WaveGrad 2
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Unofficial PyTorch+Lightning Implementation of Chen et al.(JHU, Google Brain), WaveGrad2.
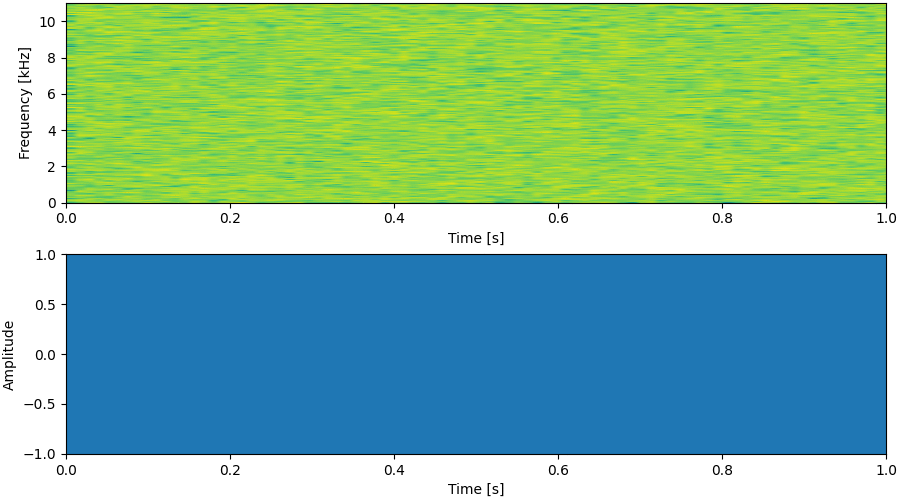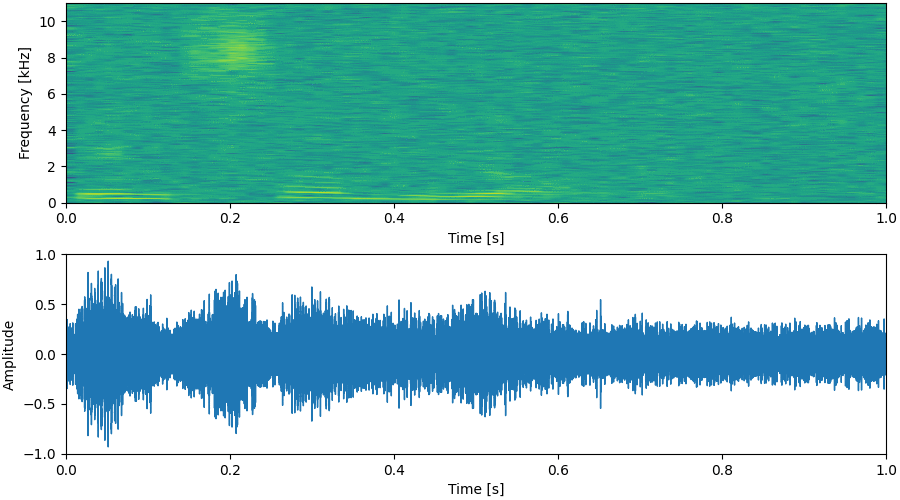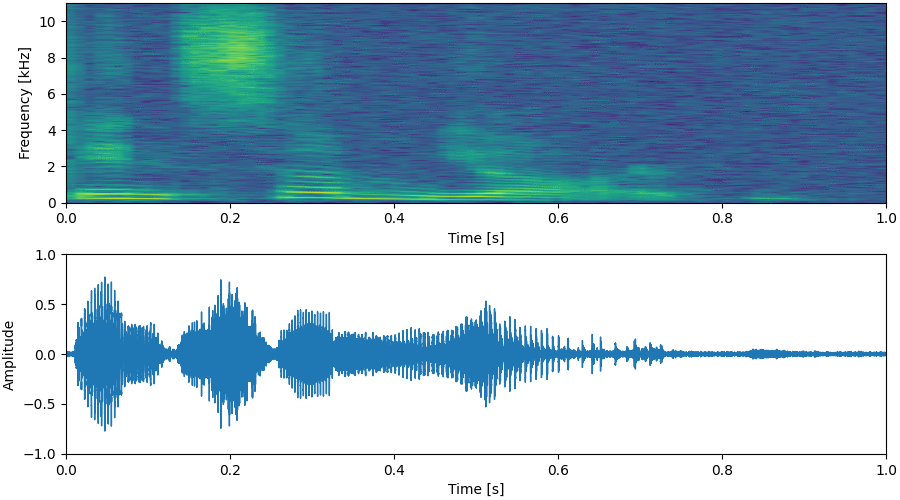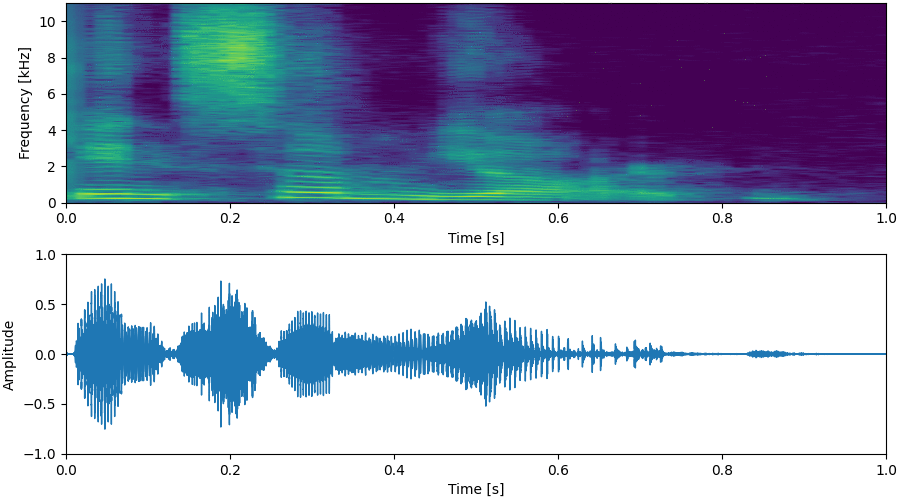
Update: Enjoy our pre-trained model with Google Colab notebook!
TODO
- More training for WaveGrad-Base setup
- Checkpoint release for Base
- WaveGrad-Large Decoder
- Checkpoint release for Large
- Inference by reduced sampling steps
Requirements
- Pytorch
- Pytorch-Lightning==1.2.10
- The requirements are highlighted in requirements.txt.
- We also provide docker setup Dockerfile.
Datasets
The supported datasets are
- LJSpeech: a single-speaker English dataset consists of 13100 short audio clips of a female speaker reading passages from 7 non-fiction books, approximately 24 hours in total.
- AISHELL-3: a Mandarin TTS dataset with 218 male and female speakers, roughly 85 hours in total.
- etc.
We take LJSpeech as an example hereafter.
Preprocessing
-
Adjust
preprocess.yaml, especiallypathsection.path:
corpus_path: '/DATA1/LJSpeech-1.1' # LJSpeech corpus path
lexicon_path: 'lexicon/librispeech-lexicon.txt'
raw_path: './raw_data/LJSpeech'
preprocessed_path: './preprocessed_data/LJSpeech' -
run
prepare_align.pyfor some preparations.python prepare_align.py -c preprocess.yaml
-
Montreal Forced Aligner (MFA) is used to obtain the alignments between the utterances and the phoneme sequences. Alignments for the LJSpeech and AISHELL-3 datasets are provided here. You have to unzip the files in
preprocessed_data/LJSpeech/TextGrid/. -
After that, run
preprocess.py.python preprocess.py -c preprocess.yaml
-
Alternately, you can align the corpus by yourself.
-
Download the official MFA package and run it to align the corpus.
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
or
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
-
And then run
preprocess.py.python preprocess.py -c preprocess.yaml
Training
-
Adjust
hparameter.yaml, especiallytrainsection.train:
batch_size: 12 # Dependent on GPU memory size
adam:
lr: 3e-4
weight_decay: 1e-6
decay:
rate: 0.05
start: 25000
end: 100000
num_workers: 16 # Dependent on CPU cores
gpus: 2 # number of GPUs
loss_rate:
dur: 1.0 -
If you want to train with other dataset, adjust
datasection inhparameter.yamldata:
lang: 'eng'
text_cleaners: ['english_cleaners'] # korean_cleaners, english_cleaners, chinese_cleaners
speakers: ['LJSpeech']
train_dir: 'preprocessed_data/LJSpeech'
train_meta: 'train.txt' # relative path of metadata file from train_dir
val_dir: 'preprocessed_data/LJSpeech'
val_meta: 'val.txt' # relative path of metadata file from val_dir'
lexicon_path: 'lexicon/librispeech-lexicon.txt' -
run
trainer.pypython trainer.py
-
If you want to resume training from checkpoint, check parser.
parser = argparse.ArgumentParser()
parser.add_argument('-r', '--resume_from', type =int,
required = False, help = "Resume Checkpoint epoch number")
parser.add_argument('-s', '--restart', action = "store_true",
required = False, help = "Significant change occured, use this")
parser.add_argument('-e', '--ema', action = "store_true",
required = False, help = "Start from ema checkpoint")
args = parser.parse_args() -
During training, tensorboard logger is logging loss, spectrogram and audio.
tensorboard --logdir=./tensorboard --bind_all

Inference
-
run
inference.pypython inference.py -c <checkpoint_path> --text <'text'>
We provide a Jupyter Notebook script to provide the code for inference and show some visualizations with resulting audio.
- Colab notebook This notebook provides pre-trained weights for WaveGrad 2 and you can download it via url inside (Now only
WaveGrad-Basedecoder).
Checkpoint file for Large will be also released!
Large Decoder
We implemented WaveGrad-Large decoder for high MOS output.
Note: it could be different with google's implementation since number of parameters are different with paper's value.
-
To train with Large model you need to modify
hparameter.yaml.wavegrad:
is_large: True #if False, Base
...
dilations: [[1,2,4,8],[1,2,4,8],[1,2,4,8],[1,2,4,8],[1,2,4,8]] #dilations for Large
#dilations: [[1,2,4,8],[1,2,4,8],[1,2,4,8],[1,2,1,2],[1,2,1,2]] dilations for Base -
Go back to Training section.
Note
Since this repo is unofficial implementation and WaveGrad2 paper do not provide several details, a slight differences between paper could exist.
We listed modifications or arbitrary setups
- Normal LSTM without ZoneOut is applied for encoder.
- g2p_en is applied instead of Google's unknown G2P.
- Trained with LJSpeech datasdet instead of Google's proprietary dataset.
- Due to dataset replacement, output audio's sampling rate becomes 22.05kHz instead of 24kHz.
- MT + SpecAug are not implemented.
- WaveGrad decoder shares same issues from ivanvovk's WaveGrad implementation.
WaveGrad-Largedecoder's architecture could be different with Google's implementation.- hyperparameters
train.batch_size: 12for Base andtrain.batch_size: 6for Large, Trained with 2 V100 (32GB) GPUstrain.adam.lr: 3e-4andtrain.adam.weight_decay: 1e-6train.decaylearning rate decay is applied during trainingtrain.loss_rate: 1astotal_loss = 1 * L1_loss + 1 * duration_lossddpm.ddpm_noise_schedule: torch.linspace(1e-6, 0.01, hparams.ddpm.max_step)encoder.channelis reduced to 512 from 1024 or 2048
- TODO things.
Tree
.
├── Dockerfile
├── README.md
├── dataloader.py
├── docs
│ ├── spec.png
│ ├── tb.png
│ └── tblogger.png
├── hparameter.yaml
├── inference.py
├── lexicon
│ ├── librispeech-lexicon.txt
│ └── pinyin-lexicon-r.txt
├── lightning_model.py
├── model
│ ├── base.py
│ ├── downsampling.py
│ ├── encoder.py
│ ├── gaussian_upsampling.py
│ ├── interpolation.py
│ ├── layers.py
│ ├── linear_modulation.py
│ ├── nn.py
│ ├── resampling.py
│ ├── upsampling.py
│ └── window.py
├── prepare_align.py
├── preprocess.py
├── preprocess.yaml
├── preprocessor
│ ├── ljspeech.py
│ └── preprocessor.py
├── text
│ ├── __init__.py
│ ├── cleaners.py
│ ├── cmudict.py
│ ├── numbers.py
│ └── symbols.py
├── trainer.py
├── utils
│ ├── mel.py
│ ├── stft.py
│ ├── tblogger.py
│ └── utils.py
└── wavegrad2_tester.ipynb
Author
This code is implemented by
- Seungu Han at MINDs Lab [email protected]
- Junhyeok Lee at MINDs Lab [email protected]






