0.6.1 -f https://pytorch-geometric.com/whl/torch-1.4.0+cu101.html
pip install torch-spline-conv==1.2.0 -f https://pytorch-geometric.com/whl/torch-1.4.0+cu101.html
pip install torch-geometric==1.6.0 -f https://pytorch-geometric.com/whl/torch-1.4.0+cu101.html
1. Download Data
Download all the raw data -- ConceptNet, CommonsenseQA, OpenBookQA -- by
./download_raw_data.sh
You can preprocess the raw data by running
python preprocess.py -p <num_processes>
The script will:
- Setup ConceptNet (e.g., extract English relations from ConceptNet, merge the original 42 relation types into 17 types)
- Convert the QA datasets into .jsonl files (e.g., stored in
data/csqa/statement/) - Identify all mentioned concepts in the questions and answers
- Extract subgraphs for each q-a pair
TL;DR. The preprocessing may take long; for your convenience, you can download all the processed data by
./download_preprocessed_data.sh
The resulting file structure will look like:
.
├── README.md
└── data/
├── cpnet/ (prerocessed ConceptNet)
└── csqa/
├── train_rand_split.jsonl
├── dev_rand_split.jsonl
├── test_rand_split_no_answers.jsonl
├── statement/ (converted statements)
├── grounded/ (grounded entities)
├── graphs/ (extracted subgraphs)
├── ...
2. Training
For CommonsenseQA, run
./run_qagnn__csqa.sh
For OpenBookQA, run
./run_qagnn__obqa.sh
As configured in these scripts, the model needs two types of input files
--{train,dev,test}_statements: preprocessed question statements in jsonl format. This is mainly loaded byload_input_tensorsfunction inutils/data_utils.py.--{train,dev,test}_adj: information of the KG subgraph extracted for each question. This is mainly loaded byload_sparse_adj_data_with_contextnodefunction inutils/data_utils.py.
Trained model example
CommonsenseQA
| Trained model | In-house Dev acc. | In-house Test acc. |
|---|---|---|
| RoBERTa-large + QA-GNN [link] | 0.7633 | 0.7405 |
Use your own dataset
- Convert your dataset to
{train,dev,test}.statement.jsonlin .jsonl format (seedata/csqa/statement/train.statement.jsonl) - Create a directory in
data/{yourdataset}/to store the .jsonl files - Modify
preprocess.pyand perform subgraph extraction for your data - Modify
utils/parser_utils.pyto support your own dataset
Acknowledgment
This repo is built upon the following work:
Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering. Yanlin Feng*, Xinyue Chen*, Bill Yuchen Lin, Peifeng Wang, Jun Yan and Xiang Ren. EMNLP 2020.
https://github.com/INK-USC/MHGRN
Many thanks to the authors and developers!






