SMAC
ReDWeb-S: a large-scale challenging dataset for RGB-D Salient Object Detection.
Citing our work
If you think our work is helful, please cite
@misc{liu2020learning,
title={Learning Selective Mutual Attention and Contrast for RGB-D Saliency Detection},
author={Nian Liu and Ni Zhang and Ling Shao and Junwei Han},
year={2020},
eprint={2010.05537},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
The Proposed RGB-D Salient Object Detection Dataset
ReDWeb-S
We construct a new large-scale challenging dataset ReDWeb-S and it has totally 3179 images with various real-world scenes and high-quality depth maps. We split the dataset into a training set with 2179 RGB-D image pairs and a testing set with the remaining 1000 image pairs.
The proposed dataset link can be found here. [baidu pan fetch code: rp8b | Google drive]
Dataset Statistics and Comparisons
We analyze the proposed ReDWeb-S datset from several statistical aspects and also conduct a comparison between ReDWeb-S and other existing RGB-D SOD datasets.
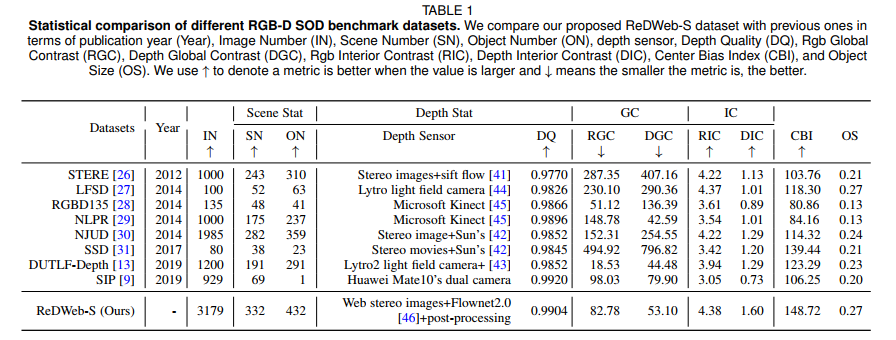
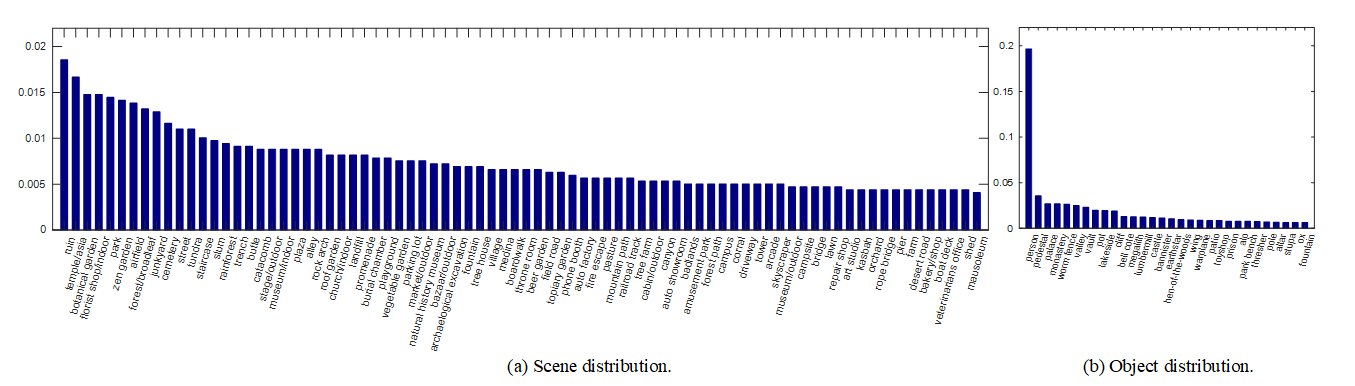
Fig.1. Top 60% scene and object category distributions of our proposed ReDWeb-S dataset.
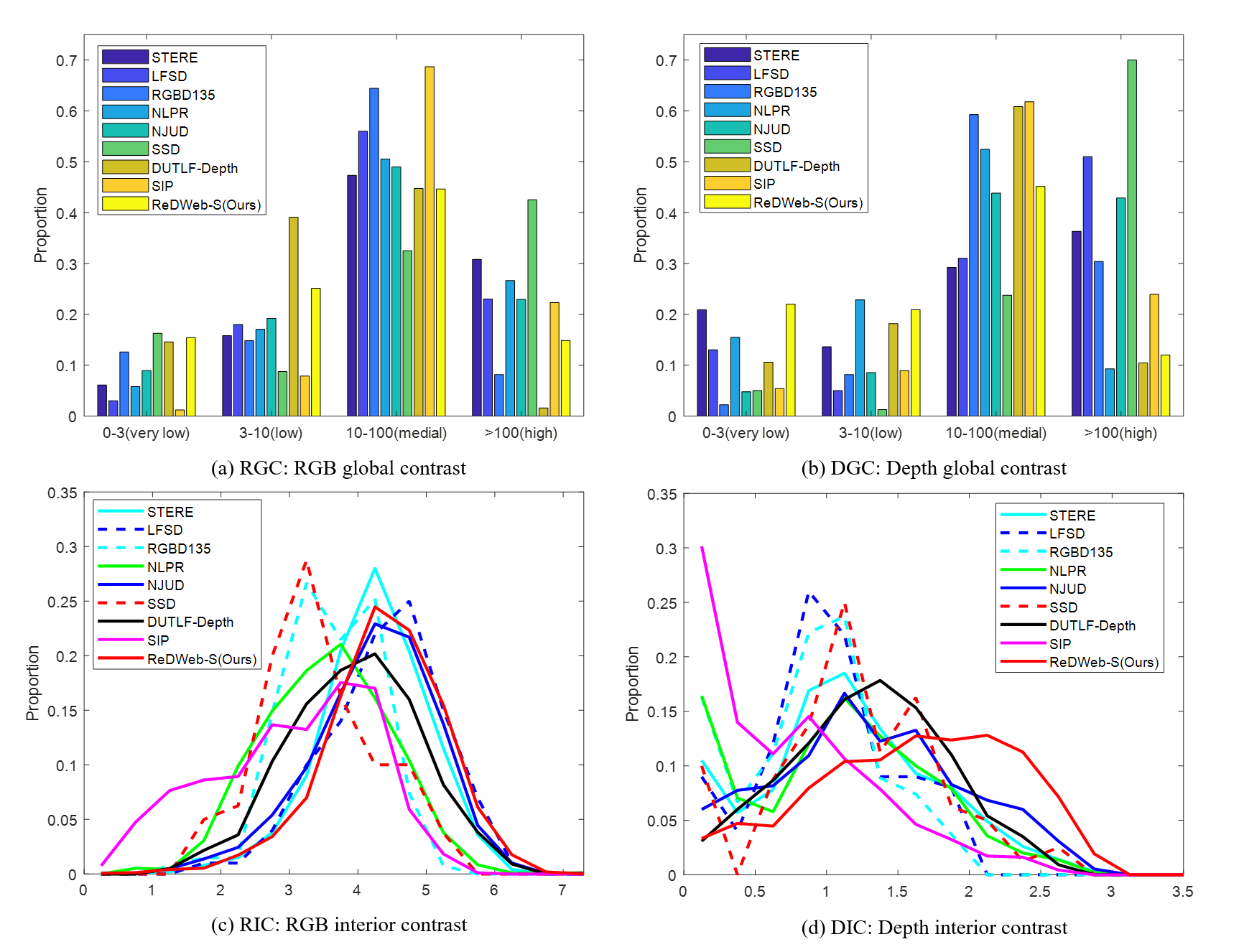
Fig.2. Comparison of nine RGB-D SOD dataset in terms of the distributions of global contrast and interior contrast.
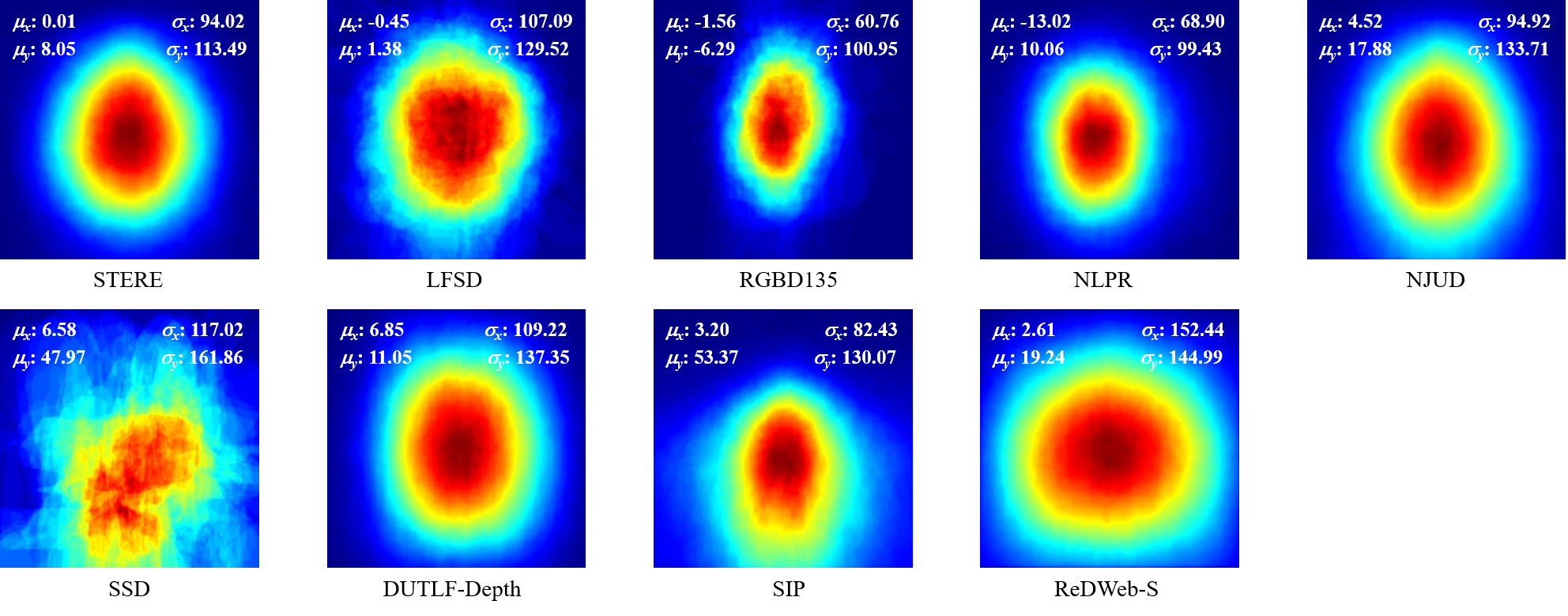
Fig.3. Comparsion of the average annotation maps for nine RGB-D SOD benchmark datasets.
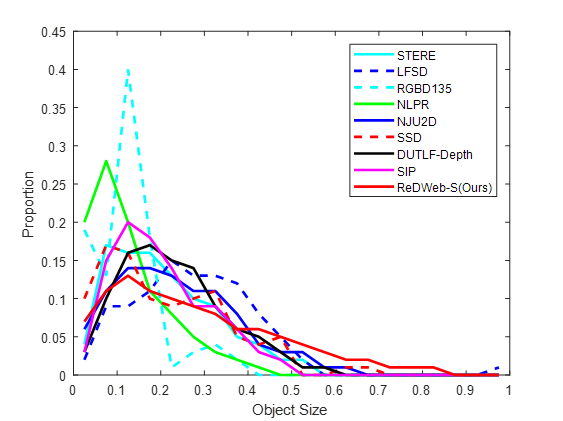
Fig.4. Comparsion of the distribution of object size for nine RGB-D SOD benchmark datasets.
SOTA Results on our proposed dataset
We provide other SOTA RGB-D methods' results and scores on our proposed dataset. You can directly download all results [here lfa6].
| No. | Pub. | Name | Title | Download |
|---|---|---|---|---|
| 01 | CVPR2020 | S2MA | Learning Selective Self-Mutual Attention for RGB-D Saliency Detection | results, g0pgx |
| 02 | CVPR2020 | JL-DCF | JL-DCF: Joint Learning and Densely-Cooperative Fusion Framework for RGB-D Salient Object Detection | results, xh9p |
| 03 | CVPR2020 | UCNet | UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders | results, 6o93 |
| 04 | CVPR2020 | A2dele | A2dele: Adaptive and Attentive Depth Distiller for Efficient RGB-D Salient Object Detection | results, swv5 |
| 05 | CVPR2020 | SSF-RGBD | Select, Supplement and Focus for RGB-D Saliency Detection | results, oshl |
| 06 | TIP2020 | DisenFusion | RGBD Salient Object Detection via Disentangled Cross-Modal Fusion | results, h3hc |
| 07 | TNNLS2020 | D3Net | D3Net:Rethinking RGB-D Salient Object Detection: Models, Datasets, and Large-Scale Benchmarks | results, tetn |
| 08 | ICCV2019 | DMRA | Depth-induced multi-scale recurrent attention network for saliency detection | results, kqq4 |
| 09 | CVPR2019 | CPFP | Depth-induced multi-scale recurrent attention network for saliency detection | results, 0v2c |
| 10 | TIP2019 | TANet | Three-stream attention-aware network for RGB-D salient object detection | results, hsy9 |
| 11 | CVPR2018 | PCF | Progressively Complementarity-Aware Fusion Network for RGB-D Salient Object Detection | results, qzhm |
| 12 | PR2019 | MMCI | Multi-modal fusion network with multiscale multi-path and cross-modal interactions for RGB-D salient object detection | results, c90m |
| 13 | TCyb2017 | CTMF | CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion | results, i0zb |
| 14 | Access2019 | AFNet | Adaptive fusion for rgb-d salient object detection | results, 54zc |
| 15 | TIP2017 | DF | Rgbd salient object detection via deep fusion | results, d7sc |
| 16 | ICME2016 | SE | Salient object detection for rgb-d image via saliency evolution | results, h10s |
| 17 | SPL2016 | DCMC | Saliency detection for stereoscopic images based on depth confidence analysis and multiple cues fusion | results, 18po |
| 18 | CVPR2016 | LBE | Local background enclosure for rgb-d salient object detection | results, iiz5 |
| Methods | S-measure | maxF | E-measure | MAE |
|---|---|---|---|---|
| S2MA | 0.711 | 0.696 | 0.781 | 0.139 |
| JL-DCF | 0.734 | 0.727 | 0.805 | 0.128 |
| UCNet | 0.713 | 0.71 | 0.794 | 0.13 |
| A2dele | 0.641 | 0.603 | 0.672 | 0.16 |
| SSF-RGBD | 0.595 | 0.558 | 0.71 | 0.189 |
| DisenFusion | 0.675 | 0.658 | 0.76 | 0.16 |
| D3Net | 0.689 | 0.673 | 0.768 | 0.149 |
| DMRA | 0.592 | 0.579 | 0.721 | 0.188 |
| CPFP | 0.685 | 0.645 | 0.744 | 0.142 |
| TANet | 0.656 | 0.623 | 0.741 | 0.165 |
| PCF | 0.655 | 0.627 | 0.743 | 0.166 |
| MMCI | 0.660 | 0.641 | 0.754 | 0.176 |
| CTMF | 0.641 | 0.607 | 0.739 | 0.204 |
| AFNet | 0.546 | 0.549 | 0.693 | 0.213 |
| DF | 0.595 | 0.579 | 0.683 | 0.233 |
| SE | 0.435 | 0.393 | 0.587 | 0.283 |
| DCMC | 0.427 | 0.348 | 0.549 | 0.313 |
| LBE | 0.637 | 0.629 | 0.73 | 0.253 |
Acknowledgement
We thank all annotators for helping us constructing the proposed dataset. Our proposed dataset is based on the ReDWeb dataset, which is a state-of-the-art dataset proposed for monocular image depth estimation. We also thank the authors for providing the ReDWeb dataset.



