Training-code-of-STM
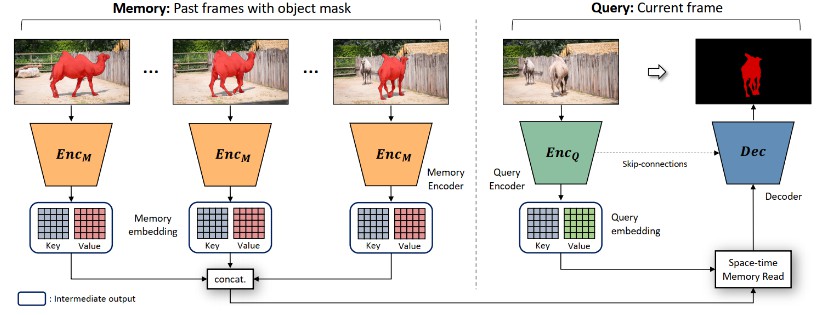
This repository fully reproduces Space-Time Memory Networksimage
Performance on Davis17 val set&Weights
| backbone | training stage | training dataset | J&F | J | F | weights | |
|---|---|---|---|---|---|---|---|
| Ours | resnet-50 | stage 1 | MS-COCO | 69.5 | 67.8 | 71.2 | link |
| Origin | resnet-50 | stage 2 | MS-COCO -> Davis&Youtube-vos | 81.8 | 79.2 | 84.3 | link |
| Ours | resnet-50 | stage 2 | MS-COCO -> Davis&Youtube-vos | 82.0 | 79.7 | 84.4 | link |
| Ours | resnest-101 | stage 2 | MS-COCO -> Davis&Youtube-vos | 84.6 | 82.0 | 87.2 | link |
Requirements
- Python >= 3.6
- Pytorch 1.5
- Numpy
- Pillow
- opencv-python
- imgaug
- scipy
- tqdm
- pandas
- resnest
Datasets
MS-COCO
We use MS-COCO's instance segmentation part to generate pseudo video sequence. Specifically, we cut out the objects in one image and paste them on another one. Then we perform different affine transformations on the foreground objects and the background image. If you want to visualize some of the processed training frame sequence:
python dataset/coco.py -Ddavis "path to davis" -Dcoco "path to coco" -o "path to output dir"


DAVIS
Youtube-VOS
Structure
|- data
|- Davis
|- JPEGImages
|- Annotations
|- ImageSets
|- Youtube-vos
|- train
|- valid
|- Ms-COCO
|- train2017
|- annotations
|- instances_train2017.json
Demo
python demo.py -g "gpu id" -s "set" -y "year" -D "path to davis" -p "path to weights" -backbone "[resnet50,resnet18,resnest101]"
#e.g.
python demo.py -g 0 -s val -y 17 -D ../data/Davis/ -p /smart/haochen/cvpr/0628_resnest_aspp/davis_youtube_resnest101_699999.pth -backbone resnest101
Training
Stage 1
Pretraining on MS-COCO.
python train_coco.py -Ddavis "path to davis" -Dcoco "path to coco" -backbone "[resnet50,resnet18]" -save "path to checkpoints"
#e.g.
python train_coco.py -Ddavis ../data/Davis/ -Dcoco ../data/Ms-COCO/ -backbone resnet50 -save ../coco_weights/
Stage 2
Training on Davis&Youtube-vos.
python train_davis.py -Ddavis "path to davis" -Dyoutube "path to youtube-vos" -backbone "[resnet50,resnet18]" -save "path to checkpoints" -resume "path to coco pretrained weights"
#e.g.
train_davis.py -Ddavis ../data/Davis/ -Dyoutube ../data/Youtube-vos/ -backbone resnet50 -save ../davis_weights/ -resume ../coco_weights/coco_pretrained_resnet50_679999.pth
Evaluation
Evaluating on Davis 2017&2016 val set.
python eval.py -g "gpu id" -s "set" -y "year" -D "path to davis" -p "path to weights" -backbone "[resnet50,resnet18,resnest101]"
#e.g.
python eval.py -g 0 -s val -y 17 -D ../data/davis -p ../davis_weights/davis_youtube_resnet50_799999.pth -backbone resnet50
python eval.py -g 0 -s val -y 17 -D ../data/davis -p ../davis_weights/davis_youtube_resnest101_699999.pth -backbone resnest101
Notes
- STM is an attention-based implicit matching architecture, which needs large amounts of data for training. The first stage of training is necessary if you want to get better results.
- Training takes about three days on a single NVIDIA 2080Ti. There is no log during training, you could add logs if you need.
- Due to time constraints, the code is a bit messy and need to be optimized. Questions and suggestions are welcome.
Acknowledgement
This codebase borrows the code and structure from official STM repository
Citing STM
@inproceedings{oh2019video,
title={Video object segmentation using space-time memory networks},
author={Oh, Seoung Wug and Lee, Joon-Young and Xu, Ning and Kim, Seon Joo},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={9226--9235},
year={2019}
}








