Style Augmented Translation
By collecting high-quality data, we were able to train a model that outperforms Google Translate on 6 different domains of English-Vietnamese Translation.
English to Vietnamese Translation (BLEU score)
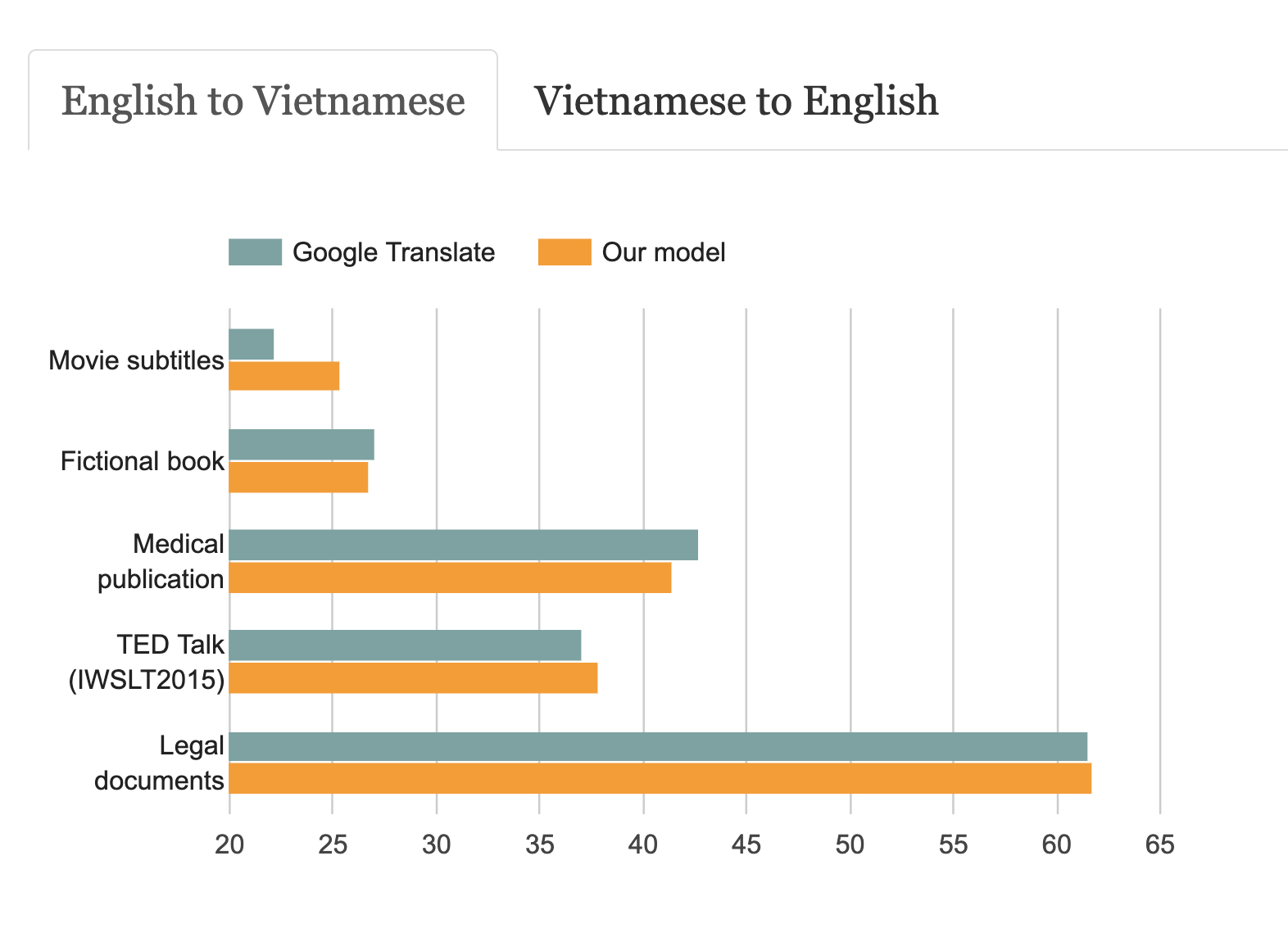
Vietnamese to English Translation (BLEU score)
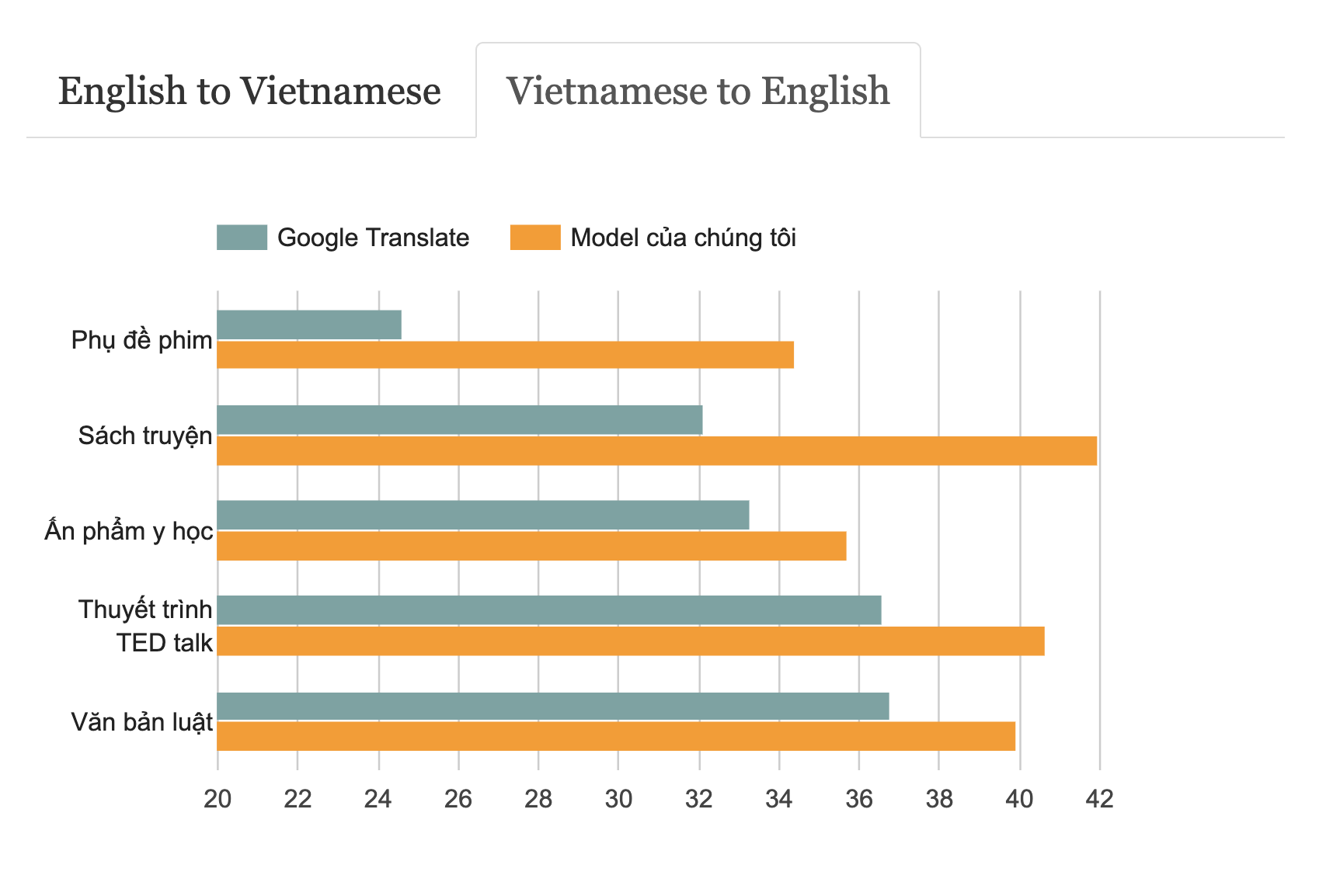
Get data and model at Google Cloud Storage
Check out our demo web app
Visit our blog post for more details.
Using the code
This code is build on top of vietai/dab:
To prepare for training, generate tfrecords from raw text files:
python t2t_datagen.py \
--data_dir=$path_to_folder_contains_vocab_file \
--tmp_dir=$path_to_folder_that_contains_training_data \
--problem=$problem
To train a Transformer model on the generated tfrecords
python t2t_trainer.py \
--data_dir=$path_to_folder_contains_vocab_file_and_tf_records \
--problem=$problem \
--hparams_set=$hparams_set \
--model=transformer \
--output_dir=$path_to_folder_to_save_checkpoints
To run inference on the trained model:
python t2t_decoder.py \
--data_dir=$path_to_folde_contains_vocab_file_and_tf_records \
--problem=$problem \
--hparams_set=$hparams_set \
--model=transformer \
--output_dir=$path_to_folder_contains_checkpoints \
--checkpoint_path=$path_to_checkpoint
In this colab, we demonstrated how to run these three phases in the context of hosting data/model on Google Cloud Storage.
Dataset
Our data contains roughly 3.3 million pairs of texts. After augmentation, the data is of size 26.7 million pairs of texts. A more detail breakdown of our data is shown in the table below.
| Pure | Augmented | |
|---|---|---|
| Fictional Books | 333,189 | 2,516,787 |
| Legal Document | 1,150,266 | 3,450,801 |
| Medical Publication | 5,861 | 27,588 |
| Movies Subtitles | 250,000 | 3,698,046 |
| Software | 79,912 | 239,745 |
| TED Talk | 352,652 | 4,983,294 |
| Wikipedia | 645,326 | 1,935,981 |
| News | 18,449 | 139,341 |
| Religious texts | 124,389 | 1,182,726 |
| Educational content | 397,008 | 8,475,342 |
| No tag | 5,517 | 66,299 |
| Total | 3,362,569 | 26,715,950 |
Data sources is described in more details here.
Acknowledgment
We would like to thank Google for the support of Cloud credits and TPU quota!




