PoseFormer
3D Human Pose Estimation with Spatial and Temporal Transformers
This repo is the official implementation for 3D Human Pose Estimation with Spatial and Temporal Transformers. The paper is accepted to ICCV 2021.
PoseFormer Architecture

Video Demo
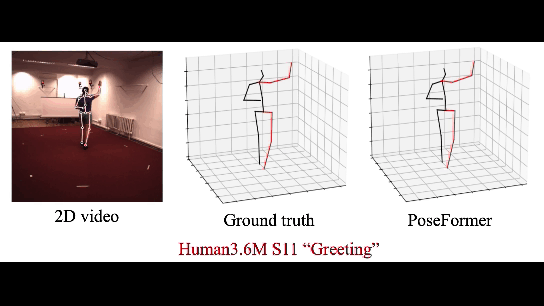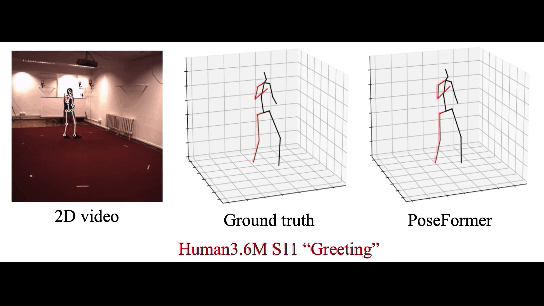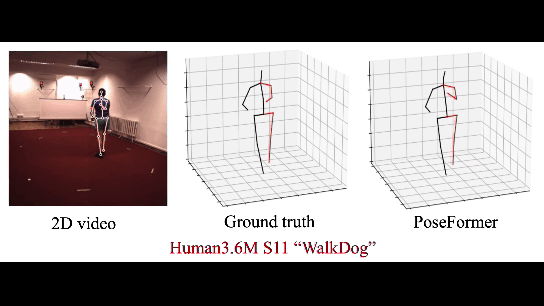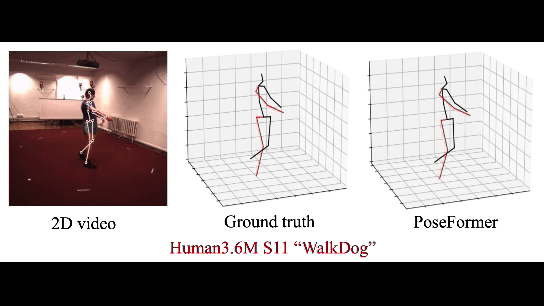 |
|---|
| 3D HPE on Human3.6M |
 |
|---|
| 3D HPE on videos in-the-wild using PoseFormer |
Our code is built on top of VideoPose3D.
Environment
The code is developed and tested under the following environment
- Python 3.8.2
- PyTorch 1.7.1
- CUDA 11.0
You can create the environment:
conda env create -f poseformer.yml
Dataset
Our code is compatible with the dataset setup introduced by Martinez et al. and Pavllo et al.. Please refer to VideoPose3D to set up the Human3.6M dataset (./data directory).
Evaluating pre-trained models
We provide the pre-trained 81-frame model (CPN detected 2D pose as input) here. To evaluate it, put it into the ./checkpoint directory and run:
python run_poseformer.py -k cpn_ft_h36m_dbb -f 81 -c checkpoint --evaluate detected81f.bin
We also provide pre-trained 81-frame model (Ground truth 2D pose as input) here. To evaluate it, put it into the ./checkpoint directory and run:
python run_poseformer.py -k gt -f 81 -c checkpoint --evaluate gt81f.bin
Training new models
-
To train a model from scratch (CPN detected 2D pose as input), run:
python run_poseformer.py -k cpn_ft_h36m_dbb -f 27 -lr 0.00004 -lrd 0.99
-f controls how many frames are used as input. 27 frames achieves 47.0 mm, 81 frames achieves achieves 44.3 mm.
-
To train a model from scratch (Ground truth 2D pose as input), run:
python run_poseformer.py -k gt -f 81 -lr 0.0004 -lrd 0.99
81 frames achieves 31.3 mm (MPJPE).
Visualization and other functions
We keep our code consistent with VideoPose3D. Please refer to their project page for further information.
Bibtex
If you find our work useful in your research, please consider citing:
@article{zheng20213d,
title={3D Human Pose Estimation with Spatial and Temporal Transformers},
author={Zheng, Ce and Zhu, Sijie and Mendieta, Matias and Yang, Taojiannan and Chen, Chen and Ding, Zhengming},
journal={Proceedings of the IEEE International Conference on Computer Vision (ICCV)},
year={2021}
}









