Voice Activity Detection project
Voice Activity Detection based on Deep Learning & TensorFlow.
1. Installation
This project was designed for:
- Ubuntu 18.04
- Python 3.6
- TensorFlow 1.12.0
Please install requirements & project:
$ cd /path/to/project/
$ git clone https://github.com/filippogiruzzi/voice_activity_detection.git
$ cd voice_activity_detection/
$ pip3 install -r requirements.txt
$ pip3 install -e . --user --upgrade
2. Introduction
2.1 Goal
The purpose of this project is to design and implement
a real-time Voice Activity Detection algorithm based on Deep Learning.
The designed solution is based on MFCC feature extraction and
a 1D-Resnet model that classifies whether a audio signal is
speech or noise.
2.2 Results
| Model | Train acc. | Val acc. | Test acc. |
|---|---|---|---|
| 1D-Resnet | 99 % | 98 % | 97 % |
Raw and post-processed inference results on a test audio signal are shown below.
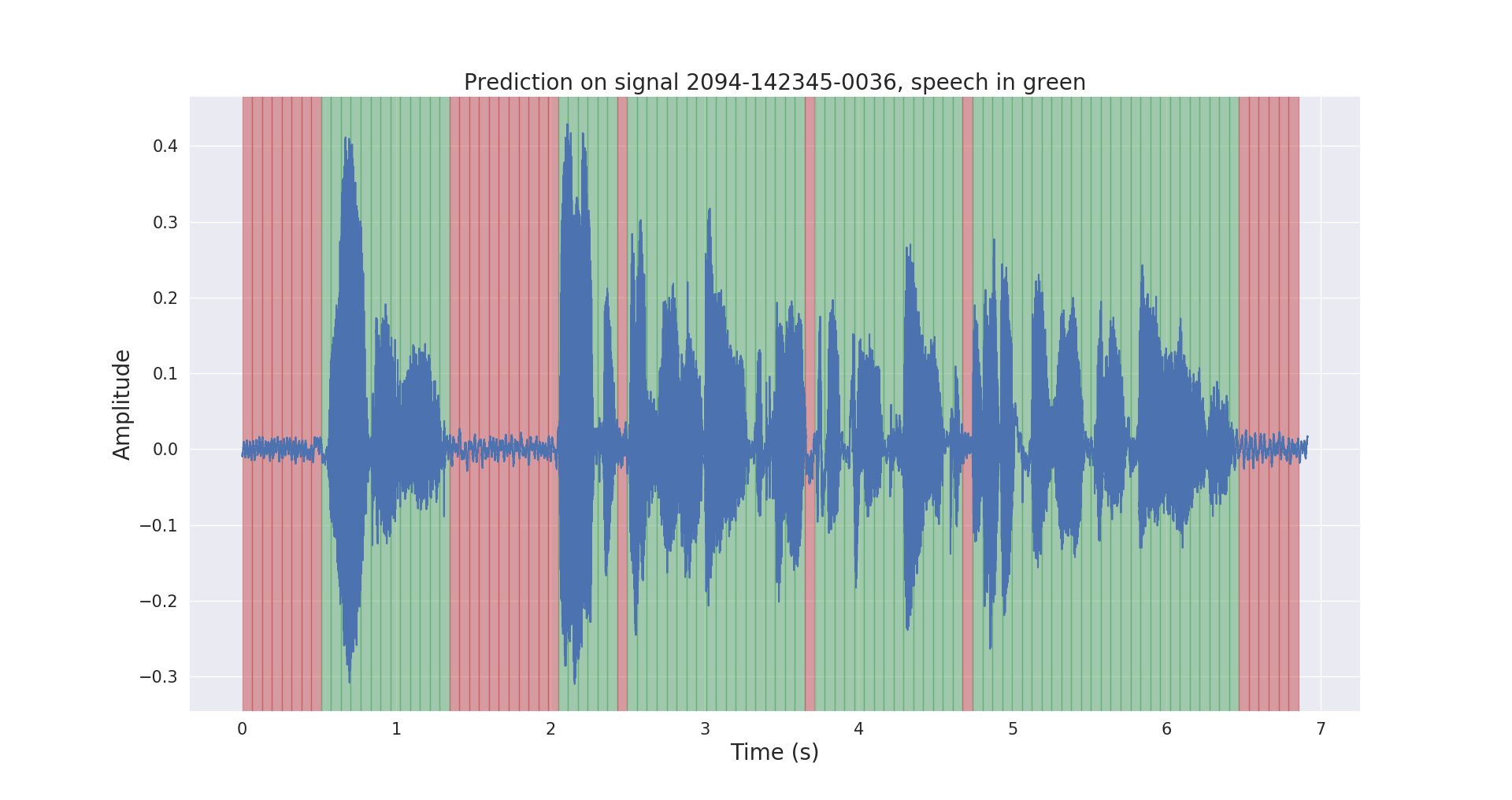
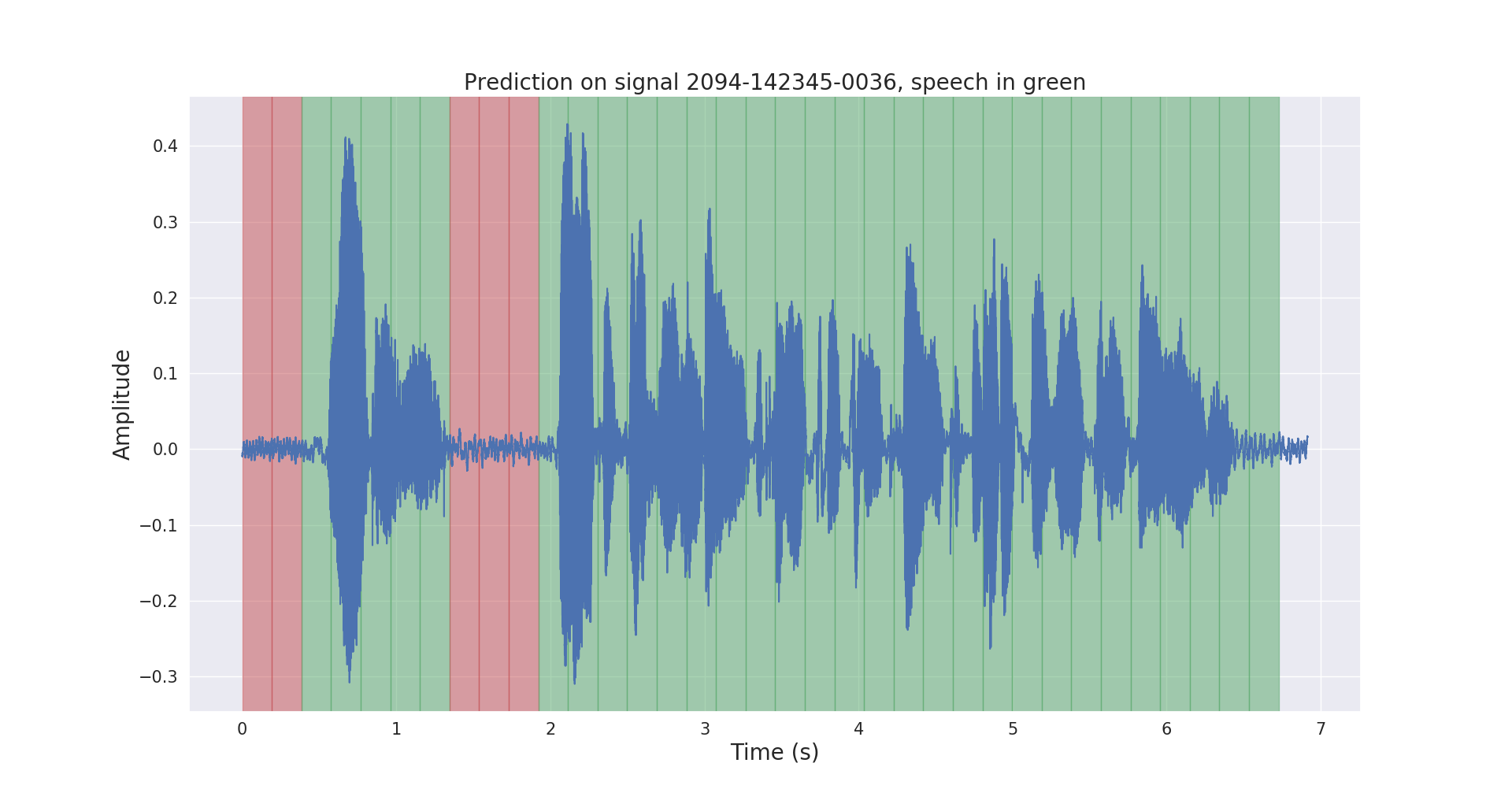
3. Project structure
The project voice_activity_detection/ has the following structure:
vad/data_processing/: raw data labeling, processing,
recording & visualizationvad/training/: data, input pipeline, model
& training / evaluation / predictionvad/inference/: exporting trained model & inference
4. Dataset
Please download the LibriSpeech ASR corpus dataset from https://openslr.org/12/,
and extract all files to : /path/to/LibriSpeech/.
The dataset contains approximately 1000 hours of 16kHz read English speech
from audiobooks, and is well suited for Voice Activity Detection.
I automatically annotated the test-clean set of the dataset with a
pretrained VAD model.
Please feel free to use the labels/ folder and the pre-trained VAD model (only for inference) from this
link .
5. Project usage
$ cd /path/to/project/voice_activity_detection/vad/
5.1 Dataset automatic labeling
Skip this subsection if you already have the labels/ folder, that contains annotations
from a different pre-trained model.
$ python3 data_processing/librispeech_label_data.py --data_dir /path/to/LibriSpeech/test-clean/
--exported_model /path/to/pretrained/model/
--out_dir /path/to/LibriSpeech/labels/
This will record the annotations into /path/to/LibriSpeech/labels/ as
.json files.
5.2 Record raw data to .tfrecord format
$ python3 data_processing/data_to_tfrecords.py --data_dir /path/to/LibriSpeech/
This will record the splitted data to .tfrecord format in /path/to/LibriSpeech/tfrecords/
5.3 Train a CNN to classify Speech & Noise signals
$ python3 training/train.py --data-dir /path/to/LibriSpeech/tfrecords/
5.4 Export trained model & run inference on Test set
$ python3 inference/export_model.py --model-dir /path/to/trained/model/dir/
--ckpt /path/to/trained/model/dir/
$ python3 inference/inference.py --data_dir /path/to/LibriSpeech/
--exported_model /path/to/exported/model/
--smoothing
The trained model will be recorded in /path/to/LibriSpeech/tfrecords/models/resnet1d/.
The exported model will be recorded inside this directory.
6. Todo
- [ ] Compare Deep Learning model to a simple baseline
- [ ] Train on full dataset
- [ ] Improve data balancing
- [ ] Add time series data augmentation
- [ ] Study ROC curve & classification threshold
- [ ] Add online inference
- [ ] Evaluate quantitatively post-processing methods on the Test set
- [ ] Add model description & training graphs
- [ ] Add Google Colab demo
7. Resources
- Voice Activity Detection for Voice User Interface,
Medium - Deep learning for time series classifcation: a review,
Fawaz et al., 2018, Arxiv - Time Series Classification from Scratch
with Deep Neural Networks: A Strong Baseline, Wang et al., 2016,
Arxiv



